


新闻动态
导读
周报内容均源自海内外主流媒体报道、高校官网等公开信息梳理、相关领域优质KOL原创深度,主要包括超算快讯、前沿应用、学术研究等。
本期超算&AI应用周报共3950字,预计阅读时间15分钟,您可以重点专注以下内容。
另外,文末有惊喜,我们为您准备了超算&AI应用知识库,可免费获得更多热门软件资源。
超算快讯:DL_POLY最新版本上线超算互联网,可免费下载使用
前沿应用:Stability AI开源上新;马斯克开源Grok;全球首个类Sora开源复现方案来了;DeepMind发布“AI足球助教”;谷歌发布“Vlogger”模型
学术研究:哈佛医学院发布迄今最大计算病理学基础模型;清华大学开发单细胞剪接谱分析工具、气体分离材料吸附性能高精度通用预测模型;AI击败最先进全球洪水预警系统
一、超算AI快讯:
超算互联网上线DL_POLY新版本,高性能分子动力学模拟升级
超算互联网现已上线DL_POLY v5.2.0 pre版本,可免费下载使用。
DL_POLY 是一款经典的分子动力学模拟软件,旨在在分布式内存并行计算机上促进大分子、聚合物、离子系统和溶液的分子动力学模拟,应用于化学、物理学、材料科学等领域,能够帮助科研工作者研究材料的微观结构演化、相变过程、扩散现象、力学性能以及化学反应动力学等问题。
DL_POLY v5.2.0 pre版本是DL_POLY_4的延续版本,后者基于域分解(DD)策略,更适合在大量处理器上进行从10^3到10^9个原子的大型分子模拟。
下载链接:
https://www.scnet.cn/ui/mall/detail/goods?type=software&common1=APP_SOFTWARE&id=1771049521219174401&resource=APP_SOFTWARE
超算互联网支持Multiwfnv3.8版本免费下载使用
Multiwfn是一个功能强大的量子化学波函数分析程序,由北京科音自然科学研究中心主任卢天编写,支持几乎所有的波函数分析方法,并具有易学易用、高效率、灵活、开源免费等优点。Multiwfn3.8版本已上线超算互联网,可免费下载使用。
Multiwfn的主要功能包括:
支持多种格式作为波函数的输入,包括.wfn、.wfx、.fch文件和Molden输入文件等。
提供基本功能,如显示分子结构、分子轨道及格点数据的等值面图形;输出某条线上的全部特性并绘制曲线图;输出某个面上的全部特性并绘图;输出某一空间范围的特性并绘制等值线图等。
提供电子密度及其拉普拉斯函数以及ELF/LOL等函数的拓扑分析;波函数检查与修改;布居分析;轨道成分分析;键级分析等。
提供绘制总DOS/部分DOS/重叠DOS;绘制红外/拉曼/紫外可见/电子圆二色/振动圆二色光谱;分析处理格点文件;定量分子表面分析,且支持Hirshfeld/Becke surface分析;适应性自然密度划分 ;模糊空间分析;电荷分解分析及绘制轨道相互作用图等。
下载链接:
https://www.scnet.cn/ui/mall/detail/goods?type=software&common1=APP_SOFTWARE&id=1771052997240225793&resource=APP_SOFTWARE
二、前沿应用:
Stability AI开源上新:3D生成引入视频扩散模型,质量一致性up
3月18日,Stable Diffusion背后公司Stability AI带来了图生3D方面的新进展,推出一款名为Stable Video 3D(SV3D)的视频扩散模型,只用一张图片就能生成高质量3D网格。

Stable Video 3D 的关键特性和优势如下:
质量和多视角改进:与早期的 Stable Zero123 模型相比,SV3D大大提高了3D生成的质量和视图一致性。
模型变体:发布包括两个模型变体:SV3D_u:该变体基于单张图片输入生成轨道视频,无需相机条件控制。SV3D_p:该变体扩展了 SV3D_u 的能力,可以同时处理单张图片和轨道视图。这允许沿指定的相机路径创建 3D 视频。
视频扩散的优势:与 Stable Zero123 使用的图像扩散模型相比,使用视频扩散模型在生成输出的泛化性和视角一致性方面提供了显著的优势。Stable Video 3D 利用这一能力生成对象的多视角视频。
3D 优化:模型引入了改进的 3D 优化技术,包括解耦照明优化和新的掩蔽分数蒸馏采样损失函数。这些技术使 Stable Video 3D 能够从单张图片输入可靠地输出高质量的 3D 网格。
商业和非商业用途:模型权重依然开源,不过仅可用于非商业用途,想要商用的话还得买个Stability AI会员。
内容链接:
https://stability.ai/news/introducing-stable-video-3d
马斯克开源Grok:3140亿参数巨无霸,免费可商用
2024年3月18日,马斯克说到做到,正式对Grok大模型进行开源。根据开源信息显示:Grok模型的Transformer达到64层,大小为314B;用户可以将Grok用于商业用途(免费),并且进行修改和分发,并没有附加条款。

Grok 的参数细节:
模型概况:拥有3140亿个参数,成为目前参数量最大的开源模型,是Llama 2的4倍。Grok-1 是一个基于 Transformer 的自回归模型。xAI 利用来自人类和早期 Grok-0 模型的大量反馈对模型进行了微调。
特点:模型采用了混合专家架构,共有8个专家模型,其中每个数据单元(Token)由2位专家处理。这使得每次对Token的处理会涉及860亿激活参数,比目前开源的最大模型Llama-2 70B的总参数量还多。模型支持8bit精度量化,可能需要8块H100。
缺陷:Grok-1 语言模型不具备独立搜索网络的能力。在 Grok 中部署搜索工具和数据库可以增强模型的能力和真实性。尽管可以访问外部信息源,但模型仍会产生幻觉。
训练数据:Grok-1 发布版本所使用的训练数据来自截至 2023 年第三季度的互联网数据和 xAI 的 AI 训练师提供的数据。(腾讯科技)
内容链接:
https://mp.weixin.qq.com/s/FhjSwjKEnD7f8qbftoFQTw
全球首个类Sora开源复现方案来了
全球首个开源的类Sora架构视频生成模型Open-Sora 1.0,来了!整个训练流程,包括数据处理、所有训练细节和模型权重,全部开放。
它带来的实际效果如下,能生成繁华都市夜景中的车水马龙。

还能用航拍视角,展现悬崖海岸边,海水拍打着岩石的画面。

自Sora发布以来,由于效果惊艳但技术细节寥寥,揭秘、复现Sora成为了开发社区最热议话题之一。比如Colossal-AI团队推出成本直降46%的Sora训练推理复现流程。
短短两周时间后,该团队再次发布最新进展,复现类Sora方案,并将技术方案及详细上手教程在GitHub上免费开源。
开源链接:
https://github.com/hpcaitech/Open-Sora
DeepMind发布“AI足球助教”,战术制定胜过人类教练
3月19日,由 Google DeepMind、利物浦足球俱乐部及其合作者提出的一个名为 TacticAI 的“AI 足球助教”,以 90% 的胜率,登上了 Nature 子刊 Nature Communications。
该系统利用预测和生成模型,在角球战术设计上取得了重大突破。通过几何深度学习技术,TacticAI能够处理稀缺的高质量角球数据,创造出高度可推广且精准的预测模型,从而为教练团队提供有关角球战术的关键见解和优化建议。

TacticAI要点如下:
解决核心问题:该系统旨在解答三个关键问题:预测给定角球战术设置下的可能结果、理解过去类似策略的效果以及指导如何调整策略以实现特定目标。
几何深度学习技术:通过将角球场景转换为图形表示,并利用图神经网络及群等变卷积网络技术处理球员间的关系和动态,TacticAI能够在有限的高质量角球数据下构建出更具有推广性的模型,从而准确预测角球接球手、射门尝试等情况。
辅助教练决策:TacticAI能为教练提供即时且实用的战术建议,比如重新布置球员位置以改善角球战术。通过其生成模型,教练可以快速评估不同球员设置对战术效果的影响。(Google)
内容链接:
https://deepmind.google/discover/blog/tacticai-ai-assistant-for-football-tactics/
谷歌发布“Vlogger”模型:单张图片生成10秒视频
谷歌发布了一个新的视频框架:只需要一张你的头像、一段讲话录音,就能得到一个本人栩栩如生的演讲视频。
视频时长可变,目前看到的示例最高为10s。可以看到,无论是口型还是面部表情,它都非常自然。如果输入图像囊括整个上半身,它也能配合丰富的手势:

这个框架名叫VLOGGER。它主要基于扩散模型,并包含两部分:
一个是随机的人体到3D运动(human-to-3d-motion)扩散模型。
另一个是用于增强文本到图像模型的新扩散架构。
其中,前者负责将音频波形作为输入,生成人物的身体控制动作,包括眼神、表情和手势、身体整体姿势等等。
后者则是一个时间维度的图像到图像模型,用于扩展大型图像扩散模型,使用刚刚预测的动作来生成相应的帧。(量子位)
内容链接:
https://mp.weixin.qq.com/s/LMcrvQkiYaEoljbM2v6vzQ
三、学术研究:
登Nature子刊,哈佛医学院发布迄今最大计算病理学基础模型
在计算病理学 (CPath) 中,基础模型在提高诊断准确性、预后以及预测治疗反应方面发挥着关键作用。
近日,美国麻省总医院(Massachusetts General Hospital)、哈佛医学院等组成研究团队设计了迄今为止最大的两个 CPath 基础模型:UNI 和 CONCH。这些基础模型适用于 30 多种临床和诊断需求,包括疾病检测、疾病诊断、器官移植评估和罕见疾病分析。

新模型克服了当前模型的局限性,不仅在研究人员测试的临床任务中表现良好,而且在识别新的、罕见的和具有挑战性的疾病方面也显示出了前景。UNI 和 CONCH 的相关论文发表在《Nature Medicine》上。(ScienceAI)
论文链接:
https://www.nature.com/articles/s41591-024-02857-3
清华大学杨雪瑞课题组开发单细胞剪接谱分析工具
3月19日消息,清华大学生命学院杨雪瑞副教授课题组开发了生物信息工具SCASL(single-cell clustering based on alternative splicing landscapes),用于单细胞RNA剪接谱异质性的系统、定量分析,基于剪接谱重新定义细胞亚群。
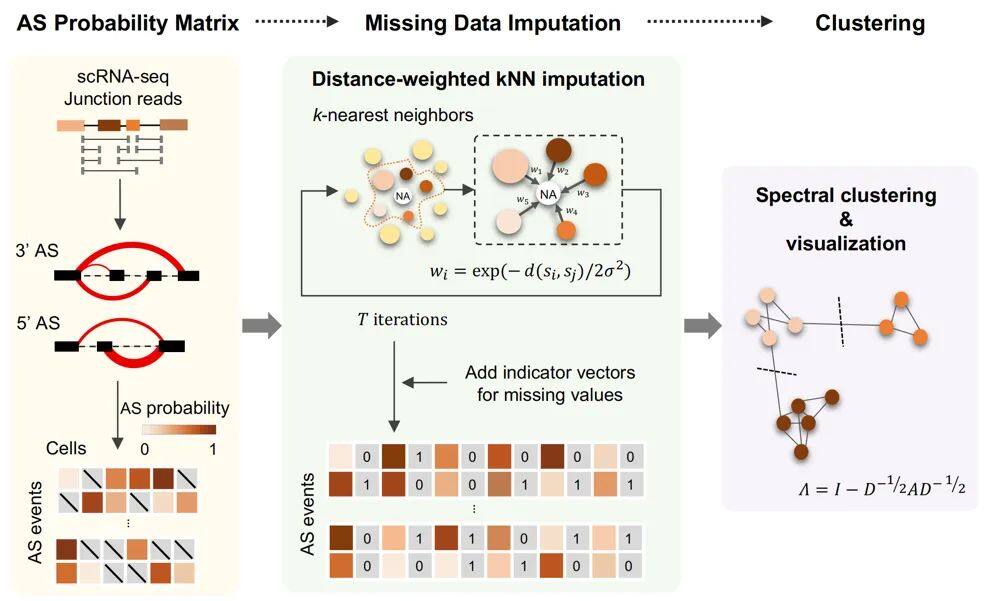
图1.SCASL分析流程概念示意图
SCASL方法使用单细胞RNA测序数据,在不依赖于转录组注释的前提下,对不同的可变剪接模式进行定量。以此为基础,SCASL通过kNN插补,重点解决了单细胞RNA剪接数据的低覆盖度与高稀疏性问题,最后使用谱聚类方法对细胞亚型进行了无监督分类,绘制单细胞RNA剪接异质性图谱。
该研究为复杂组织中细胞异质性的解读提出了新的视角与方法。通过这一技术的应用,研究深入分析了多个重要的生物学过程,提出一系列新观察、新线索与新发现。(清华大学)
论文链接:
https://www.nature.com/articles/s41467-024-46480-9
清华团队合作研发出气体分离材料吸附性能高精度通用预测模型
近日,清华大学化工系卢滇楠教授团队联合美国加州大学河滨分校吴建中教授和北京科学智能研究院高志锋研究员研发出三维MOF材料吸附行为的机器学习模型Uni-MOF,用于预测各类工况下纳米多孔材料对各类气体的吸附性能。
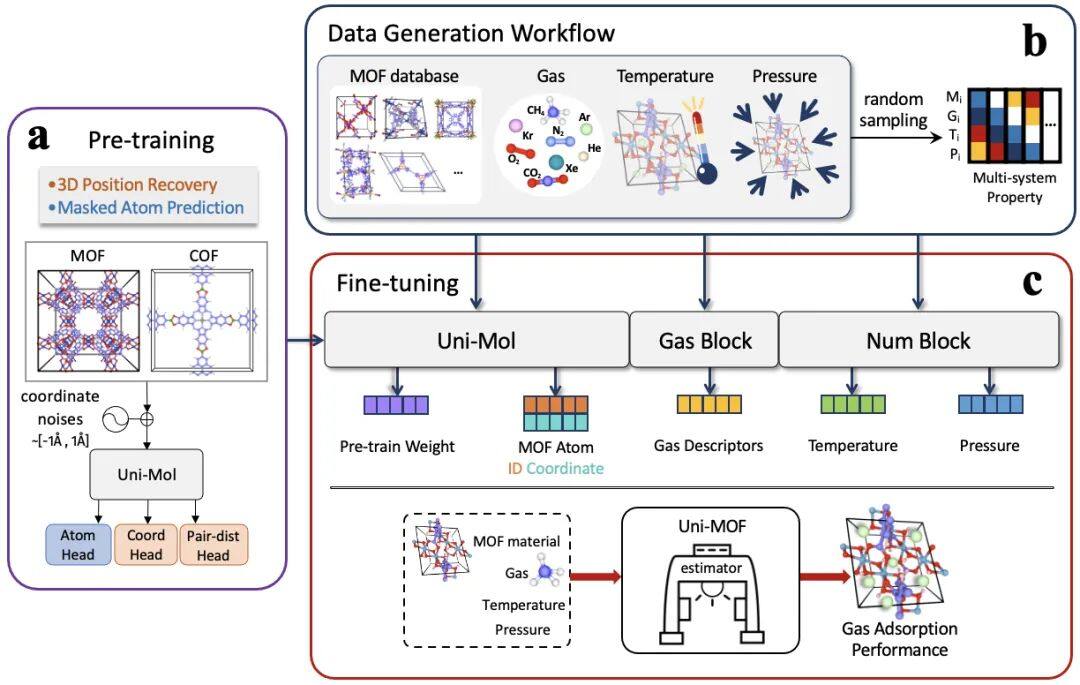
图1.Uni-MOF框架示意图。(a)预训练阶段,(b)数据生成工作流,(c)微调阶段
在模型的预训练阶段,研究者实施了两类任务以提升模型性能。第一类任务为预测被遮蔽原子的类型,即识别并预测在分子结构中被掩盖部分的原子种类。第二类任务为执行噪声下的三维坐标恢复任务,具体操作为在15%的原子坐标上引入范围在[-1Å,+1Å]之间的均匀噪声,进而基于这些受损坐标来计算空间位置编码。这两类任务旨在增进模型对数据的抗干扰能力,从而在面对后续的预测任务时,提供更加精准的性能。(清华大学)
论文链接:
https://www.nature.com/articles/s41467-024-46276-x
AI击败最先进全球洪水预警系统,提前7天预测河流洪水
近年来,人类造成的气候变化进一步增加了一些地区的洪水频率。然而,目前的预报方法主要依赖沿河而建的观测站,其在全球的分布并不均匀,这就导致未经测量的河流更难预报,其负面影响主要体现在发展中国家。升级预警系统,使这些人群能够获得准确、及时的信息,每年可以挽救数千人的生命。
来自 Google Research 洪水预测团队的 Grey Nearing 及其同事开发的人工智能模型,通过利用现有的 5680 个测量仪进行训练,可预测未测量流域在 7 天预测期内的日径流。
他们将该人工智能模型与全球领先的短期和长期洪水预测软件——全球洪水预警系统(GloFAS)进行了对比测试。结果显示,该模型同日预测准确率与当前系统相当甚至更高。
此外,该模型在预测重现窗口(return window)期为五年的极端天气事件时,其准确性与 GloFAS 预测重现窗口期为一年的事件时的准确性相当或更高。(学术头条)
论文链接:
https://www.nature.com/articles/s41586-024-07145-1

相关新闻
-
2025-04-18
超算&AI应用周报Vol.53 | 智谱6款GLM模型、Skywork-OR1、InternVL3、HiDream-I1上线
-
2025-04-18
机器化学家:算力=智力=研究力
-
2025-04-17
最佳实践Vol.35 | Wan2.1-ComfyUI实操:玩转AI视频,让文字、图片一键动起来
-
2025-04-17
科研更“晋”一步 - 国家超算互联网生态沙龙在太原顺利开展
-
2025-04-16
智谱GLM开源模型系列上线,32B性能比肩DeepSeek-R1

 津公网安备12011602300273号
津公网安备12011602300273号
 电子营业执照
电子营业执照