


新闻动态
导读
周报内容均源自海内外主流媒体报道、高校官网等公开信息梳理、相关领域优质KOL原创深度,主要包括超算快讯、前沿应用、学术研究等。
本期超算&AI应用周报共4594字,预计阅读时间18分钟,您可以重点专注以下内容。
另外,文末有惊喜,我们为您准备了超算&AI应用知识库,可免费获得更多热门软件资源。
超算快讯:LLaMA-2-7B、Gemma 系列模型上线超算互联网,轻松部署大模型
前沿应用:Meta震撼发布Llama 3;Reka Core:挑战GPT-4、Claude 3;Grok-1.5V:多模态连接数字与物理世界;北大字节开辟图像生成新范式:从预测下一个token到预测下一级分辨率;
学术研究:Mini-Gemini:对标GPT-4与DALLE-3的王炸组合;重庆医科大学沈伟等发布全能序列处理工具SeqKit2;药物分子设计新策略,微软条件扩散模型DiffLinker;SyntheMol:生成式AI直面超级细菌耐药挑战

一、超算快讯:
Gemma 系列模型上线超算互联网,轻松部署大模型
日前,Google 推出的最新开源大语言模型Gemma已上线超算互联网,提供预训练基础版本2B/7B和经过指令优化的2B-IT/7B-IT版本的四个模型。
为了方便开发者,谷歌还附带开发套装,包括全新的“负责任生成式AI工具包”,为基于Gemma开发安全的人工智能应用程序提供了必要指导和工具,以及跨主流框架(如JAX、PyTorch及原生Keras 3.0下的TensorFlow)的推理和监督微调(SFT)工具链。

您可以通过下方商品链接或登录超算互联网搜索关键词“Gemma”,轻松部署大模型。
商品链接:
https://www.scnet.cn/ui/mall/search/goods?keyword=Gemma
LLaMA-2-7B上线超算互联网,可快速搭建开发环境
Meta 发布的 Llama 2,是新的 SOTA 开源大型语言模型(LLM)。Llama 2 有 3 种不同的大小——7B、13B 和 70B 个可训练参数。与原版 LLaMA 相比,新的改进包括:
模型训练:在 2 万亿个标记的文本数据上进行训练,预训练语料库的大小增加了 40%,将模型的上下文长度增加了一倍至 4k;
模型推理:70B 模型采用了分组查询注意力(GQA),可以提高推理速度;
性能:Llama 2 不论是在数据质量、训练技术、性能评估、安全训练等方面都进行了实质性的技术扩展;
许可:该模型可用于商业用途,除非你的产品月活用户数 >= 7 亿,需要填写表格以获取访问权限。
LLaMA-2-7B模型现已上线超算互联网,您可以通过下方商品链接或登录超算互联网搜索关键词“LLaMA-2”,使用模型搭建开发环境,进行训练与推理。
商品链接:
https://www.scnet.cn/ui/mall/detail/goods?type=software&common1=DATA&id=1778622963123589122&resource=DATA
CESM v2.2.1版本上线超算互联网
CESM(Community Earth System Model)是一个完全耦合的全球气候模型,可用于地球过去、现在和未来气候状态的模拟。
CESM的核心组件包括大气模式(CAM)、海洋模式(POP)、陆地模式(CLM)和海冰模式(CICE),这些组件可以单独运行,也可以耦合在一起进行全球地球系统模拟。
研究人员可以通过下方商品链接或登录超算互联网搜索关键词“CESMv2.2.1”,利用CESM进行多种类型的模拟实验,如气候变化情景下的模拟、极端气候事件的研究、海洋生态系统的模拟等,加快模拟速度和提高模拟精度。
商品链接:
https://www.scnet.cn/ui/mall/detail/goods?type=software&common1=APP_SOFTWARE&id=1780415579207737345&resource=APP_SOFTWARE
二、前沿应用:
Meta震撼发布Llama 3,一夜重回开源大模型铁王座
当地时间4月18日,Meta 发布两款开源Llama 3 8B与Llama 3 70B模型,供外部开发者免费使用。Llama 3的这两个版本,也将很快上线超算互联网。

本次发布的 8B 和 70B 参数大模型,提供了新功能,改进了推理能力,在行业基准测试上展示了最先进的性能。8B参数评测结果碾压 Gemma-7B、Mistral-7B 版本;而 Llama 3 70B 版本评测结果同样也在诸多成绩上超过了 Gemini 1.5 Pro 和 Claude 3 Sonnet。
具体来说,Llama 3的亮点和特性概括如下:
基于超过15T token训练数据,大小相当于Llama 2数据集的7倍还多,增强了推理、代码生成和指令跟随等方面的能力;
支持8K长文本(之前是4k),改进的tokenizer具有128K token的词汇量,可实现更好的性能;
采用分组查询注意力(grouped query attention,GQA)、掩码等技术,帮助开发者以最低的能耗获取绝佳的性能;
安全性有重大突破,带有Llama Guard 2、Code Shield 和 CyberSec Eval 2的新版信任和安全工具,还能够比Llama 2有更好“错误拒绝表现”。
内容链接:https://llama.meta.com/llama3/
Reka Core:挑战GPT-4、Claude 3
近日,Reka公司近期发布了其最新多模态语言模型Reka Core,该模型被描述为公司至今“最大、最有能力”,性能与GPT-4和Claude 3 Opus相当。
Core是Reka语言模型系列中的第三个成员,由多个来源训练而成,包括公开数据、授权数据以及涵盖文本、音频、视频和图像文件的合成数据。它能够理解图像、音频和视频等多种模式的数据内容。

Reka Core的主要特点如下:
大容量上下文窗口:支持高达128,000个token的上下文窗口,尤其擅长处理长篇文档,提供更丰富、精准的上下文信息提取与利用。
多语言支持:预训练涵盖了32种不同的语言,确保对多种语言(包括英语、多种亚洲和欧洲语言)的流畅处理和高水平表现。
高效训练与优化:使用数千台H100进行大规模训练,结合高学习率、强正则化、SFT和RLHF等后训练技术,确保模型性能优化和对齐。
基准测试成绩:在多个关键评估指标中,Reka Core与OpenAI、Anthropic和谷歌的顶级模型竞争激烈,部分基准测试中甚至超越GPT-4。
灵活部署:支持API、本地或设备部署,适应不同客户和合作伙伴的部署需求(新智元)
内容链接:
https://mp.weixin.qq.com/s/mBUTDcYGrtAd-Ng2bHz1iQ
Grok-1.5V:多模态连接数字与物理世界
4月12日,特斯拉创始人马斯克发布了多模态模型Grok-1.5V,该模型在多个领域的推理能力可与顶尖多模态模型相媲美,尤其在理解物理世界方面表现卓越。通过RealWorldQA基准测试,Grok的表现超越同类模型,显示出其在处理现实世界问题上的潜力。

Grok-1.5V的主要特点如下:
多模态处理能力:Grok-1.5V不仅具备文本处理能力,还能够处理包括文档、图标、屏幕截图和照片等多种视觉信息,实现了数字世界与物理世界的连接;
物理世界理解能力:在RealWorldQA基准测试中,Grok-1.5V在无思维链提示、零样本设置的条件下,表现出了比同类模型更好的性能,证明其对于物理世界的理解有着显著的优势;
跨领域推理能力:无论是多学科推理,还是文档理解、科学图表、表格等多个领域,Grok-1.5V都能展现出强大的处理能力,与当前顶尖的多模态模型相匹敌;
自动驾驶应用:通过使用语言进行“思维链”,帮助汽车分解复杂场景,Grok-1.5V有潜力解决自动驾驶中的边缘案例,提升自动驾驶系统的安全性和可靠性;
数据驱动的优化能力:特斯拉的高度成熟的数据管线使得Grok-1.5V能够通过大量带有高质量人类解释痕迹的数据进行微调,从而进一步提升其在多模态FSD推理上的表现。
内容链接:https://x.ai/blog/grok-1.5v
北大字节开辟图像生成新范式:从预测下一个token到预测下一级分辨率
北大和字节联手提出图像生成新范式,从预测下一个token变成预测下一级分辨率,效果超越Sora核心组件Diffusion Transformer(DiT)。
实验数据上,这个名为VAR(Visual Autoregressive Modeling)的新方法不仅图像生成质量超过DiT等传统SOTA,推理速度也提高了20+倍。
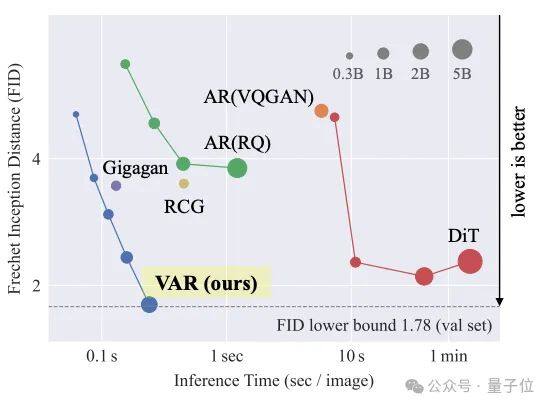
这也是自回归模型首次在图像生成领域击败DiT。
VAR的训练分为两个阶段:
第一阶段,VAR引入了多尺度离散表示,使用VQ-VAE将连续图像编码为一系列离散的token map,每个token map有不同的分辨率。
第二阶段,主要是对VAR Transformer的训练,通过预测更高分辨率的图像,来进一步优化模型。(量子位)
论文链接:https://arxiv.org/abs/2404.02905
三、学术研究:
Mini-Gemini:对标GPT-4与DALLE-3的王炸组合
刷爆多模态任务榜单。近日,香港中文大学贾佳亚教授团队研发了一款开源多模态模型——Mini-Gemini ,集成了高清图像理解、高质量训练数据、强大图像推理与生成能力,被誉为开源界的“GPT4+DALLE3”王炸组合。
Mini-Gemini背后的技术核心是通过视觉双分支(Gemini)进行信息挖掘,利用低分辨率的ViT作为Query,结合卷积网络将高分辨率图像编码为Key和Value,运用Transformer的Attention机制提高对高清图像的响应。高分辨率分支卷积网络支持自适应分辨率调整,使模型更具灵活性。在图像生成环节,Mini-Gemini 结合 SDXL 和 LLM 推理生成文本,类似于DALLE3的流程。
Mini-Gemini亮点包括:
高清图像处理:突破传统多模态模型对低分辨率图像的限制,精准解析高清图像,如指导面包制作、对比电脑配置,还能识别并解释图像中的矛盾点(如冰川中的仙人掌),生成具有深度解读和超现实效果的新图像。

图像生成与推理:在保持强大图像理解与推理能力的同时,集成图像生成功能,如同ChatGPT与生成模型的结合。模型能识别输入素材(如毛线团),给出合理建议并生成对应实体(如毛线玩具),还能根据抽象指令推理并生成符合情境的图像。
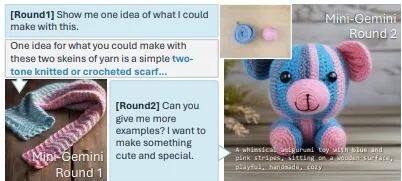
多轮对话与故事生成:支持多轮对话中构建连贯的图像故事,确保图片与文字叙述一致,满足用户定制化需求,如按用户要求讲述贵族小老鼠的故事。
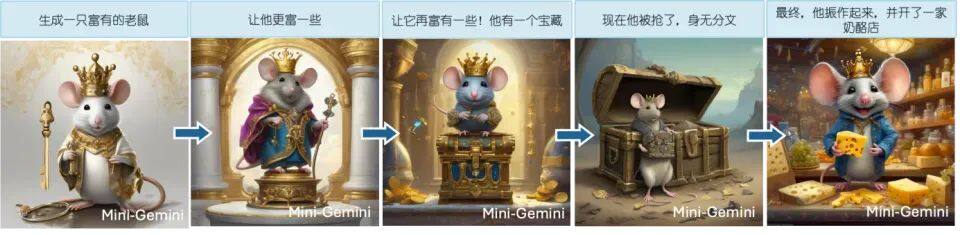
传统图像理解与应用:擅长理解曲线图等复杂图像的数学意义并复现,准确识别梗图笑点,以及对多图表进行高效分析。

论文链接:https://arxiv.org/pdf/2403.18814.pdf
重庆医科大学沈伟等发布全能序列处理工具SeqKit2
近期,重庆医科大学附属第二医院沈伟在iMeta在线发表研究文章,发布了已被广泛使用的序列分析工具SeqKit新的版本SeqKit2。

SeqKit2重要更新与核心亮点:
功能丰富:子命令数量从19个增加至38个,涵盖8个类别,新增了大量分析功能,如扩增子测序数据分析、FASTQ数据修复以及实时分析子命令。
支持压缩格式:新增对XZ、Zstandard和Bzip2三种压缩文件格式的支持,提高了对多种压缩FASTA/Q文件的处理能力。
性能优化:SeqKit2在速度、内存效率和处理大规模数据的能力上均有显著提升,且在基准测试中表现优于先前版本及同类工具如Bioawk、Seqtk、SeqFu等。
用户体验改进:引入自动补全、进度条显示、增强的错误处理等新特性,提高了易用性和用户友好性。
论文链接:https://doi.org/10.1002/imt2.191
药物分子设计新策略,微软条件扩散模型DiffLinker登Nature子刊
药理学相关分子空间巨大(>10^60),基于片段的药物设计(FBDD)是有效的早期药物开发策略,但面临如何合理设计连接分子片段间linker的难题。
对此,来自微软研究院科学智能中心(AI4Science)、洛桑联邦理工学院、牛津大学和 MIT 的研究团队,提出了一种用于分子 linker 设计的 E(3) 等变三维条件扩散模型 DiffLinker。
DiffLinker模型亮点:

分子linker生成过程概述
创新性:DiffLinker能够连接任意数量的分子片段,自动确定linker的原子数及其与输入片段的连接点。
工作原理:模型首先生成linker大小,然后从正态分布中采样初始原子类型和位置,利用输入片段条件的神经网络迭代更新连接原子信息,最终生成完整的linker分子。
优势:与传统方法相比,DiffLinker具有E(3)等变性、不受片段数量限制、无需预先定义linker大小、能生成多样化且可合成的分子等优点。
相关研究以《Equivariant 3D-conditional diffusion model for molecular linker design为题发布在《Nature Machine Intelligence上。
论文链接:
https://www.nature.com/articles/s42256-024-00815-9
SyntheMol:生成式AI直面超级细菌耐药挑战
近期,斯坦福大学和麦克马斯特大学的研究人员联合开发了一款名为“SyntheMol”的生成式AI模型,旨在从近300亿个分子的化学空间中快速设计出易于合成且具有新颖结构的抗生素。
该模型能在短时间内从海量化学物质中设计出易于合成且具有创新结构的抗生素候选分子,并提供详细的合成步骤。研究团队利用13万余个分子片段和验证过的化学反应,识别出300亿个片段组合,从而设计出针对鲍曼不动杆菌等细菌具有广谱抗菌性的新分子。9小时内,SyntheMol生成了约2.5万种潜在抗生素及其化学配方。

图 | SyntheMol(来源:Nature Machine Intelligence)
实验中,团队成功合成并测试了58种SyntheMol设计的分子,其中有6种能有效杀灭鲍曼不动杆菌的耐药菌株,并对多种其他病原菌如大肠杆菌、肺炎克雷伯菌等表现出抗菌活性。尽管4种新分子存在水溶性问题,但其中2种在小鼠体内显示安全,后续将在鲍曼不动杆菌感染小鼠模型中验证疗效。
内容链接:
https://med.stanford.edu/news/all-news/2024/03/ai-drug-development.html

相关新闻
-
2025-04-18
超算&AI应用周报Vol.53 | 智谱6款GLM模型、Skywork-OR1、InternVL3、HiDream-I1上线
-
2025-04-18
机器化学家:算力=智力=研究力
-
2025-04-17
最佳实践Vol.35 | Wan2.1-ComfyUI实操:玩转AI视频,让文字、图片一键动起来
-
2025-04-17
科研更“晋”一步 - 国家超算互联网生态沙龙在太原顺利开展
-
2025-04-16
智谱GLM开源模型系列上线,32B性能比肩DeepSeek-R1

 津公网安备12011602300273号
津公网安备12011602300273号
 电子营业执照
电子营业执照