


新闻动态
导读
周报内容均源自海内外主流媒体报道、高校官网等公开信息梳理、相关领域优质KOL原创深度,主要包括超算快讯、前沿应用、学术研究等。
本期超算&AI应用周报共4584字,预计阅读时间15分钟,您可以重点专注以下内容。
超算快讯:国产开源MoE模型DeepSeek-V2、马斯克开源AI大模型Grok-1、通义千问视觉语言系列模型Qwen-VL、开源SQL生成大模型SQLCoder系列上线超算互联网
前沿应用:AlphaFold 3 登上 Nature;LeCun漫画背后的StoryDiffusion技术;谷歌推出多模态医学大模型 Med-Gemini
学术研究:斯坦福升级20亿参数端侧AI模型;Sora视频生成器迎来超现实升级

一、超算AI快讯:
国产开源MoE模型DeepSeek-V2上线超算互联网,百万Token仅1元
本周,超算互联网上线国产开源MoE模型DeepSeek-V2,在目前大模型主流榜单中,DeepSeek-V2均表现出色:
中文综合能力(AlignBench)开源模型中最强,与GPT-4-Turbo,文心4.0等闭源模型在评测中处于同一梯队;
英文综合能力(MT-Bench)与最强的开源模型LLaMA3-70B同处第一梯队,超过最强MoE开源模型Mixtral 8x22B;
知识、数学、推理、编程等榜单结果也位居前列;
在价格方面,DeepSeek-V2 API 的定价为每百万 token 输入 0.14 美元(约 1 元人民币)、输出 0.28 美元(约 2 元人民币,32K 上下文),价格仅为GPT-4-Turbo 的近百分之一。
此外,超算互联网也同步上线了多模态大模型DeepSeek-VL系列,包括两个版本:DeepSeek-VL-7B-base、DeepSeek-VL-7B-chat。
DeepSeek全系列模型支持开源和商业免费使用,开发者可扫码下方二维码,或登录超算互联网搜索“DeepSeek”,支持一键试用。

马斯克开源AI大模型Grok-1上线超算互联网,支持下载开发部署
超算互联网上线由马斯克旗下的人工智能初创公司xAI开发的大型语言模型Grok-1。开发者可扫码下方二维码,或登录超算互联网搜索“Grok-1”,支持下载开发部署与推理。
该模型的主要亮点包括:
混合专家模型(MoE):Grok-1采用了混合专家系统的设计,将多个专家网络结合,提高模型效率和性能。在Grok-1中,每个token从8个专家中选择2个进行处理。
激活参数数量:314B参数的MoE,活跃参数规模86B,表明其在处理语言任务时的潜在能力。
工程架构:Grok另辟蹊径——没有采用常见的Python、PyTorch或Tensorflow,而是选用了Rust编程语言以及深度学习框架新秀JAX。
开源与Apache 2.0许可:xAI遵循开源理念,遵守的是Apache-2.0许可证,用户可以自由使用、修改和分发软件。

通义千问视觉语言系列模型Qwen-VL上线超算互联网,开源可商用
本周,超算互联网上线Qwen-VL系列模型,包括两个版本:Qwen-VL和Qwen-VL-Chat。Qwen-VL是一个预训练模型,通过连接一个视觉编码器来扩展了Qwen-7B语言模型,使其具备了理解和感知视觉信号的能力。Qwen-VL-Chat则是基于Qwen-VL的交互式视觉-语言模型,通过对齐机制支持更灵活的交互,如多图像输入、多轮对话和定位能力。
Qwen-VL系列模型的特点包括:
多模态处理能力:Qwen-VL的核心是一个基于Transformer的多模态预训练模型,能够同时理解和处理文本与图像信息。
高性能表现:在多个评估基准(包括零样本图像描述、视觉问答、文档视觉问答和定位)上,明显优于现有的开源大型视觉-语言模型(LVLMs)。
多图像交织对话:这个特性允许输入和比较多个图像,以及指定与图像相关的问题,并进行多图像叙述。
精细化的识别和理解:相对于其他开源LVLM目前使用的224×224分辨率,448×448分辨率可以促进对细节的文本识别、文档问答和边界框检测。
开发者可扫码下方二维码,或登录超算互联网搜索“Qwen-VL”,支持一键试用。

开源SQL生成大模型SQLCoder系列上线超算互联网
SQLCoder是DefogAI团队推出的一款基于StarCoder微调的、针对SQL优化的大模型。超算互联网现已上线包括SQLCoder2、SQLCoder-7B、SQLCoder-7B-2、SQLCoder系列模型。
StarCoder的主要特点如下:
性能优越:在 SQL 生成任务的评估框架上,SQLCoder(64.6%)的性能略微超过了 gpt-3.5-turbo(60.6%)。
训练数据质量高:Defog 在两个周期内对10,537个人工策划的问题进行了训练,这些问题基于10种不同的模式。
易于集成与使用:用户可以通过超算互联网下载SQLCoder的模型权重,模型附带了示例代码和文档,便于在不同的数据库架构上进行部署和推理。
免费商用授权:DefogAI团队决定将SQLCoder作为开源项目发布,并提供免费的商用授权,降低了企业和个人用户的使用门槛。
开发者可扫码下方二维码,或登录超算互联网搜索“SQLCoder”,支持一键试用。

二、前沿应用:
AlphaFold 3 登上 Nature:所有生命分子的结构和相互作用,都被 AI 预测了
新一代 AlphaFold——由 Google DeepMind 和 Isomorphic Labs研究团队推出的革命性人工智能(AI)模型 AlphaFold 3——登上了权威科学期刊 Nature。
该模型的主要亮点包括:
大幅提升的预测准确性:AlphaFold 3 以前所未有的精确度成功预测了所有生命分子(蛋白质、DNA、RNA、配体等)的结构和相互作用。与现有预测方法相比,AlphaFold 3改进了至少50%;对于一些重要的相互作用领域,AlphaFold 3预测精(准确)度提高一倍(100%);
基于扩散的架构:AlphaFold 3采用了大幅更新的基于扩散的架构,能够联合预测包括蛋白质、核酸、小分子、离子和修饰残基在内的复合物的结构。
新的信心度量方法:引入了新的信心度量方法,以预测最终结构中的原子级和成对误差。
模型局限性:虽然AlphaFold 3在蛋白质-配体结构预测方面取得了显著进步,但在某些情况下仍面临挑战,如立体化学的准确性、在无序区域产生幻觉结构以及动态行为的预测。
对生物学的贡献:AlphaFold 3的发展预示着结构生物学和治疗药物开发等领域的未来进步。
此外,Google DeepMind 也基于 AlphaFold 3 推出了一个免费平台——AlphaFold Server,供全世界的科学家利用它进行非商业性研究,预测蛋白质如何与细胞中的其他分子相互作用。
AlphaFold 3研究论文“Accurate structure prediction of biomolecular interactions with AlphaFold 3”及中文版论文,现已上线超算互联网,感兴趣的用户可扫描下方二维码,查阅论文全文。

LeCun漫画背后的StoryDiffusion技术,让复杂故事一气呵成
近期,图灵奖得主 Yann LeCun 转载了「自己登上月球去探索」的长篇漫画,引起了网友的热议,这些漫画是一项名为StoryDiffusion的新技术产出,该技术革新了长序列图像和视频的生成方式,特别是在维持连贯性和一致性方面的表现,从而能够创造引人入胜的故事叙述体验。
StoryDiffusion的核心亮点包括:
一致性自注意力(Consistent Self-Attention):能够在生成图像序列时确保内容一致性。这种方法无需额外训练,即可在生成过程中维持人物身份、面部特征和服装的一致性,从而生成主题连贯的图像序列。并且其生成的漫画或视频中的角色无论在何种场景下都能保持其独特性和辨识度。
无训练图像生成:该方法能够在无须额外训练的情况下,直接生成主题一致的图像。这意味着用户可以即时使用该技术,无需经历耗时的微调过程,提高了实用性和灵活性。
视频生成的稳定性与连贯性:通过引入语义运动预测器(Semantic Motion Predictor),将图像映射到语义空间进行运动预测,进而生成视频。这种方法相比传统基于潜在空间的运动预测更为稳定,能够生成更加流畅、逻辑连贯的长视频内容。

实验验证的优越性:通过与当前最先进方法的对比,包括ID保存方法(如IP-Adapter和Photo Maker)以及转场视频生成技术(如SparseCtrl和SEINE),StoryDiffusion在定性和定量分析中均展现出更优的性能,证明了其在生成一致图像和流畅视频方面的高效性和稳健性。(机器之心)
内容链接:https://www.jiqizhixin.com/articles/2024-05-06-9
91.1% 准确率,谷歌推出多模态医学大模型 Med-Gemini
近日,基于 Gemini 的核心优势,谷歌的研究人员推出了 Med-Gemini,这是一个功能强大的多模态模型系列,专门用于医学,能够无缝使用网络搜索,并且可以使用自定义编码器有效地针对新颖的模态进行定制。

图示:研究概述。(来源:论文)
Med-Gemini模型亮点包括:
高性能超越GPT-4系列:经过14项医疗基准测试,Med-Gemini在10项中树立了新的最先进(SOTA)标准,显著优于GPT-4模型。在MedQA (USMLE)基准上,其利用新颖的不确定性引导搜索策略达到了91.1%的准确率。
多模态基准测试优越表现:在包括NEJM Image Challenges和MMMU在内的7个多模态测试中,Med-Gemini比GPT-4V的平均性能提高了44.5%,并在长上下文理解任务上展现突出优势。
多模态与长上下文推理能力:Med-Gemini在处理文本、图像、视频等多种医疗数据类型方面展现出卓越的通用能力,尤其擅长理解和推理涉及复杂医疗场景的长上下文信息。
广泛的应用场景:在医疗记录摘要、临床转诊信生成、EHR问答等方面,Med-Gemini的评估显示了其在实际医疗环境中的巨大应用价值,特别是在多模态诊断对话和医学教育场景中。
持续研发与优化:研究人员强调针对安全关键领域如诊断的用途需深入研究与开发,包括提高对医疗影像标注的准确性、处理数据偏见及针对不同专科进行定制化改进。
论文链接:https://arxiv.org/abs/2404.18416
三、学术研究:
斯坦福升级20亿参数端侧AI模型,手机、汽车、机器人无缝融入
NEXA AI团队近期发布了全球首个超小型多模态AI Agent模型Octopus V3,该模型源自斯坦福大学的研究,实现了AI Agent在智能、速度、能耗及成本上的显著优化。
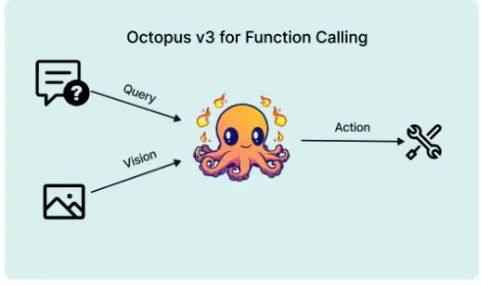
其亮点主要包括:
多模态能力增强:V3版本不仅保留了强大的语言处理能力,还新增了图像处理和多语言文本处理功能,实现了真正的多模态交互,能够同时理解和回应文本及图像输入。
超越同类的函数调用性能:在函数调用性能上,Octopus V3远超同类模型,与GPT-4V+GPT4相媲美,这归功于其创新的“functional token”技术,大幅降低了推理所需的文本量。
极低参数量与高效能:尽管功能强大,Octopus V3的参数量却少于10亿,这使得它在保持高性能的同时,能更易于部署在资源有限的端侧设备上,如智能手机、树莓派等,降低了能耗和成本。
提升用户体验:多模态和多语言处理能力让终端用户享受到更加丰富、智能的交互体验。例如,用户可通过图像和简单指令在购物应用中快速找到商品,或利用图像中的文字自动填充邮件内容,极大地提高了效率和便利性。
广泛的应用场景:从智能手机、AR/VR、机器人到智能汽车,Octopus V3展现了广泛的适用性和潜力,特别是在智能汽车交互上,能基于简单指令快速精准地执行复杂任务,如导航变更。
论文链接:https://arxiv.org/abs/2404.11459
高校联盟!Sora视频生成器迎来超现实升级
近日,由麻省理工学院、斯坦福大学、哥伦比亚大学和康奈尔大学联合研发了一种名为PhysDreamer的新模型,旨在解决现有3D视频生成中物体交互和物理表现不真实的问题。其核心技术在于其能够估计并优化物体的物理材料属性场,尤其是杨氏模量(决定物体刚度的关键),从而实现更加真实的动态合成。
PhysDreamer的主要特点包括:
基于物理的交互式动力学模拟:PhysDreamer能够为静态3D对象赋予交互式动力学,使它们能对真实世界中的物理交互做出响应,如外力作用或智能体操作,从而增强生成视频的真实感。

物理材料属性估计:利用移动最小二乘材质点法(MLS-MPM)作为物理仿真器,模型可以估计并优化物体的物理属性,特别是杨氏模量(E)、质量(m)等,这对于理解物体在受力时的动态表现至关重要。通过优化这些属性,模型能够生成符合物理规律的动态行为。

精确的动态合成:结合视频生成模型与可微分材质点方法,PhysDreamer优化材料场和初始速度场,通过最小化合成视频与参考视频的差异,达到高度逼真的动态合成效果。
双阶段优化策略:优化过程分为两阶段,首先固定杨氏模量优化粒子的初始速度,然后固定初始速度优化杨氏模量,这样的分步优化策略有助于提高稳定性和收敛速度。
子采样加速模拟:为了提高计算效率,模型引入子采样技术,通过K-Means聚类算法减少需要模拟的粒子数量,同时通过插值保持高保真度的渲染质量,实现了计算效率和渲染质量的平衡。
高质量渲染与视觉真实感:利用可微分渲染函数和精确的物理模拟,PhysDreamer生成的视频在视觉质量上表现出色,尤其在用户研究中得到了高比例参与者的偏好,认为其在运动真实性和视觉质量上优于其他方法。

物理属性场的参数化与正则化:材质场和速度场通过三平面和多层感知器进行参数化,并应用总变分正则化以提升空间平滑性,确保物理属性场的合理分布与连贯性。
论文链接:https://arxiv.org/pdf/2404.13026

相关新闻
-
2025-04-18
超算&AI应用周报Vol.53 | 智谱6款GLM模型、Skywork-OR1、InternVL3、HiDream-I1上线
-
2025-04-18
机器化学家:算力=智力=研究力
-
2025-04-17
最佳实践Vol.35 | Wan2.1-ComfyUI实操:玩转AI视频,让文字、图片一键动起来
-
2025-04-17
科研更“晋”一步 - 国家超算互联网生态沙龙在太原顺利开展
-
2025-04-16
智谱GLM开源模型系列上线,32B性能比肩DeepSeek-R1

 津公网安备12011602300273号
津公网安备12011602300273号
 电子营业执照
电子营业执照