


新闻动态
导读
6月7日,2024年全国高考正式开考,超算互联网上线AI漫画工具StoryDiffusion并创作高考主题漫画,祝广大考生心怀理想,全力以赴、所向披靡。

除了创作高考主题AI漫画,在这样一个充满挑战的日子里,超算互联网用语音AI模型ChatTTS,将文字化作温暖的声音,为步入高考考场的学子们送上最真挚的祝福与鼓励。
更多StoryDiffusion、ChatTTS模型功能特点、使用手册等商品内容可跳转至本期周报“前沿应用”板块查看或登录超算互联网搜索“StoryDiffusion”一键试玩,生成你的AI创意作品。
本期周报共5268字,预计阅读时间20分钟,您可以重点专注以下内容。文末更有AI彩蛋,欢迎享用~
超算AI快讯:
AI模型:智谱GLM-4-9B系列模型、多语言模型Aya-23、超强文本处理模型 Gemma-2B-10M、Deepseek-coder系列模型上线超算互联网
HPC软件:BerkeleyGWv4.0版本、EDDP v0.2版本上线超算互联网
前沿应用:AI漫画工具StoryDiffusion、语音生成模型ChatTTS为高考考生送祝福;新架构Mamba更新二代,新架构训练效率大幅提升
学术研究:阅读经典|OpenAI 前首席科学家Ilya Sutskever推荐AI阅读清单上线(附原文、译文);清华团队推出 DisenStudio解锁个性化多主体视频生成
文末AI彩蛋
一、超算AI快讯:
智谱GLM-4-9B系列模型上线超算互联网, 通用能力超越Llama 3
6月5日,智谱AI发布了新一代基座大模型GLM-4——性能全面比肩GPT-4。在中英文综合能力、感知推理、文字识别、图表理解等多方面多模态评测中,GLM-4系列表现出超越 GPT-4-turbo-2024-04-09、Gemini 1.0 Pro、Qwen-VL-Max 和 Claude 3 Opus 的卓越性能。
超算互联网现已上线基础版本 GLM-4-9B(8K)、对话版本 GLM-4-9B-Chat(128K)、超长上下文版本 GLM-4-9B-Chat-1M(1M)和多模态版本 GLM-4V-9B-Chat(8K),用户可以根据自己的需求,一键启用notebook进行部署推理。
基础版本GLM-4-9B(8K)具有8K的上下文长度,适用于大多数日常应用场景,如文本生成、文本摘要等;
对话版本GLM-4-9B-Chat(128K)和超长上下文版本GLM-4-9B-Chat-1M(1M)能够处理更加复杂的任务,如长文本生成、文档理解等,支持网页浏览、代码执行、自定义工具调用(Function Call)的能力,适用于智能客服、智能问答等应用场景;
多模态版本GLM-4V-9B-Chat(8K)则进一步将文本与视觉信息相结合,能够处理图像生成、图文匹配等任务, 具备 1120 * 1120 高分辨率下的中英双语多轮对话能力。

多语言模型Aya-23上线超算互联网,支持23种语言
本周,加拿大独角兽AI公司Cohere的开源多语言模型Aya-23-8B 上线超算互联网,Aya-23-8B 是一款多语言模型,作为Cohere非营利性研究实验室Cohere for AI的第二代产品,这款模型在多语言处理方面实现了显著的性能提升。Aya-23-8B 模型的主要亮点在于:
多语言能力:Aya-23-8B 支持23种语言,使得它成为跨语言应用的理想选择。这种广泛的语言覆盖范围使得模型能够在不同文化和语言环境中提供一致且高质量的服务。
分组查询注意力(GQA):模型采用了一种创新的分组查询注意力机制,每个键值(KV)头与多个查询(Q)头共享,这一设计有助于减少推理时的内存占用,提高了运行效率,使得即使是消费级硬件的研究人员也能利用这一技术进步。
指令理解和生成:通过针对指令风格的数据集进行微调,Aya-23-8B 在理解和响应指令方面表现出色,增强了其在执行各种自然语言处理任务时的能力。
预训练与微调:模型基于Cohere Command R系列的高性能预训练模型进行开发,并经过额外的微调,以优化其在多种语言和任务上的表现。

超强文本处理模型Gemma-2B-10M上线超算互联网
Gemma-2B-10M已于本周上线超算互联网平台,该模型通过循环局部注意力机制和 Infini-Attention 压缩内存技术,有效解决了传统 Transformer 模型在长文本处理上的性能瓶颈。其渐进式上下文窗口扩展训练策略使得模型训练更加高效,并在多个长文本处理任务上取得了显著成果。
其主要优势包括:
参数规模:模型拥有20亿(2B)参数,这是一个较大的参数量,表明模型有较高的容量来学习复杂的语言结构和模式。
低内存占用:尽管模型规模庞大且能处理极长的上下文,但它在运行时仅需32GB的显存,这归功于其创新的内存压缩技术,如Infini-Attention,这使得模型在资源有限的硬件上也能实用化。
处理千万级上下文长度:模型能够高效地处理长达1000万token的上下文,这对于需要理解大量前后文信息的任务来说极为重要,比如文档级别的理解、代码分析或长篇叙事的连贯性生成。

Deepseek-coder系列模型上线超算互联网,免费商用
本周,超算互联网上线大型语言模型Deepseek-coder,该模型擅长理解自然语言描述的问题,并将其转化为可执行的代码。无论是简单的算法实现、API调用还是复杂的系统架构设计,DeepSeek-Coder都能直接生成解决方案。除此之外,Deepseek-coder还拥有:
海量训练数据:从头开始训练 fon 2T Tokens,包括 87% 的代码和 13% 的中英文语言数据。
卓越的模型性能:在 HumanEval、MultiPL-E、MBPP、DS-1000 和 APPS 基准测试中,在公开可用的代码模型中具有最先进的性能。
高级代码完成能力:窗口大小为 16K,支持项目级代码补全和填空任务。
本周超算互联网上线主要覆盖3个版本Deepseek-coder-6.7b-base、Deepseek-coder-6.7b-instruct和Deepseek-coder-1.3b-instruct
此外,超算互联网同步上线多款Deepseek系列模型包含Deepseek-math系列(7b)和Deepseek-v2系列(Lite),目前在超算互联网平台上线的DeepSeek全系列模型支持开源和商业免费使用。

BerkeleyGWv4.0版本上线超算互联网
BerkeleyGW是一款基于第一性原理的计算软件,专门用于计算固体材料的准粒子和电子性质。它利用GW近似方法来计算材料的电子能带结构、光学性质、电子态密度等,是一种在固体物理和材料科学领域内广泛应用的计算工具。
BerkeleyGWv4.0版本目前已上线超算互联网,其主要特点包括:
高精度GW近似:软件采用GW近似方法,能够提供比传统密度泛函理论(DFT)更精确的电子能带结构。
多种材料类型支持:支持对金属、半导体、绝缘体等多种材料的电子性质进行计算。
平面波基组方法:采用平面波作为基函数,这种方法具有很好的数值稳定性和广泛的适用性,能够处理各种晶体结构和复杂材料体系。
并行计算能力:软件具有高效的并行计算能力,可以充分利用现代多核处理器和集群计算资源。
用户友好的界面:提供了易于使用的命令行界面和脚本,方便用户进行参数设置和计算。
丰富的文档和社区支持:拥有详尽的文档和活跃的用户社区,为用户解决使用过程中遇到的问题。

EDDP v0.2版本上线超算互联网
Ephemeral data derived potentials(短暂数据衍生势,简称EDDP)是一种设计用于加速原子结构预测的方法,它简单且经济高效,依赖于小单位单元中生成的训练数据,并使用轻量级神经网络进行拟合,从而实现平滑的交互,从而表现出结构预测所必需的强大的可转移性。
目前EDDP v0.2版本已上线超算互联网,其主要特点包括:
加速原子结构预测:EDDP设计的核心目标是加快对材料或其他系统中原子排列结构的预测速度,这对于理解材料属性和发现新材料至关重要。
轻量级神经网络拟合:采用轻量级神经网络来拟合数据,这样的网络结构较为简单,运算速度快,适合实时或近似实时的计算需求,同时保持了对原子间相互作用描述的准确性。
平滑的交互与强可转移性:通过神经网络的拟合,EDDP能够生成平滑的势能面,这对于模拟中跨不同构型的连续性预测非常重要。强可转移性意味着一旦模型在一个体系上训练完成,它可以较好地泛化到未见过的结构或化学环境中,提高了模型的适用范围。
广泛应用范围:EDDP不仅限于特定类型的材料或化学系统,已证明其可以应用于从单一元素到复杂化合物(如二元氢化物、三元氰化物)的广泛化学空间,以及在不同压力和化学计量比条件下。

二、前沿应用:
超算互联网上线AI漫画工具StoryDiffusion,一键生成一致性图像
本周,超算互联网上线由南开大学HVision团队开发的创新人工智能工具StoryDiffusion,其核心功能是生成连贯的图像故事,只需简单提供一个故事大纲,便能生成一部流畅的漫画。

StoryDiffusion主要功能特征包括:
角色连贯性保持:通过一致性自注意力机制,StoryDiffusion 能够生成风格和服装一致的图像,确保多图漫画角色的连贯性,从而实现流畅的故事叙述。
即插即用无需训练:通过将一致性自注意力技术整合进现有的 U-Net 图像生成模型架构,并重用原有的自注意力权重,StoryDiffusion 实现了无需训练的即插即用特性。
为了方便用户更快的上手,超算互联网提供详细的使用手册,欢迎扫描下方二维码或登录超算互联网,搜索关键词“StoryDiffusion”实操体验。

语音生成模型ChatTTS上线超算互联网,支持中英文对话
本周,ChatTTS上线超算互联网。ChatTTS是一款专为对话场景设计的语音生成模型,该模型基于Text-to-Speech(TTS)技术,具备中英文混合阅读及多说话人能力,通过使用10万小时的中英文数据训练,提供高质量、自然流畅的语音输出。除此之外,ChatTTS的特点还有:
多语言支持:ChatTTS 的一个关键特性是支持多种语言,包括英语和中文。这使其能够为广泛用户群提供服务,并克服语言障碍。
对话任务兼容性:ChatTTS 很适合处理通常分配给大型语言模型LLMs的对话任务。它可以为对话生成响应,并在集成到各种应用和服务时提供更自然流畅的互动体验。
易用性:ChatTTS 为用户提供了易于使用的体验。它只需要文本信息作为输入,就可以生成相应的语音文件。
语音角色选择:用户可以根据应用场景的需要,从多个预设的语音角色中选择最合适的声音,增加语音的个性化和表现力。

新架构Mamba更新二代,新架构训练效率大幅提升
Mamba-2,作为新一代人工智能模型强势回归并在ICML 2024会议上取得成功。Mamba-2采用了一种名为结构化状态空间对偶性(SSD)的新算法,旨在整合状态空间模型(SSM)和Transformer架构的优势。SSD通过在递归矩阵A上增加结构,改进了SSM的效率,并允许使用矩阵乘法,提高了硬件加速能力,尤其是利用GPU和TPU的张量核心。
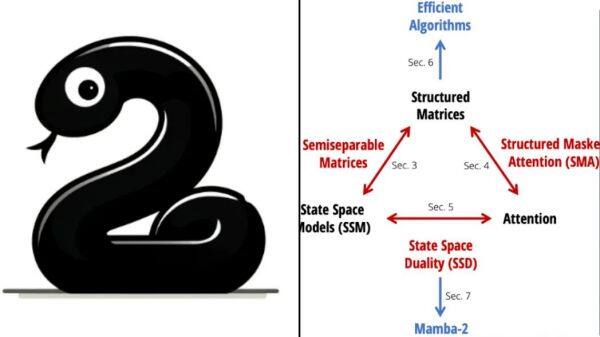
Mamba-2要点内容如下:
性能提升:Mamba-2相比前代Mamba,在算法层面的改进使其训练速度提高了2至8倍,这主要归功于SSD算法的高效计算和对硬件资源的优化利用。在特定任务如序列长度为2K时,Mamba-2与FlashAttention-2性能相当,但随着序列长度增长,Mamba-2的优势更加明显。
模型效率与规模:在理论上,Mamba-2通过SSD实现了模型更小、消耗更低、速度更快的特性,同时保持了与Transformer模型同等或更优的性能。它支持更大的状态维度(N值从16提升至64、256等),并且在保持模型性能的同时,有效减少了模型参数数量。
算法与实现优化:SSD算法不仅提高了计算效率,还简化了实现过程,使得模型实现仅需少量代码即可完成,相较于Mamba-1的实现更为简洁。Mamba-2的设计允许更好地利用张量核心,克服了Mamba-1在硬件效率上的限制。
系统与扩展优化:研究者在Mamba-2中还关注了大规模训练所需的张量并行和序列并行优化,确保了模型在处理长序列时的高效运行,并且支持变长序列的高效微调和推理,解决了大规模训练和部署中的通信瓶颈问题。
语言建模与下游任务:Mamba-2在语言建模任务上展现出了与Mamba-1相媲美或超越的性能,并且在特定的合成任务如多查询联想回忆(MQAR)中,性能显著优于Mamba-1,这得益于其更大的状态空间和更高效的算法。(新智元)
内容链接:https://hub.baai.ac.cn/view/37641
三、学术研究:
阅读经典|OpenAI 前首席科学家Ilya Sutskever推荐AI阅读清单上线(附原文、译文)
本周,超算互联网上线OpenAI前首席科学家Ilya Sutskever推荐的这27篇AI阅读清单合集,其中包括 AlexNet、LSTM、以及引领NLP模型架构变革的《Attention Is All You Need》等经典之作,覆盖神经网络架构、深度学习、机器学习与算法等众多领域知识的文章、书籍、课程等。
Ilya Sutskever的推荐理由是:‘If you really learn all of these, you’ll know 90% of what matters today.’("如果你弄懂所有这些资料,你就会知道当今有关 AI 的 90% 重要内容了!")
这份阅读清单合集将为您对传统机器学习算法和时下主流AI基础理论有系统性的了解。为了方便大家阅读下载这些论文、文章,超算互联网上架了论文原文、编译了论文核心要点,中文译文,感兴趣的技术人员可扫描下方二维码或登录超算互联网搜索“Ilya推荐阅读”在线查阅。

清华团队推出 DisenStudio解锁个性化多主体视频生成
近日,来自清华大学的研究团队提出了一个新颖的框架 DisenStudio,其可以在每个主体只有少量图像的情况下,为定制的多个主体生成文本引导视频,并确保视频中每个主体都被适当识别和呈现,避免了主体缺失的问题。
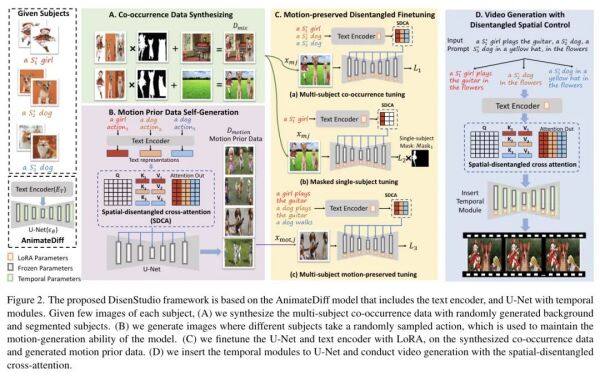
其核心要点在于:
空间分离交叉注意机制:这是DisenStudio中的关键技术,它增强了基于扩散的预训练文本到视频模型。该机制有助于更精确地将文本描述的动作与对应的视频主体绑定,实现了动作与主体之间的准确对应(动作绑定)。
微调策略组合:为了优化多主体视频的生成效果,DisenStudio采用了三种微调策略:
多主体共现微调:确保多个主体能同时出现在视频中,并且各自保持其独特的视觉属性。
屏蔽单主体微调:通过有选择性地屏蔽单个主体进行训练,帮助模型更好地理解和区分不同的主体。
多主体运动保留微调:在对静态图像进行调整时,维持模型生成连续、自然的时间运动表现能力,即使是在主体静止的图像上也能预测合理的动态行为。
少量图像定制:即便每个主体只有少量的参考图像,DisenStudio仍能生成高质量的定制内容,这极大地扩展了其实际应用的灵活性和范围。
广泛适用性与高性能:经过大量实验验证,DisenStudio在多种评估指标上超越了现有方法,展现了作为可控视频生成工具的强大潜力,适用于多样化的应用场景,包括但不限于娱乐、教育、广告和个人化内容创作。
论文链接:https://arxiv.org/abs/2405.12796
文末AI彩蛋
端午节,一个承载着深厚历史文化底蕴的节日。在这粽香飘溢、龙舟竞渡的美好时节,超算互联网邀您一同探索创意的边界,用SDXL-lightning、Stable Diffusion、StoryDiffusion等AI大模型创作生动独特的端午AI创意作品,让端午节的庆祝活动更加丰富多彩。




点击链接https://bvjoh3z2qoz.feishu.cn/docx/O1Cndurj0oFVUhx1bS9cjySinLf,进入HPC&AI应用知识库
相关新闻
-
2025-04-18
超算&AI应用周报Vol.53 | 智谱6款GLM模型、Skywork-OR1、InternVL3、HiDream-I1上线
-
2025-04-18
机器化学家:算力=智力=研究力
-
2025-04-17
最佳实践Vol.35 | Wan2.1-ComfyUI实操:玩转AI视频,让文字、图片一键动起来
-
2025-04-17
科研更“晋”一步 - 国家超算互联网生态沙龙在太原顺利开展
-
2025-04-16
智谱GLM开源模型系列上线,32B性能比肩DeepSeek-R1

 津公网安备12011602300273号
津公网安备12011602300273号
 电子营业执照
电子营业执照