


新闻动态
导读
本周超算互联网上线了六款视觉语言模型,6月16日(周日)是父亲节,我们选择了其中三款生文图模型,结合父亲节主题制作创意海报,祝天下所有的父亲,节日快乐。


本期周报共5358字,预计阅读时间20分钟,您可以重点专注以下内容。
超算AI快讯:
AI模型:图像生成模型Stable Diffusion 3 Medium、ControlNet-canny-sdxl-1.0、ControlNet-openpose-sdxl-1.0、ControlNet-scribble-sdxl-1.0、SDXL Flash、Mobius上线超算互联网HPC软件:Atomsk beta_0.13.1版本、ESMF v8.7.0版本上线超算互联网
前沿应用:智源大模型全家福亮相;Apple AI背后解密,服务器模型媲美GPT-3.5-Turbo;Luma AI推文生视频模型Dream Machine
学术研究:Ilya推荐阅读|使用深度卷积神经网络进行ImageNet分类;上交大发布PowerInfer-2.0,推理性能猛增29倍
一、超算AI快讯:
超高清图像生成模型Stable Diffusion 3 Medium上线超算互联网
Stable Diffusion 3 Medium(SD3 Medium)是由 Stability AI 开发的AI图像生成模型,已于本周上线超算互联网。该模型具备20亿参数,专为生成高质量、高细节图像设计,它还能理解复杂的视觉指令,包括空间布局、动作和风格等,且在文本生成方面达到新高度,减少人工干预的痕迹和错误。
该模型亮点包括:
技术特点:采用多模态扩散Transformer(MMDiT)架构,使用独立的权重集来处理图像和文本信息。使得图像和文本能够在各自的空间中进行独立的处理,同时也能相互影响,提升模型对文本的理解能力和图像生成效果。
图像处理能力提升:SD3 Medium能有效解决手部和面部瑕疵,不需要复杂的后期处理就能得到优质图像。同时,它能够理解并执行涉及复杂空间关系、构图元素、动作指示和风格的指令;
文本能力增强:在文本生成方面取得了重大进步,产出的文本自然流畅,无明显人工痕迹和拼写错误;在文本遵循度方面也表现出色,能够更准确地将文本内容融入到图像中,生成的图像更符合文本描述。

超算互联网上线3款SDXL-1.0 ControlNet模型,提升多模态图像生成能力
本周,超算互联网上线三款基于Stable Diffusion Extended Large (SDXL-1.0)架构的ControlNet模型,分别是ControlNet-canny-sdxl-1.0、ControlNet-openpose-sdxl-1.0以及ControlNet-scribble-sdxl-1.0。
ControlNet-canny-sdxl-1.0

功能亮点:利用Canny边缘检测算法,从输入图像中提取边缘信息,指导模型生成具有清晰轮廓和精细结构的图像。
应用场景:用于生成具有特定轮廓的艺术作品、设计图或概念图。
ControlNet-openpose-sdxl-1.0

功能亮点:结合OpenPose人体姿态估计技术,准确捕捉并描绘人体关节和骨骼,生成自然流畅的人体姿态图像。
应用场景:适用于舞蹈、体育、时尚摄影等领域,为创作注入生动的人体动态元素。
ControlNet-scribble-sdxl-1.0

功能亮点:只需提供粗略的手绘草图或涂鸦,能够将简单的线条和形状转化为逼真的视觉作品,实现从草图到成品的快速转化。
应用场景:适用于概念设计、艺术创作、速写转化,为艺术家和设计师提供高效创作工具。

图像生成模型SDXL Flash上线超算互联网,提升图片质量与细节表现
由SDXL团队携手Project Fluently联合研发的图像生成模型SDXL-Flash本周上线超算互联网,模型在图像质量上的表现尤为突出,在细节处理上极为精细,无论是复杂的纹理、微妙的光影变化,还是色彩鲜艳度和对比度的优化,使得生成的图像色彩丰富、层次分明,更加接近真实世界的视觉效果。该模型的亮点包括:

高质量的图像输出:尽管在速度上稍逊于LCM、Turbo 和 Lightning等模型,但SDXL Flash 在图像质量上实现了显著提升。
用户体验优先:模型提供了简单易懂的设置步骤和配置文件(CFG),使得用户能够轻松达到最佳效果。
易于安装和使用:支持通过 pip 安装 torch diffusers 库,使用户能够方便地安装和使用该模型。
应用场景广泛:SDXL Flash 在艺术创作、设计和媒体生成等多个领域都具有广泛的应用前景,能够为艺术家、设计师和开发者提供高质量的图像生成服务。

文生图模型Mobius上线超算互联网,实现无偏见高质量图像生成
超算互联网上线由 Corcelio 开发的一个扩散模型Mobius,该模型代表了在无偏见(debiased)扩散模型领域的最新技术水平。

模型亮点包括:
无偏见表示重排(Domain-agnostic debiasing):Mobius 采用了一种创新的、不针对特定领域或风格的去偏见方法,旨在去除扩散模型中的固有偏见,同时保持模型的通用性。
广泛的风格和领域通用性:Mobius 通过采用一种全新的解构框架,实现了在各种风格和领域中的泛化能力,从而消除了从头开始进行昂贵的预训练的需求。
生成高质量、逼真的图像:该模型能够根据提供的文本提示生成高质量、逼真的图像。它特别擅长于传达情感、氛围和叙事感。
多用途和创造性应用:艺术家和设计师可以利用这个模型来生成灵感视觉概念,探索新的创意方向。在电影、广告和游戏行业的内容创作者可以利用 Mobius 快速原型设计和可视化想法。

Atomsk beta_0.13.1版本上线超算互联网
Atomsk是一个用于分子模拟和计算化学的软件包,它提供了一整套工具来帮助科学家和研究人员分析和模拟分子结构、化学反应和材料的性质。它支持多种计算方法,包括量子力学(QM)、分子力学(MM)和混合量子-分子力学(QM/MM)方法。
本周,Atomsk beta_0.13.1版本上线超算互联网,其功能特点包括:
多尺度模拟:支持从原子到分子再到材料的多尺度模拟。
多种计算方法:集成了多种计算化学方法,包括但不限于密度泛函理论(DFT)、分子动力学(MD)和蒙特卡洛(MC)模拟。
图形用户界面:提供了直观的图形用户界面,简化了复杂模拟的设置过程。
脚本和自动化:支持脚本编程,允许用户自动化复杂的工作流程。
插件系统:允许第三方开发者创建插件来扩展Atomsk的功能。
高性能计算:优化了并行计算能力,可以在多核处理器和GPU上运行,以提高计算效率。
数据可视化:内置了多种数据可视化工具,帮助用户直观地理解模拟结果。

ESMF v8.7.0版本上线超算互联网
Earth svstem Modeling Framework(ESMF)是一个用于构建和运行地球系统模型的软件框架。它提供了一套通用的组件和工具,使得科学家和研究人员能够开发复杂的地球系统模型,包括气候模型、海洋模型、大气模型等。ESMF的设计目标是提高模型的可重用性、可扩展性和可维护性,同时降低开发和运行地球系统模型的复杂性。
本周,超算互联网上线Esmf v8.7.0版本,其功能特点包括:
模块化设计:ESMF采用模块化设计,使得各个组件可以独立开发和维护。
多物理过程支持:支持多种物理过程的模拟,如大气、海洋、陆地和冰层等。
并行计算:ESMF支持并行计算,可以充分利用现代计算机的多核和分布式计算能力。
数据管理:提供了强大的数据管理功能,包括数据的输入、输出和处理。
时间管理:ESMF提供了灵活的时间管理机制,支持复杂的时间步进策略。
组件集成:支持将不同的模型组件集成到一个统一的框架中。

二、前沿应用:
2024智源大会开幕,智源大模型全家福亮相
2024年6月14日,第六届“北京智源大会”在中关村展示中心开幕。本次大会聚集了众多国际知名学者、顶级研究机构及国内大模型公司的领导者,共200多位顶尖专家参与,共同探讨人工智能的核心技术路径与应用场景。重点聚焦于大模型技术的创新与生态建设。

以下是会议的几个核心要点:
低碳单体稠密万亿语言模型Tele-FLM-1T:智源研究院与电信人工智能研究院合作研发,通过模型生长和损失预测技术,以9%的行业标准算力资源训练出万亿级语言模型,展示了在节能减排和高效训练方面的重大突破。
通用语言向量模型BGE系列:针对大模型在理解和生成中出现的幻觉问题,智源研究院推出BGE系列模型,通过检索增强技术实现了精准的语义匹配,提高了大模型调用外部知识的能力,其性能超越了多家国际顶尖机构的同类模型。
多模态大模型进展:
原生多模态世界模型Emu 3:智源研究院展示了Emu 3模型,它能够在图像、视频、文字之间实现统一的输入输出。
端到端基于视频的多模态具身导航大模型NaVid:全球首个此类模型,直接接受视频和语言指令输入,控制机器人行动,无需传统导航系统的辅助。
生物计算与医疗应用:
全原子生物分子模型OpenComplex 2:在生物分子结构预测领域取得国际领先成就,为药物研发和生命科学研究提供了强大的工具。
实时孪生心脏计算模型:实现了高精度仿真,为心脏疾病的个性化治疗提供了创新方案。
技术基座与生态建设:
FlagOpen大模型开源技术基座2.0:提供了一站式大模型开发与研究平台,支持异构芯片与多种深度学习框架,进一步完善了模型、数据、算法、评测、系统的布局。
具身智能创新平台:智源研究院正与多家高校、研究机构及企业合作,致力于建设具身智能的创新生态系统。
数据集与评测标准:
IndustryCorpus多行业数据集:开源的中英文数据集覆盖了18类行业,推动了大模型在产业界的广泛应用。
FlagEval大模型评估系统:全面升级了大模型评估工具和方法,推动了国际间在评估标准上的合作与共享。(智源研究院)
内容链接:https://mp.weixin.qq.com/s/VrWL-v4B7BS59ZbWRtt9yg
Apple AI背后解密,服务器模型媲美GPT-3.5-Turbo
近日,苹果在全球开发者大会上发布全新个性化智能系统Apple Intelligence,该系统深度集成于iOS 18、iPadOS 18及macOS Sequoia。该系统通过深度学习和人工智能技术,能够学习和理解用户的日常习惯、偏好和需求,从而提供高度个性化的服务和推荐。

Apple Intelligence的主要特点有:
强大的生成模型:Apple Intelligence由多种高度智能的生成模型组成,其中包括一个拥有约30亿参数的设备端语言模型和一个更大的基于服务器的语言模型。这些模型通过大量的数据和计算资源进行训练,以实现准确的语言理解和生成能力。
高效与节能:苹果通过AXLearn框架、数据并行、张量并行等技术训练模型,确保了训练效率和模型性能。模型在设备端的优化包括分组查询注意力机制、低位palletization技术、LoRA适配器等,以减少内存占用和功耗,提升速度。
适配器微调技术:采用了一种称为“适配器微调”的技术,允许系统通过仅微调适配器层来定制模型以支持特定任务。
动态任务处理能力:适配器模型可以动态加载、临时缓存在内存中以及交换,这使得基础模型能够动态地专门处理当前的任务。
高效的训练与部署:为了促进适配器的训练,苹果创建了一个高效的基础设施,以便在基本模型或训练数据更新时快速重新训练、测试和部署适配器。(机器之心)
内容链接:https://www.jiqizhixin.com/articles/2024-06-13-
Luma AI推文生视频模型Dream Machine ,120秒内实现高质量视频生成
6月13日,知名的3D建模平台Luma AI发布了他们的最新文生视频模型Dream Machine,它能够快速将文本和图像转换为高质量、逼真的视频。并且在120秒内生成120帧视频,具备流畅的运动、电影摄影和戏剧效果。
Dream Machine的主要特性:
高质量视频生成:通过结合文本描述和图像输入,Dream Machine能够创造出细节丰富、视觉效果惊人的视频片段。这种能力使得从概念到视觉叙事的转换变得既准确又富有创意。
快速视频生成:效率是Dream Machine的另一大亮点。它能够在短短120秒内完成120帧视频的生成任务,极大缩短了创作周期,提升了创作者的工作效率。
深度角色和物理效果理解:该系统具备对人物、动物以及各类物体在物理世界中互动方式的深入理解。
多样化摄像机运动:Dream Machine提供了广泛的摄像机动态选项,可以生成流畅、电影风格的镜头移动,这些动态效果能够完美匹配视频内容的情绪和叙事需求,提升观看体验。物理模拟支持:整合了高级物理引擎,能够精确模拟重力作用下的下落、物体间的碰撞效果以及光线与阴影的自然变化,这些都极大地增强了视频的真实度和沉浸感。(Dream Machine )
内容链接:https://lumalabs.ai/dream-machine
三、学术研究:
Ilya推荐阅读|使用深度卷积神经网络进行ImageNet分类
论文《ImageNet Classification with Deep Convolutional Neural Networks》(简称 AlexNet),是深度学习领域的一个里程碑。它由 Alex Krizhevsky、Ilya Sutskever 和 Geoffrey Hinton 在2012年发表,展示了深度卷积神经网络(Convolutional Neural Networks, CNNs)在大规模图像识别方面的显著进步。
由于其重要性和影响力,该论文被 Ilya Sutskever 列入了他的27篇AI阅读清单中,作为理解现代人工智能核心概念的关键文献之一。

为了方便大家获取Ilya Sutskever推荐的AI阅读清单,超算互联网上架了论文原文、编译了论文核心要点,中文译文,感兴趣的技术人员可扫描下方二维码或登录超算互联网搜索“Ilya推荐阅读”在线查阅。

上交大发布PowerInfer-2.0,推理性能猛增29倍
近日,上海交通大学IPADS实验室发布了LLM手机推理框架——PowerInfer-2.0,旨在解决在内存受限的智能手机上快速部署和运行大规模AI模型的难题。针对手机内存小和算力弱的局限性,通过创新方法显著提高了大模型推理速度,如能让Mixtral 47B模型在手机上实现每秒11个token的处理速度,比当前流行的开源框架llama.cpp快25至29倍。
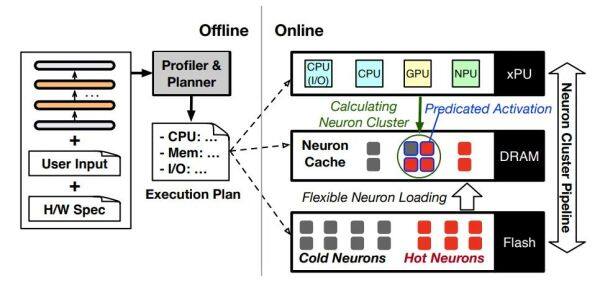
图:powerinfer2的体系结构概述。
其核心机制主要包括:
动态神经元缓存:针对手机DRAM容量小的问题,利用稀疏模型推理时只需激活一部分神经元的特点,将神经元分为“热”和“冷”两类,并使用LRU(Least Recently Used)策略维护神经元缓存池。活跃的“热神经元”保留在高速内存中,“冷神经元”则按需加载,从而大幅减小内存占用。
以神经元簇为粒度的异构计算:将大矩阵计算分解为细粒度的“神经元簇”,根据不同处理器(CPU、GPU、NPU)特性动态调整簇的大小,以最优方式分配计算任务。例如,将大量神经元合并交给NPU处理大矩阵计算,或在CPU上分散处理多个小簇,增强异构计算效率。
流水线并行技术:提出分段神经元缓存与神经元簇级流水线技术,允许在等待I/O操作时调度其他准备好的神经元簇进行计算,隐藏了I/O延迟,同时支持不同参数矩阵的神经元簇交错执行,提升并行效率。
模型与存储优化:针对手机存储特点设计模型存储格式,提高读取速度,并采用分段缓存策略针对不同类型权重优化缓存策略,提升缓存命中率,减少磁盘I/O。
低成本模型稀疏化:与清华和上海人工智能实验室合作提出低成本模型稀疏化方法,通过dReLU激活函数提升模型稀疏性同时保持模型性能,利用高质量多样化训练数据集确保稀疏化后的模型性能,并实现模型参数激活量显著减少。
论文链接:https://arxiv.org/abs/2406.06282

点击链接https://bvjoh3z2qoz.feishu.cn/docx/O1Cndurj0oFVUhx1bS9cjySinLf,进入HPC&AI应用知识库
相关新闻
-
2025-04-18
超算&AI应用周报Vol.53 | 智谱6款GLM模型、Skywork-OR1、InternVL3、HiDream-I1上线
-
2025-04-18
机器化学家:算力=智力=研究力
-
2025-04-17
最佳实践Vol.35 | Wan2.1-ComfyUI实操:玩转AI视频,让文字、图片一键动起来
-
2025-04-17
科研更“晋”一步 - 国家超算互联网生态沙龙在太原顺利开展
-
2025-04-16
智谱GLM开源模型系列上线,32B性能比肩DeepSeek-R1

 津公网安备12011602300273号
津公网安备12011602300273号
 电子营业执照
电子营业执照