


新闻动态
导读
周报内容均源自海内外主流媒体报道、高校官网等公开信息梳理、相关领域优质KOL原创深度,主要包括超算AI快讯、前沿应用、学术研究等。
本期周报共4625字,预计阅读时间18分钟,您可以重点专注以下内容。
超算AI快讯:
AI模型:文生图模型yodayo-ai/Holodayo XL 2.1、yodayo-ai/Kivotos XL 2.0、Little Tinies 、BandW-Manga、阿里开源语言模型Qwen2-0.5B-Instruct上线超算互联网
HPC软件:Fcclasses3 v3.0.3版本、Phoebe上线超算互联网
前沿应用:Anthropic发布Claude 3.5 Sonnet,GPT-4o遭遇最强挑战;Google DeepMind的最新V2A技术,让AI影片“发声”
学术研究:经典论文推荐 | FMI 3.0:推动多学科系统仿真创新应用;Ilya推荐阅读|用于关系推理的简单神经网络模块;中山大学&联想AI技术让连环画互动自然流畅
一、超算AI快讯:
Yodayo两款文生图模型上线超算互联网,生成高质量动漫美学图像
本周,超算互联网上线专为动漫社区设计的AI创意平台Yodayo的两款文生图模型——Holodayo XL 2.1 和 Kivotos XL 2.0。这两款开源模型均基于Animagine XL V3基础之上,确保了生成高质量动漫风格图像的准确性。
Holodayo XL 2.1模型亮点包括:
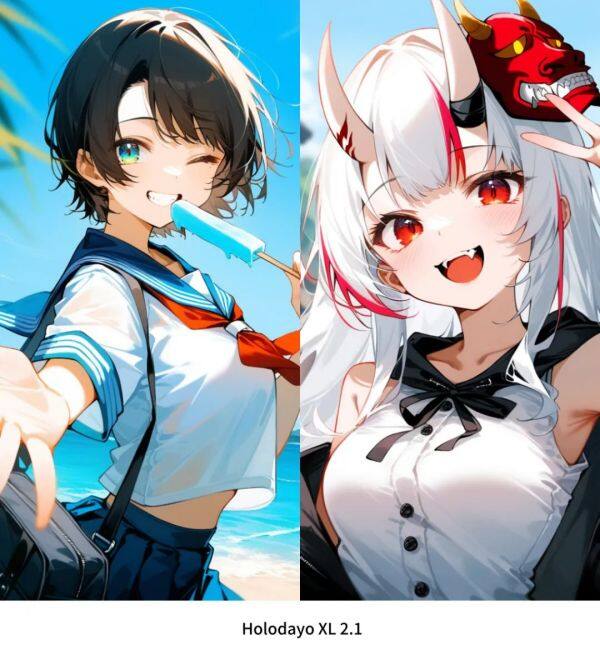
针对性优化:为准确生成代表二次元UP主视觉美学风格的图像进行了优化。
错误修复:解决了Holodayo XL 2.0中存在的问题,比如不自然的手部描绘、人体结构不佳,以及因文本编码器微调导致的“灾难性遗忘”效应,还调整了艺术风格的曝光度,避免过度曝光。
Kivotos XL 2.0模型亮点在于:

Kivotos XL 2.0是Yodayo Kivotos XL系列模型的最新版本,是基于扩散的文本到图像生成模型,专门针对高质量的Blue Archive动漫风格艺术作品进行了微调,能够生成各种动漫风格的图像,从人物肖像到复杂的场景和环境构图。

Little Tinies 、BandW-Manga手绘风格模型上线超算互联网
本周,超算互联网上线了两款手绘风格的文生图模型Little Tinies 和BandW-Manga。
Little Tinies模型——通过简单的文字提示生成经典的手绘卡通风格图像
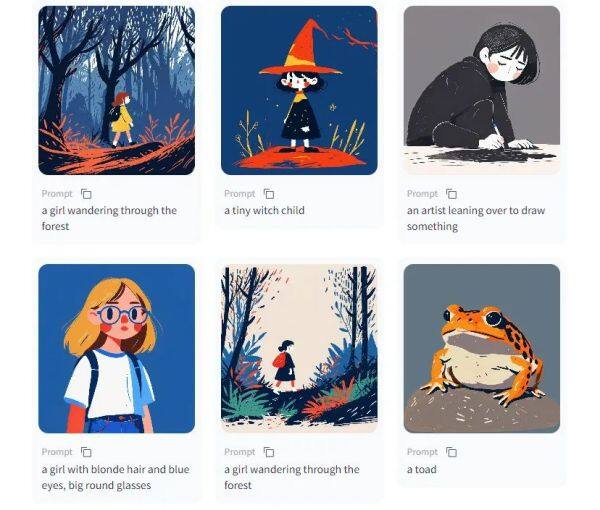
功能亮点:Little Tinies擅长以经典卡通美学生成异想天开、风格化的插图,使得角色和场景看起来更加柔和细腻。
应用场景:用于生成有温馨、可爱的卡通人物,线条柔和、色彩鲜明,其迷人的复古风格非常适合为儿童书籍、童话故事或幻想故事配图。该模型还可用于为游戏、动画或其他多媒体项目创建独特的艺术品、概念设计或视觉资产。
BandW-Manga模型——通过简单提示生成超粗线条肖像画

功能亮点:BandW-Manga是一款用于生成超粗线肖像插图的文生图模型,能够自动处理灰度、阴影和线条重量,以模仿传统漫画的手绘效果。
应用场景:适用于制作大胆的黑白线条艺术肖像和插图,捕捉戏剧感和极简主义。例如,为漫画、连环画和图画小说设计人物角色、为动画电影或视频游戏创作概念艺术、为海报或社交媒体内容制作插图等。


Qwen2-0.5B-Instruct上线超算互联网,性能全方位包围Llama-3
Qwen1.5发布仅过4个月,Qwen2正式开源。Qwen2系列包含5个尺寸的预训练和指令微调模型,其中包括Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B和Qwen2-72B。
超算互联网现本周上线Qwen2-0.5B-Instruct版本模型,在保持较高性能的同时,有效控制了资源消耗,适用于多数的工业界和学术界应用。
相比Qwen1.5系列,Qwen2系列的重要升级包括:
在中文英语的基础上,训练数据中增加了27种语言相关的高质量数据;
多个评测基准上的领先表现;
代码和数学能力显著提升;
增大了上下文长度支持,最高达到128K tokens(Qwen2-72B-Instruct)。

科学计算软件Fcclasses3 v3.0.3版本上线超算互联网
FCclasses 3是Fabrizio Santoro(ICCOM-CNR)和Javier Cerezo(UAM)共同开发的软件,主要用于模拟振动光谱和研究非辐射速率。该软件使用Fortran 90编写,融入了Fortran 77的部分,于2022年7月正式发布,并经历了3个主要版本的维护更新,最新版本为2023年12月1日的FCclasses 3。
本周,Fcclasses3 v3.0.3版本上线超算互联网平台,其核心优势在于:
功能扩展与多样性:相比之前Fcclasses3版本显著增强了计算能力,能够处理更多类型的光谱分析。此外,它还能在费米黄金法则框架下计算非辐射衰变过程,如非绝热耦合引发的内部转换和系统间交叉等。
模型势能面灵活性:实现了垂直和绝热谐波模型的全面系列,并支持多种坐标系统(如笛卡尔、曲线内部坐标和直接法向坐标),特别是曲线内部坐标的应用,使得在势能面上非平稳点的振动模型得以扩展。
降维模型定义:提供内部坐标中迭代投影仪的工具,有助于构建严格的降维模型,这对于研究复杂、灵活分子结构尤其重要。
计算效率与通用性:通过预筛选技术和状态求和方法,以及分析时间相关函数的瞬态公式实现,Fcclasses 3允许在绝对零度到任意温度下进行高效计算,同时支持定义特定振动预激励的初始状态,提升了在不同条件下的应用范围和实用性。

科学计算软件Phoebe上线超算互联网
Phoebe 是一个高性能计算软件,旨在从头预测材料的输运特性,与 ab-initio 软件套件 Quantum ESPRESSO 集成,支持电子-声子特性和非谐波力常数的计算,同时兼容 Phono3py 输出的非谐波力常数。
本周Phoebe上线超算互联网,其亮点主要体现在:
从头计算输运特性:能够预测电子-声子限制的电导率和声子热导率等关键输运性质。
高性能计算优化:采用C++编写,利用MPI/OpenMP实现混合并行化,通过 ScaLAPACK 进行分布式内存计算以及使用 Kokkos 支持 GPU 加速,专为现代高性能计算(HPC)平台设计。
全面的输运系数计算:包括电子-声子限制的电子输运系数(电导率、塞贝克系数、电子热导率),晶格热导率的全谱计算(考虑三声子散射、同位素散射和边界散射)。

二、前沿应用:
Anthropic发布Claude 3.5 Sonnet,GPT-4o遭遇最强挑战
6月21日,Anthropic公司发布了Claude 3.5系列模型的第一个版本——Claude 3.5 Sonnet,该模型在多项性能评估中超越了竞争对手,其创新之处在于提高了行业智能化标准,展现了更快的速度与增强的智能,尤其在研究生水平推理、本科生水平知识掌握及编码能力方面设立了新基准。

Claude 3.5 Sonnet的优势特点主要体现在:
成本效益:Claude 3.5 Sonnet的成本比较合理,与上一代中等模型Claude 3 Sonnet相近,具体为3美元/百万输入token和15美元/百万输出token。
高速运行:运行速度是其前身Claude 3 Opus的两倍,这意味着在处理任务时效率更高。
卓越的编码能力:在内部代理编码评估中,解决了64%的问题,远高于Claude 3 Opus的38%,表明其在编写、编辑代码和执行复杂逻辑方面有显著进步。
先进视觉处理:它是Anthropic目前最强大的视觉模型,能在解读图表和从图像中准确转录文本等视觉推理任务上实现显著改进,这对于零售、物流和金融服务等领域尤为重要。
增强的交互性:通过新功能Artifacts,用户可以在专用窗口中实时查看、编辑由Claude生成的各种内容(如代码、文档、设计等),将AI生成内容直接融入工作流程,标志着向协作式工作环境的转变。(Anthropic)
内容链接:https://www.anthropic.com/news/claude-3-5-sonnet
Google DeepMind的最新V2A技术,让AI影片“发声”
近期,Google DeepMind 宣布正在开发一项新技术Video-to-Audio,简称V2A,该技术能够为视频内容自动生成配套音频,标志着AI视频创作进入视听同步的新纪元。V2A技术独特之处在于它能够利用视频像素信息和自然语言文本提示,为视频中的场景创作出匹配的音效、背景音乐甚至是符合角色和风格的对话,大大提升了视频内容的沉浸感和表现力。
V2A技术的亮点主要体现在:
视听同步生成:V2A技术能够将视频内容与自动生成的音频完美同步,解决了长期以来AI视频创作中音频缺失的问题,实现了真正意义上的视听融合。
像素级理解与文本提示:与现有技术不同,V2A能够直接理解视频的原始像素信息,并且允许用户通过自然语言文本提示来指导音频生成,使得生成的音频与视频内容高度匹配。文本提示的使用是灵活的,既可以作为生成特定声音的引导,也可以不使用,增加了技术的适用范围和创造性。
多场景应用:这项技术不仅能够为新创作的视频内容添加音效和配乐,还能为无声电影、档案材料等传统影像赋予新生,拓宽了创意表达的边界。
自定义音轨生成:V2A允许用户定义“正向提示”和“负向提示”,从而在生成音频时有更多控制权,能够快速尝试并选择最符合视频情境的音频输出,提高了音频制作的灵活性和个性化程度。
技术深度与创新:研究团队采用的扩散方法在音频生成上取得了显著成果,这种方法从随机噪声出发,通过迭代细化得到高质量的音频。该过程融合了视觉和文本信息,确保了生成音频的真实性和与视频内容的一致性。
高级音频质量与特定声音生成:为了生成更高质量的音频,训练过程中加入了AI生成的注释,这些注释详细描述了声音特征和对话文本,帮助技术学习将特定音频与广泛的视觉场景关联。
自动化与简化流程:V2A技术无需手动对齐音频与视频,极大简化了创作流程,降低了制作高质量视听内容的技术门槛。(Google DeepMind)
内容链接:https://deepmind.google/discover/blog/generating-audio-for-video/
三、学术研究:
经典论文推荐 | FMI 3.0:推动多学科系统仿真创新应用
随着如汽车、飞机等多学科系统的设计和仿真变得日益复杂,传统的建模和仿真方法面临着挑战。不同领域的模型通常使用不同的建模工具和环境,这导致了模型之间的互操作性问题。为了解决这些问题,论文《The Functional Mock-up Interface Enabling New Applications》提出了一种用户定义模型接口的标准FMI,允许模型在不同的工具之间交换和执行,从而简化多学科系统的集成和协同仿真过程。
论文首先介绍了FMI标准的发展历程、目标和特性。FMI 3.0 版本是 FMI 标准的一个重要更新,引入了许多新技术特性,解决了复杂模型的共同仿真问题,支持更高级的应用。
论文提供了多个案例研究,展示了FMI在实际项目中的应用,例如汽车动力总成系统、航空电子设备、能源系统等,证明了FMI的有效性和灵活性。
为了方便大家获取更多工业仿真领域的学术研究,超算互联网上架了论文原文、编译了论文核心要点,中文译文,感兴趣的技术人员可登录超算互联网搜索“FMI”在线查阅。
Ilya推荐阅读 | 用于关系推理的简单神经网络模块
《A simple neural network modulefor relational reasoning》这篇论文主要介绍了一种新型的神经网络模块--关系网络(简称RNS),RNS作为一种简单、即插即用的模块,专门设计用于处理和理解复杂数据中的关系信息。
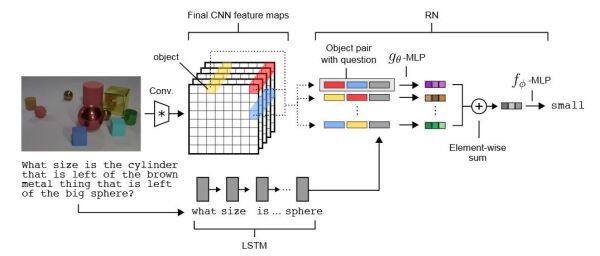
论文是由David Raposo等人在2017年发表,在深度学习与人工智能社群中引发了广泛瞩目。该论文凭借其在神经网络模块中实现关系推理的开创性工作,获得了高度评价,被 Ilya Sutskever 列入了他的27篇AI推荐阅读清单中。
为了方便大家获取Ilya Sutskever推荐的AI阅读清单,超算互联网上架了论文原文、编译了论文核心要点,中文译文,感兴趣的技术人员可扫描下方二维码或登录超算互联网搜索“Ilya推荐阅读”在线查阅。

中山大学&联想AI技术让连环画互动自然流畅
AutoStudio是一项由中山大学与联想合作研发多智能体协同框架,专为实现连环画或故事场景中角色与背景复杂互动时的一致性保持而设计。该系统通过三个基于大型语言模型(LLM)的智能体和一个基于扩散模型的图像生成器(Drawer)来工作,这些智能体负责处理用户交互、解析指令、管理布局以及最终生成高保真图像。

AutoStudio生成的两本漫画书
AutoStudio的主要亮点为:
扩散模型驱动的图像生成:使用先进的扩散模型作为“Drawer”,基于改进的布局生成高质量、细节丰富的图像。
并行UNet (P-UNet):引入了一种创新的并行UNet架构,该架构通过两个并行的交叉注意力模块(PTCA和PICA)分别增强了文本和图像嵌入的潜在主题特征,从而更好地处理多个主体的空间关系和特征表达。
主题初始化生成方法:为解决多ID绑定任务中的主体丢失和融合问题,引入了一种新的生成过程,通过单独生成主体的粗粒度特征,并将其映射到潜在空间进行局部替换,从而确保主体的一致性和准确性。
无需预定义指令:与传统方法需要预先设定所有生成指令不同,AutoStudio能够即时响应用户的不同指令,支持开放式故事生成和多主体多轮编辑,提高了灵活性和实用性。
高度一致性和编辑能力:在多轮交互式图像生成中,AutoStudio能够保持多个角色之间的一致性,并展现出优秀的编辑效果,这在对比其他系统(如Theatergen、MiniGemini、Intelligent Grimm和StoryDiffusion)时显得尤为突出。
论文链接:https://arxiv.org/abs/2406.01388

相关新闻
-
2025-04-18
超算&AI应用周报Vol.53 | 智谱6款GLM模型、Skywork-OR1、InternVL3、HiDream-I1上线
-
2025-04-18
机器化学家:算力=智力=研究力
-
2025-04-17
最佳实践Vol.35 | Wan2.1-ComfyUI实操:玩转AI视频,让文字、图片一键动起来
-
2025-04-17
科研更“晋”一步 - 国家超算互联网生态沙龙在太原顺利开展
-
2025-04-16
智谱GLM开源模型系列上线,32B性能比肩DeepSeek-R1

 津公网安备12011602300273号
津公网安备12011602300273号
 电子营业执照
电子营业执照