


新闻动态
导读
周报内容均源自海内外主流媒体报道、高校官网等公开信息梳理、相关领域优质KOL原创深度,主要包括超算快讯、前沿应用、学术研究等。
本期周报共5123个字,预计阅读时间20分钟,您可以重点专注以下内容。
超算AI快讯:
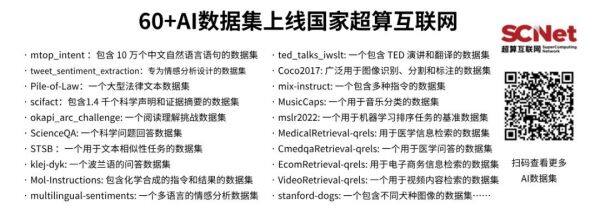
AI模型:roberta-large、stable-diffusion-safety-checker、bert-base-cased等
AI数据集:orca_dpo_pairs;okapi_arc_challenge、ScienceQA、Mol-Instructions等
HPC软件:国内首个HPC源码仓库上线,提供一站式科研解决方案;Gromacs 2024.2 版本、Abinit 10.0.7.1版本上线超算互联网
前沿应用:可视化界面工具SDWebUI上线,玩转5款AI视觉模型;Meta 3D Gen:一分钟生成高清3D内容,速度提升60倍
学术研究:Ilya推荐阅读 | 用于图像识别的深度残差学习;上交大推出首个开源、原生多模态生成大模型;Nature子刊,准确率达96%,AI从序列中预测蛋白-配体互作
一、超算AI快讯:
精选AI模型:
vit-base-patch16-224-in21k
vit-base-patch16-224-in21k是一个基于Vision Transformer (ViT)架构的深度学习模型,由 Google Research 开发,包含了大约1400万张和21000个类别的图像,使得模型能够学习到更广泛和更丰富的视觉特征。
roberta-large &xlm-roberta-large
roberta-large是一个大规模的预训练语言模型,旨在改进BERT模型的某些限制,提高其性能和泛化能力。该模型主要用于多种自然语言处理任务中如文本分类、语义相似度评估、信息抽取等。
xlm-roberta-large是roberta-large在多语言领域的扩展和增强版本,基于RoBERTa架构,经过多语言预训练,能够理解和生成多种语言的文本。
stable-diffusion-safety-checker
stable-diffusion-safety-checker是一款图像安全检测模型,主要用于检查和过滤由稳定扩散(Stable Diffusion)模型生成的图像,分析识别其中包含的不适当或敏感内容并进行阻止和标记。在使用如Stable Diffusion图像生成模型时,stable-diffusion-safety-checker可以作为一个重要的后处理步骤,以确保生成的内容适合所有用户。
bert-base-cased
bert-base-cased 是一个预训练的深度学习模型,该模型由 Google 在 2018 年发布,主要用于自然语言处理(NLP)任务。bert-base-cased 的特别之处在于对文本进行了大小写敏感的处理,即在预处理阶段保留了单词的大小写信息,这有助于某些特定领域的 NLP 任务,比如医学文献分析、命名实体识别等。
更多AI预训练模型可登录超算互联网(scnet.cn)搜索“AI模型仓库”或扫描下方二维码查看使用。

精选AI数据集:
orca_dpo_pairs
orca_dpo_pairs是一个大规模的对话数据集,包含了来自Orca项目的深度包对数据和来自 Orca 风格数据集 Open-Orca/OpenOrca 的 12k 个示例,主要用于多轮对话理解和生成的研究。
okapi_arc_challenge
okapi_arc_challenge数据集是信息检索和自然语言处理领域的一个重要资源,它是从微软的Bing搜索引擎的日志中提取出来的,包含了大量真实的用户查询和相关网页的信息,主要用于信息检索和自然语言处理领域的研究和开发。
Mol-Instructions
Mol-Instructions主要是用于大型语言模型的开放、大规模生物分子指令数据集,它为分子生成和理解自然语言指令之间的关系研究提供了宝贵的资源。Mol-Instructions 主要包括三个基本组件:面向分子的指令、以蛋白质为导向的指令、生物分子文本指令。
ScienceQA
ScienceQA是一个专为评估和推动多模态科学问答领域研究而设计的数据集,这个数据集旨在测试和推动深度学习模型在处理需要跨多种数据类型的复杂科学问题上的推理能力。
ScienceQA中包含大约21,208个多模态多项选择题,覆盖了中小学科学课程的内容,此外还包括对每个问题的解答过程的详细说明,能解释其推理过程,即所谓的“思维链”。
klej-dyk
klej-dyk是一个中型多模态数据集,是波兰语自然语言处理领域的一个重要资源,主要用于测试和训练机器学习模型在多项任务上的表现。它由近 5k 个问答对组成,且问题覆盖广泛,从科学、历史到流行文化等。每个问题都有一个明确的“是”或“否”的答案,以及解释答案正确性的上下文信息。这使得klej-dyk 成为评估模型在理解和推理方面能力的理想工具。
更多AI开源数据集可登录超算互联网(scnet.cn)搜索店铺“AI数据集”或扫描下方二维码查看使用。
国内首个HPC源码仓库上线,提供一站式科研解决方案
近日,国内HPC领域迎来新里程碑——首个高性能计算(HPC)源码仓库“源码之家”,正式上线国家超算互联网。该源码仓库上线,标志着国家超算互联网,正依托“源码、工具、应用”三层面布局,加速为全社会构建服务化、标准化的高性能计算服务环境。

“源码之家”涵盖经验证的超4000+可靠HPC源码商品,分为人工智能、工业仿真、气象环境、化学材料等11个类别,覆盖193款HPC软件。平台支持用户一键下载所需源码,并提供便捷辅助编译工具,极大简化HPC软件获取与部署流程。
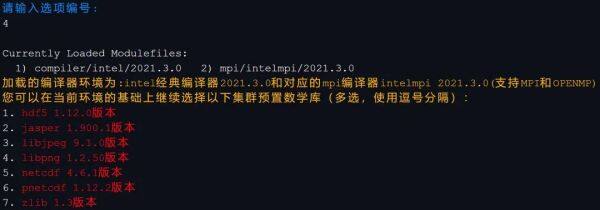
一键加载源码编译环境
接下来,“源码之家”将继续完善通用性协议支持,并针对不同种类、规模算例提供适配性源码,增加镜像支持、AI智能助手工具集等服务,提供HPC一站式科研解决方案。“源码之家”将向着国内最大最全的一体化高性能计算源码仓库目标持续建设,最终构建起面向全球开发者的综合性高性能计算源码生态社区。
Gromacs 2024.2 版本上线国家超算互联网
Gromacs是一种用于分子动力学模拟的软件包,Gromacs 2024.2 版本是Gromacs 的一次重要更新,发布于2024年5月10日。这个版本包含了从上一个版本 Gromacs 2024.1 以来的一系列变更和改进,同时也继承了自 Gromacs 2023.5 及更早版本的所有修复。
本周,Gromacs 2024.2 版本上线超算互联网,其主要的修复和更新点在于:
GPU缓冲区同步:修复了在邻居搜索步骤中,由于GPU缓冲区重新分配而导致的随机崩溃问题。
输入参数校验:增强了对-trestart和-dt参数的校验,确保它们的值合理。
文件读取错误处理:改进了对损坏的xtc文件的错误处理,避免了浮点异常错误。
Colvars输出文件备份:修正了Colvars输出文件备份次数,使其与Gromacs其他文件的备份行为一致.
NBLIB检测:NBLIB现在可以从用户设置的Lennard-Jones参数中检测组合规则。
非键合力计算优化:调整了NVIDIA GPU上非键合力计算的优化,修复了特定情况下的性能回归问题。

Abinit 10.0.7.1版本上线国家超算互联网
Abinit是一款开源的第一性原理计算软件,它常用于材料科学和凝聚态物理,计算固体和分子的电子结构和物性。其最新版本10.0是Abinit的一次重要更新,该版本带来了多项显著改进和新增功能,涵盖了从计算方法到软件工程的广泛领域。
本周,Abinit 10.0.7.1版本上线超算互联网,其新版本的主要亮点在于:
GW和RPA算法增强:实现了三次标度的实空间虚时算法,依赖于GreenX库中的最小最大时频网格,适用于非磁性材料且无自旋轨道耦合。这一实现提供了不同的流和算法,包括自一致性,可通过optdriver=6和指定gwr_task激活。
GPU移植:ABINIT v10.0提供了两种新的GPU实现——基于OpenMP和KOKKOS+CUDA,前者适用于NVIDIA和AMD加速器,后者仅限于NVIDIA加速器。这些实现要求使用兼容的编译器和库,如cuFFT、cuBLAS、cuSOLVER等,并提供了额外的关键字以供专家用户使用。
低尺度GW和RPA实现:依赖于GreenX库中的最小最大时频网格,适用于非磁性材料且无自旋轨道耦合,提供了自一致性在内的不同算法和流程。
输入变量的变更和移除:在DFPT中,输入变量rfasr被asr和chneut替代。与拉曼计算相关的输入变量rf1atpol, rf1dir, rf1elfd和rf1phon等被移除,由rf2_XXX变量取代。

二、前沿应用:
超算互联网上线可视化界面工具SDWebUI,玩转5款AI视觉模型
本周,超算互联网上线一款可视化界面AI工具SDWebUI(Stable Diffusion WebUI),用户可以切换和加载不同的Stable Diffusion模型,通过输入文本提示(Prompt),调整步骤数(Steps)和其他参数,如分辨率,来控制生成图像的质量和速度,生成各种风格和特征的图像。
目前,超算互联网的SDWebUI工具已加载5款AI模型,这些模型经过特定数据集的训练和优化,能够生成高质量的图像,模型亮点与实测效果图如下:
AnythingV5_v5PrtRE
这是一款功能强大且适应性广的图像生成模型,除了生成二次元漫画风格图外,对于肖像、风景、动物、卡通、科幻等风格也具有较强的适用性,是一个比较通用的模型。

生成数据:a girl,solo,flower,long hair,outdoors,school uniform,looking up,listening to music,black hair, sunlight, white shirt,upper body,from side,pink flower,brown hair,blue sky,depth of field.Steps: 25, Sampler: DPM++ 2M, Schedule type: Karras
Chilloutmix-Ni-pruned-fp32-fix
ChilloutMix目前共有六个版本,Chilloutmix_Ni-pruned-fp32-fix是最新版模型,ChilloutMix擅长生成具有日韩真人与动漫风格的图像,其特点是能够创造出高度真实感的图像,同时保持了一定的艺术风格和表现力。

生成数据:realistic, portrait of a girl,AI language model, silver hair,question answering,smart, kind, energetic, cheerful, creative, with sparkling eyes and a contagious smile, ,information providing, conversation engaging, wide range of topics, accurate responses, helpful responses, knowledgeable, reliable, friendly, intelligent,sleek and futuristic design elements, and a complex network of circuits and processors. Steps: 30, Sampler: DPM++ SDE, Schedule type: Automatic
majicmixRealistic_v6
模型在生成写实风格的图像方面表现出色,适合于高质量写实风格图像的应用场景,如人物肖像、风景、动物、科技和建筑图像。

生成数据:medium shot of detailed planetary explorer of harsh alien worlds cinematic shot on canon 5d ultra realistic Darek Zabrocki, Neil Blevins, Cedric Peyravernay, sci-fi atmosphere.Steps: 25, Sampler: DPM++ 2M, Schedule type: Karras
SDXL_ArienMixXL_V4.5
基于SDXL 1.0大模型进行定向微调的亚洲人像模型,擅长生成具有东方美感的写实风格图像。

生成数据:The image showcases a close-up portrait of a young woman with an ethereal appearance. She possesses long, dark hair that cascades down her shoulders and is adorned with what seems to be a sheer scarf or veil blending into the background. Her complexion is impeccable, complemented by subtle makeup featuring earthy tones on her eyelids and a soft peach hue on her lips. She rests her face gently in her hand, exuding serenity and poise.Steps: 50, Sampler: DPM++ 3M SDE, Schedule type: Karras
SDXL_base_1.0
Stable Diffusion框架下的一款基础模型,主要用于生成和修改基于文本提示的图像。

生成数据:Comic style,a superhero emerges triumphantly from the rubble, cape billowing behind him as he greets the dazzling metropolis he just saved from evil.Steps: 20, Sampler: DPM++ SDE, Schedule type: Karras
感兴趣的用户可登录scnet.cn搜索“SDWebUI”一键实测体验。另外,我们还建立了AI应用实测交流群,欢迎扫码备注【交流】入群探讨各类技术问题、分享应用效果图。

Meta 3D Gen:一分钟生成高清3D内容,速度提升60倍
7月3日,Meta推出了3D内容生成模型3D Gen,能够实现1分钟内的端到端生成,从文本直出高质量3D内容。不仅纹理清晰、形态逼真自然,而且生成速度比其他替代方案加快了3-60倍。
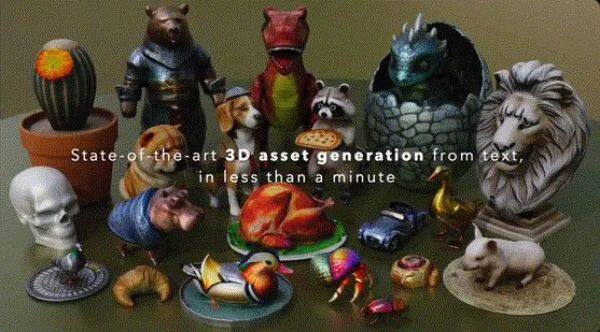
其核心亮点为:
物理渲染支持:生成的3D内容不仅包含高分辨率的纹理,还使用了基于物理的渲染(PBR)材质,在视觉上更加逼真和细腻。
多阶段优化:3D Gen的工作流程包括从文本生成2D视图,再到3D Mesh的重建和纹理优化,以及最终的纹理融合和增强,确保生成内容的细节和视觉效果。
骨骼装配兼容性:生成的3D内容可以与其他工具配合,安装骨骼结构,使其能够进行动态模拟。(量子位)
内容链接:
https://mp.weixin.qq.com/s/_Xe2MM4SZqMQ1rCiT352dw
三、学术研究:
Ilya推荐阅读 | 用于图像识别的深度残差学习
《Deep Residual Learning for Image Recognition》是由何恺明(Kaiming He)、张祥雨(Xiangyu Zhang)、任少卿(Shaoqing Ren)和孙剑(Jian Sun)四位作者于2015年发表的一篇关于深度学习的重要论文,文章提出了ResNet(残差网络),展示了一种通过残差连接解决深层神经网络训练难题的方法。
ResNet的提出极大地推动了深度学习领域的发展,特别是对于图像识别和相关计算机视觉任务,它成为了许多后续研究的基础架构。该论文因其创新性和影响力,荣获了CVPR 2016的最佳论文奖,被 Ilya Sutskever列入了他的27篇AI推荐阅读清单中。
为了方便大家获取Ilya Sutskever推荐的AI阅读清单,超算互联网上架了论文原文、编译了论文核心要点,中文译文,感兴趣的技术人员可扫描下方二维码或登录超算互联网搜索“Ilya推荐阅读”在线查阅。

首个开源、原生多模态生成大模型:一键生成 「煎鸡蛋」图文菜谱
近日,由上海交通大学GAIR实验室推出一项重大创新成果——Anole模型,它是全球首个完全开源、自回归、原生训练的大型多模态模型,能够在文本和图像之间自由转换和生成,无需依赖复杂扩散模型。

Anole模型的主要功能亮点包括:
图文生成能力:Anole能够根据文本指令生成高质量的图像,并附带相关的文本描述。例如,它可以演示制作煎蛋的每一步骤,不仅提供图片,还有详细的文字说明。
高效微调技术:通过创新的局部微调方法,仅需调整不到40m的参数,便能在短时间内激活Chameleon模型的图像生成能力,显著降低开发和实验门槛。
少即是多的微调数据:仅用约6,000张精心挑选的图像数据集进行微调,就能有效激发Chameleon的图像生成能力,展示了恢复复杂功能的高效率。
图文交互能力:除了基本的文本生成和多模态理解,Anole还展现出出色的图文交错生成能力,能够根据指令生成包含图像和文本的复合内容,如一张纸上写着“Anole”并画有Anole的图像,或描绘三个随机颜色和字母的立方体堆叠在桌上的场景。(机器之心)
论文链接:https://arxiv.org/abs/2405.09818
Nature子刊,准确率达96%,AI从序列中预测蛋白-配体互作
近期,莫纳什大学和格里菲斯大学的研究者们开发了一款结合物理化学约束的框架--PSICHIC,它的独特之处在于能够直接从蛋白质的氨基酸序列数据中解码出蛋白质-配体相互作用的指纹,而无需依赖高分辨率的蛋白质结构信息。
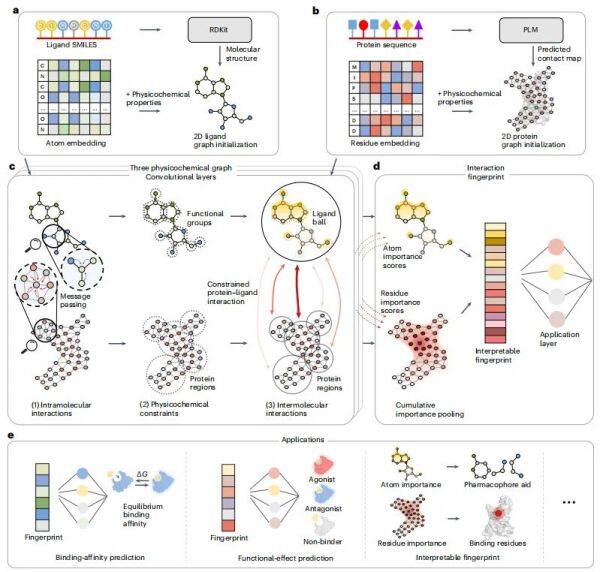
图示:PSICHIC 概述
PSICHIC的主要亮点为:
先进性能:PSICHIC在预测蛋白质-配体结合亲和力方面,与基于结构的领先方法相比,不仅保持了相当的性能,甚至在某些情况下超越了它们。即使在没有高分辨率结构数据的情况下,也能保持高预测精度。
功能效应预测:PSICHIC在预测功能效应方面展现出高达96%的准确率,这在现有的计算方法中是一个突出成就。
结合位点识别:PSICHIC能够准确识别参与相互作用的蛋白质残基和配体原子,帮助揭示蛋白质-配体相互作用的选择性因素。
虚拟筛选与选择性分析:PSICHIC被用于虚拟筛选候选药物,并分析配体在不同蛋白质亚型间的结合选择性,成功筛选出一种新型腺苷A1受体激动剂。
该研究以「Physicochemical graph neural network for learning protein–ligand interaction fingerprints from sequence data」为题,于 2024年6月17日发布在《Nature Machine Intelligence》(ScienceAI)
论文链接:https://www.nature.com/articles/s42256-024-00847-1

相关新闻
-
2025-04-18
超算&AI应用周报Vol.53 | 智谱6款GLM模型、Skywork-OR1、InternVL3、HiDream-I1上线
-
2025-04-18
机器化学家:算力=智力=研究力
-
2025-04-17
最佳实践Vol.35 | Wan2.1-ComfyUI实操:玩转AI视频,让文字、图片一键动起来
-
2025-04-17
科研更“晋”一步 - 国家超算互联网生态沙龙在太原顺利开展
-
2025-04-16
智谱GLM开源模型系列上线,32B性能比肩DeepSeek-R1

 津公网安备12011602300273号
津公网安备12011602300273号
 电子营业执照
电子营业执照