本期周报共4813字,预计阅读时间21分钟,您可以重点专注以下内容。FLUX.1-schnell上线超算互联网,支持一键试用;科学计算软件CREST 3.0.1版本、GNU Octave 9.2.0版本上线超算互联网;最佳实践Vol.05 | 如何设置并行参数提升ABINIT计算效率;OpenAI官宣API支持结构化输出,JSON准确率100%;亚马逊升级AI图像生成器Titan Image Generator v2,支持参考图像“引导” 生成作品;清华、上交等联合构建面向糖尿病诊疗的全球首个多模态模型,登 Nature 子刊;北大团队领衔开发AI框架提升蛋白复合体结构预测精准度,登Nature子刊;北大、斯坦福、牛津等大学联合推出空间大模型SpatialBot
FLUX.1-schnell上线超算互联网,支持一键试用近日,Stable Diffusion 作者之一 Robin Rombach 官宣创业,成立了新公司「Black Forest Labs」(黑森林实验室),并推出了最新文生图模型FLUX.1。FLUX.1包含了三个变体模型:Pro 版本、dev 版本和速度最快的 schnell 版本。prompt:The Paris stadium and runway have been painted purple, and athletes wore purple clothes while running with their backs facing the audience. There is an Eiffel Tower in the distance, and the scene has anime aesthetics and bright colors, creating a cheerful atmosphere. 8k
本周,FLUX.1-schnell版本上线超算互联网,支持一键试用。FLUX.1系列模型的技术特点包括:- 架构创新:采用了多模态和并行扩散Transformer的混合架构,这种架构整合了多种模态的信息处理能力,使得模型能够更好地理解和生成复杂的图像内容。
- Rectified flow+Transformer方法:继承和发展了研究团队在Stability AI任职期间提出的Rectified flow+Transformer方法,这有助于提升模型在图像生成任务中的表现。
- 并行注意力层:并行注意力层的使用,提高了模型的计算效率,使得模型能够在不牺牲生成质量的前提下,显著加快图像生成的速度。
8月6日,智谱AI宣布开源了视频生成模型CogVideoX,包含了不同尺寸大小的模型,其中的CogVideoX-2B版本具备处理226个token的提示词能力,可生成6秒长、8帧/秒、720x480分辨率的视频。下面,我们来看看CogVideoX官方生成的示例视频。prompt:A detailed wooden toy ship with intricately carved masts and sails is seen gliding smoothly over a plush, blue carpet that mimics the waves of the sea. The ship's hull is painted a rich brown, with tiny windows. The carpet, soft and textured, provides a perfect backdrop, resembling an oceanic expanse. Surrounding the ship are various other toys and children's items, hinting at a playful environment. The scene captures the innocence and imagination of childhood, with the toy ship's journey symbolizing endless adventures in a whimsical, indoor setting.
本周,CogVideoX-2B上线超算互联网,支持快速免费下载权重文件,其主要特点为:- 三维变分自编码器结构(3D VAE):该模型使用3D VAE压缩视频的空间和时间维度,实现了视频数据的有效压缩和高质量的重建。
- 专家Transformer架构:模型利用专家Transformer架构处理压缩后的视频潜在空间和文本嵌入,实现文本与视频内容的有效融合。
- 高质量数据筛选:团队开发了负面标签系统和过滤器,用于识别和排除低质量视频数据,确保模型训练数据的质量。
科学计算软件CREST 3.0.1版本上线超算互联网CREST是一款用于计算化学和分子模拟的工具,专门用于构象搜索和全局优化任务。它结合了多种先进的算法,能够处理复杂的分子体系,提供高精度的计算结果。本周,CREST的最新版本3.0.1上线超算互联网,相较于之前的版本,本次主要更新在于:- 构象搜索算法:新版本在构象搜索算法上进行了优化,使得搜索过程更快速、更高效,能够处理更大规模的分子体系。
- 蒙特卡罗方法增强:增强的蒙特卡罗方法提高了随机搜索的效果,确保更全面的覆盖势能面。
- QM/MM 集成:支持量子力学/分子力学(QM/MM)多层次计算方法,能够在同一计算中结合不同层次的精度需求。
- 多尺度方法:引入多尺度计算方法,支持从半经验方法到从头算方法的无缝集成。
- 并行计算优化:进一步优化了并行计算性能,充分利用多核 CPU 和 GPU 加速器,提高计算效率。
科学计算软件GNU Octave 9.2.0版本上线超算互联网GNU Octave是一款开源的高级编程语言,主要用于数值计算。它提供了一个方便的命令行界面,类似于 MATLAB,适用于数学、科学研究和工程等领域。本周,GNU Octave 最新版本 9.2.0上线超算互联网,该版本引入了几个重要的更新和改进:- HiDPI 缩放改进:改进了对 HiDPI 缩放的支持,提升了在高分辨率显示器上的视觉体验。
- Qt6 支持:针对新版 Qt6 进行了多项修复,Windows 二进制文件现在支持使用 Qt6 构建。
- 增强 Matlab 兼容性:提高了多个函数与 Matlab 的兼容性,包括 mad、mode、linspace、logspace、normalize 和 cov。这些更改确保在使用 Octave 作为 Matlab 替代品时的行为一致性 。
二、前沿应用:
最佳实践Vol.05 | 如何设置并行参数提升ABINIT计算效率
超算互联网推出“超链接”最佳实践系列专题,旨在通过HPC软件、AI模型的应用链接科研工作者与AI开发者,分享超算实践经验、模型推理实测教程。如果您有关于超算应用的创新研究成果、高效计算方法、最佳实践案例或者独到见解想要分享,欢迎投稿或联系报道。
本篇为“超链接”系列专题的第5篇最佳实践文章,主要探讨了ABINIT软件在处理大规模计算任务时面临的挑战,包括内存限制、计算效率下降、并行化复杂度增加以及收敛性问题。针对这些挑战,文章介绍了ABINIT的KGB并行化策略,这是一种针对波矢点网格块的并行计算方法,旨在优化计算效率和收敛性。作者通过细致的参数调整和优化,展示了如何在不牺牲计算精度的前提下,大幅提高计算效率的方法。特别值得关注的是,文中讨论了 MPI 和 OpenMP 混合并行模式的实施细节,以及如何平衡计算速度与收敛性,为科研人员提供了一套实用的指南。OpenAI官宣API支持结构化输出,JSON准确率100%
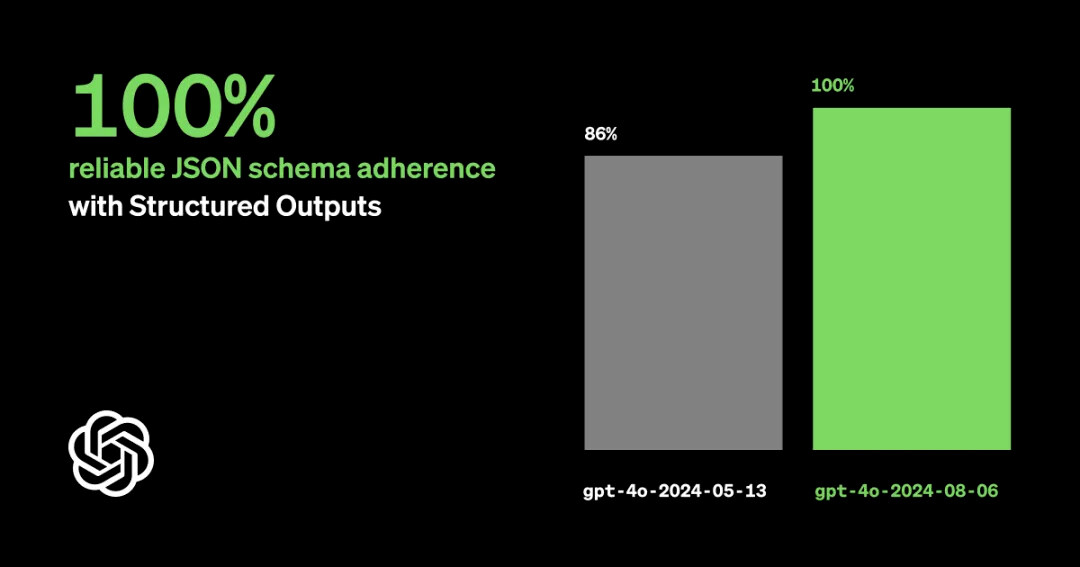
8月6日,OpenAI宣布了一项重大更新,在GPT-4o的最新版本中新增了对JSON结构化输出的支持,这解决了先前大型语言模型(LLM)输出结果与JSON Schema不一致的问题,大大降低了开发者为获得理想输出而需投入的时间和精力。此功能确保模型生成的数据严格符合预先设定的JSON Schema,从而显著提升了输出数据的准确性和可靠性。本次最新版模型“GPT-4o-2024-08-06”的更新内容包括:- 结构化输出功能:引入了JSON模式支持,确保模型输出符合开发者定义的结构,提高了输出的可靠性和安全性。
- 性能提升:输入和输出效率分别提高了50%和33%,使得API成本有效降低。模型的token输出上限也从4k增加到了16k,进一步增强了实用性。
- 技术原理:采用了约束解码技术,将JSON Schema转换为上下文无关文法,确保输出的Token始终符合Schema,减少了延迟并提高了准确性。
- 原生SDK支持:OpenAI的Python和Node SDK已更新,原生支持结构化输出,简化了开发流程。(OpenAI)
https://openai.com/index/introducing-structured-outputs-in-the-api/亚马逊升级AI图像生成器Titan Image Generator v2,支持参考图像“引导” 生成作品
8月7日,亚马逊推出了其内部开发的图像生成 AI 模型 Titan Image Generator 的升级版本 ——Titan Image Generator v2,该模型引入了一系列增强功能,进一步提升了图像生成的质量。本次Titan Image Generator新版本V2的亮点在于:- 图像调节:通过提供参考图像和文本提示,指导图像生成器遵循特定的布局和结构,实现更精细的控制。此功能支持Canny边缘和分割两种模式,前者用于提取图像边缘指导生成,后者则提供更精细的区域和对象控制。
- 调色板指导:通过提供十六进制颜色代码列表,精确控制生成图像的调色板,确保图像色彩与品牌标准保持一致。
- 背景移除:智能地从图像中移除背景,即使面对复杂的多重对象场景,也能准确分割并保留前景对象,为图像合成和编辑提供便利。
- 主题一致性:用户可以通过微调模型,确保生成的图像中保留特定主题的特征,使得生成的图像能够自然地融入多样化的背景中,保持品牌风格或特定视觉主题的一致性。(亚马逊AWS)
https://aws.amazon.com/cn/blogs/china/amazon-titan-image-generator-v2-is-now-available-in-amazon-bedrock/三、学术研究:
清华、上交等联合构建面向糖尿病诊疗的全球首个多模态模型,登 Nature 子刊
糖尿病是全球上升最快的主要慢性病,其中,糖尿病视网膜病变(DR)作为最常见的糖尿病特异并发症,影响了30%-40%的糖尿病患者,严重情况下会造成失明。近日,由清华大学、上海交通大学、新加坡国立大学及新加坡国家眼科中心等机构的专家团队共同研发了一款全球首个面向糖尿病诊疗的视觉-大语言模型的多模态集成智能系统DeepDR-LLM,该系统结合了深度学习的眼底图像分析技术和大语言模型,旨在为基层医生提供糖尿病管理意见和糖尿病视网膜病变(DR)的辅助诊断。DeepDR-LLM 作为一款全球首个面向糖尿病诊疗的多模态模型,其研究亮点在于:- 创新的协同优化技术:研究团队开发了融合适配器和低秩自适应的协同优化技术,使得系统能够在不更新所有参数的情况下,针对糖尿病管理相关知识进行高效的微调,从而增强了大语言模型(LLM)生成糖尿病管理建议的能力。
- 深度学习的眼底图像分析:DeepDR-Transformer模块利用Transformer模型架构,针对超过50万张眼底图像进行了训练,实现了眼底影像的质量检测、病变分割和糖尿病视网膜病变(DR)的分级诊断,精确度高。
相关研究成果于以「 Integrated image-based deep learning and language models for primary diabetes care」为题, 已发表于《Nature Medicine》。https://www.nature.com/articles/s41591-024-03139-8北大团队领衔开发AI框架提升蛋白复合体结构预测精准度,登Nature子刊
近日,北京大学、北京昌平实验室以及哈佛大学的研究团队提出了一项名为ColabDock的创新性通用框架,该框架旨在通过整合深度学习结构预测模型与实验约束来提升蛋白质复合物结构预测的精确度。ColabDock 的关键特点在于其无需大规模再训练或微调即可利用多种实验约束的能力,解决了现有蛋白质结构预测模型在考虑实验约束时精度受限的问题。在性能方面,ColabDock 使用 AlphaFold2 作为结构预测模型,其表现优于 HADDOCK 和 ClusPro,不仅在复杂的结构预测上,而且在抗体-抗原界面预测中也显示出优越性。然而,ColabDock 也存在局限性,例如它目前只能处理距离小于 22 Å 的约束,这限制了其在某些实验数据上的适用性。此外,对于超过 1,200 个残基的复合物,由于内存限制,ColabDock 的运行效率会降低。该研究以「Integrated structure prediction of protein–protein docking with experimental restraints using ColabDock」为题,于 2024 年 8 月 5 日发布在《Nature Machine Intelligence》。https://www.nature.com/articles/s42256-024-00873-z浙大研发化学逆合成预测模型,准确率达60.8%
近日,浙江大学的研究团队提出了一种创新的逆合成预测模型——EditRetro,该模型将逆合成问题重新定义为分子字符串编辑任务,通过迭代编辑目标分子串来生成前体化合物,这种方法能够实现高质量和多样化的预测。图:所提出的基于分子串的逆合成的 EditRetro 方法的示意图- 高效的非自回归解码:模型采用非自回归解码器,即使在预测编辑操作时结合了额外的解码器,也能在每个解码器内并行执行编辑操作。
- Transformer架构:EditRetro基于Transformer模型,包含一个编码器和三个解码器,分别负责序列重新定位、占位符插入和标记插入,能够处理复杂的化学反应模式。
- 优秀的预测性能:在标准逆合成数据集USPTO-50K上,EditRetro的top-1精确匹配准确率达到了60.8%,在更大、更复杂的USPTO-FULL数据集上,top-1准确率也有52.2%。
- 多样化的预测:EditRetro通过重新定位采样和序列增强策略,能够生成多样化的逆合成路径,提高了预测的准确性和多样性。
相关研究以「Retrosynthesis prediction with an iterative string editing model」为题,于 7 月 30 日发布在《Nature Communications》上。https://www.nature.com/articles/s41467-024-50617-1北大、斯坦福、牛津等大学联合推出空间大模型SpatialBot
近日,来自斯坦福、上交、智源、北大、牛津、东大的研究者开发了一种名为SpatialBot的空间大模型。该模型旨在使多模态大模型能够理解深度和空间,尤其聚焦于通用场景和具身智能场景下的空间理解。图:三个层次的 SpatialQA,逐步引导模型理解深度图、使用深度信息- 深度理解:SpatialBot能够处理RGB-D数据,即RGB图像和深度信息的结合,这使得它能够在视觉上理解三维空间,准确获取物体和机械爪的深度值,这是GPT-4o等现有模型所不具备的能力。
- 层级化训练数据:SpatialBot通过SpatialQA数据集进行训练,该数据集包含三个层次的任务设计,从低级到高级逐步引导模型理解深度图和使用深度信息。
- 精准深度信息获取:SpatialBot可以调用DepthAPI来获取准确的深度信息,当模型认为有必要时,它会通过调用API以点的形式获取具体位置的深度值。
- 深度图编码:为了适应不同场景的深度需求,SpatialBot使用了统一的深度图编码方式,使用以毫米为单位的metric depth,范围从1mm到131m,这确保了从室内到室外各种场景的适用性和精度。
https://arxiv.org/abs/2406.13642

















 津公网安备12011602300273号
津公网安备12011602300273号
 电子营业执照
电子营业执照