

新闻动态
导读
周报内容均源自海内外主流媒体报道、高校官网等公开信息梳理、相关领域优质KOL原创深度,主要包括超算快讯、前沿应用、学术研究等。
本期周报共4724字,预计阅读时间18分钟,您可以重点专注以下内容。
超算AI快讯:
52个AI模型:bert-base-uncased、all-MiniLM-L6-v2、resnet50.a1_in1k、speaker-diarization-3.1等;
60个AI数据集:mtop_intent、tweet_sentiment_extraction、pile-of-law、scifact、stsb等;
HPC软件:AmberTools、PAML;
前沿应用:模拟5亿年自然进化史,全新蛋白质大模型ESM3诞生;自回归模型STAR--2.9秒快速生成高质量图像;
学术研究:世界经济论坛发布《2024年十大新兴技术报告》;哈佛&MIT联手,打造病理学界AI超级副驾PathChat
一、超算AI快讯:
本周,超算互联网上线52个AI预训练模型,60个AI数据集,涵盖了NLP 应用首选模型BERT、计算机视觉领域的基石模型ResNet,以及广泛用于中文自然语言、大型法律文本、科学问题回答、医学问答等模型训练的AI开源数据集。超算互联网为开发者提供一站式的AI开发解决方案,可轻松构建、部署和运行各种AI应用,包括自然语言处理、计算机视觉、语音识别等。
精选AI模型:
bert-base-uncased
bert-base-uncased是一个预训练自然语言处理模型,是基于Transformer 架构的 BERT (Bidirectional Encoder Representations from Transformers) 模型的基本版本。这个模型在自然语言处理领域被广泛使用,可以用于各种下游任务,如文本分类、命名实体识别、情感分析等。
all-MiniLM-L6-v2
all-MiniLM-L6-v2 是一个预训练的自然语言处理模型,属于MiniLM 系列。MiniLM 模型是由微软亚洲研究院(Microsoft Research Asia)开发,设计用来提供快速的语言理解能力,同时保持较小的模型尺寸,使其适合在资源有限的环境中使用。这个模型在处理速度和性能之间做了权衡,适用于需要快速响应的应用场景。
resnet50.a1_in1k
resnet50.a1_in1k 是一个深度学习模型,它是一个经过预训练ResNet50 模型,专为 ImageNet-1k 数据集进行了优化。ResNet50是一个深度卷积神经网络,它在ImageNet大规模视觉识别挑战赛中取得了很好的成绩。这个模型可以用于图像分类、目标检测、图像分割、风格迁移等任务,是计算机视觉领域的基石之一。
使用预训练的 ResNet50 模型,研究人员和开发者可以在不从头开始训练的情况下,快速地开始处理新的图像数据集,并通过微调(Fine-tuning)来适应特定的任务和数据集。
speaker-diarization-3.1
speaker-diarization-3.1 是一个用于说话人分割(speaker diarization)的深度学习模型。说话人分割是语音处理中的一个任务,它旨在将音频文件中的说话人进行分离,即确定音频中的每个部分是由哪个说话人说的。说话人识别技术通常用于会议记录、电话通话分析、安全监控等应用,它能够区分不同的说话人并标注他们的话语。
更多AI预训练模型可登录超算互联网(scnet.cn)搜索“AI模型仓库”或扫描下方二维码查看使用。

精选AI数据集:
mtop_intent
mtop_intent 数据集包含 10 万个中文自然语言语句,每个语句都标注了对应的意图标签,用于训练和评估中文意图识别模型。
tweet_sentiment_extraction
tweet_sentiment_extraction是一个专为情感分析设计的数据集,主要用于识别推文中支持特定情感分类的内容。这个数据集包含大量推文及其对应的情感标签,用于训练和评估情感分析模型。
pile-of-law
Pile-of-Law 是一个大型法律文本数据集。该数据集旨在为了提供一个基于法律的数据过滤方法,以此来解决大型语言模型在预处理材料时可能遇到的偏见、不当内容、版权问题以及隐私信息泄露等问题。
据 Papers With Code 网站所述,“Pile of Law” 数据集可以用于评估法律和行政环境中的数据净化规范。目前,这个数据集支持 TensorFlow、PyTorch 和 JAX 等多种框架。
scifact
scifact 是一个包含1.4 千个科学声明和证据摘要的数据集,带真实性标签和理由注释,可用于评估机器理解科学文本的能力。
stsb
stsb 是一个用于文本相似性任务的数据集,由斯坦福大学人工智能实验室发布,包含5,749对句子,每一对句子都有一个人类主观标注的相似度得分,范围从1到5,其中1表示完全不相似,5表示完全相似。这个数据集被广泛用于训练和测试用于句子相似度评估的模型,是自然语言处理领域的一个重要基准数据集。
更多AI开源数据集可登录超算互联网(scnet.cn)搜索店铺“AI数据集”或扫描下方二维码查看使用。

科学计算软件AmberTools上线超算互联网
AmberTools是一个用于分子模拟和计算化学的软件套件,它提供了一系列工具和库,用于模拟和分析生物分子的结构和性质,包括分子动力学模拟、构象搜索、分子对接和药物设计等。
其主要功能特点有:
分子动力学模拟:AmberTools提供了强大的分子动力学模拟功能,可以模拟生物分子在不同条件下的动态行为。它可以模拟溶液中的分子、蛋白质和核酸的结构和运动,以及分子与其他分子之间的相互作用。
构象搜索:AmberTools提供了多种构象搜索算法,可以搜索和优化分子的构象空间。它可以寻找分子的最稳定构象,帮助研究者理解分子的结构和性质。
分子对接:AmberTools支持分子对接研究,可以模拟和分析分子之间的相互作用。它可以预测分子之间的结合能力和结合位点,为药物设计和生物分子相互作用研究提供基础。
药物设计:AmberTools提供了多种药物设计工具,可以辅助研究者设计新的药物分子。它可以预测分子的生物活性、毒性和药代动力学性质,为药物研发提供支持。
结果分析:AmberTools提供了多种结果分析和可视化工具,帮助研究者解释和理解分子模拟的结果。它可以计算分子的能量、结构特征和动力学参数,为分子模拟研究提供全面的分析和解读。
本周,Ambertools多个版本上线超算互联网,您可登录scnet.cn搜索“AmberTools”或扫描下方二维码查看使用。

科学计算软件PAML上线超算互联网
PAML是一款基于最大似然法的系统发育分析软件。它由英国剑桥大学的ziheng Yang教授开发,旨在为生物学家提供一个强大的工具,用于分析DNA序列数据,推断物种之间的进化关系。PAML能够处理复杂的进化模型,包括不同的核苷酸替换模型、速率异质性模型以及基因流模型等。软件支持多种数据格式,并且可以输出详尽的分析结果,包括树状图、参数估计和置信区间等。
本周,PAML三个版本上架超算互联网,分别为:paml v4.10.5版本、paml v4.10.6版本和paml v4.10.7版本。其主要功能特点为:
模型多样性:支持多种核苷酸替换模型,包括单参数、双参数和多参数模型。
速率异质性:可以处理不同位点间速率异质性,如使用Gamma分布或Ingoing模型。
基因流分析:能够分析基因流对进化的影响,提供相关参数的估计。
树状图构建:提供多种树状图构建方法,如邻接法、最大似然法等。
数据分析:支持对DNA序列数据的深入分析,包括正选择、负选择和中性选择的检测。
您可登录scnet.cn搜索“PAML”或扫描下方二维码查看使用。

二、前沿应用:
模拟5亿年自然进化史,全新蛋白质大模型ESM3诞生
能抗衡AlphaFold 3的生命科学大模型终于出现了。近日,初创公司Evolutionary Scale AI发布了98B参数蛋白质语言模型ESM3,与仅专注于模拟单一生物分子属性的模型不同,ESM3能同时推理蛋白质的序列、结构和功能,这种多模态能力属于领域首创。
esmGFP的渲染图
其亮点主要体现在:
大规模训练与数据多样性:ESM3在训练上实现了前所未有的规模,数据量提升60倍,计算量提高25倍,训练集涵盖了27.8亿个自然界的多样化蛋白质,从微生物到深海生物,体现了广泛的生态和进化多样性。这使得模型能够学习到更深层次的生物规律。
模拟进化过程:通过在丰富多样的蛋白质数据上训练,ESM3能够模拟蛋白质随进化历程的变化,被喻为“进化模拟器”。
全对全预测生成:ESM3采用掩码语言模型目标,允许在序列、结构和功能上任意进行掩码和预测,意味着输入可以是这三种模态任意组合的部分或完全指定信息,为蛋白质设计带来灵活性和精确控制。
计算规模与技术创新:模型训练参数总量达到980亿,使用了超过10^24FLOPS的计算能力,展示了生命科学模型的计算密集型特征。
自优化与反馈循环:ESM3在训练完成后仍具备通过自我评估和结合湿实验结果进行持续优化的能力,类似于强化学习的迭代改进,确保生成结果与真实世界生物学数据保持一致。(新智元)
内容链接:https://mp.weixin.qq.com/s/GeAWZl28_zrKhrnLi52wNA
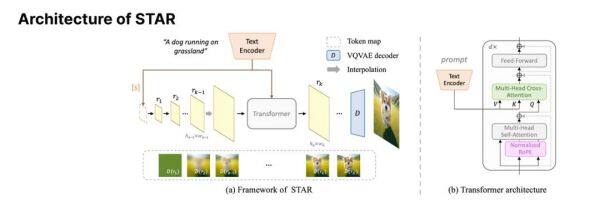
自回归模型STAR--2.9秒快速生成高质量图像
近期,一款2.9秒就可生成高质量图像的新型通用文生图模型STAR亮相,该模型采用自回归范式,在图像生成速度与质量上取得重大突破,性能超越当前流行的扩散模型。
其主要亮点为:
高速生成: STAR能够在仅仅2.9秒内生成512分辨率的高质量图像,这一速度远超包括SDXL在内的当前扩散模型,极大地提高了图像生成的效率。
卓越性能: 在生成图像的真实度、图文一致性及人类偏好方面,STAR均有优秀表现。它在FID(Fréchet Inception Distance)、CLIP score和ImageReward等评价指标上均取得了优异成绩,表明其生成图像的保真度高,与文本描述的贴合度好,且更符合人类的审美偏好。
文本引导增强: 通过将文本特征直接融入生成流程的起始阶段,并在每个Transformer层使用交叉注意力机制,STAR能更精细地根据文本指令生成图像,确保了生成图像与文本描述的高度一致性。
改进的位置编码: 引入的归一化旋转位置编码(Normalized RoPE)技术,有效解决了不同尺度图像生成中的位置编码难题,使得模型能更好地理解和处理不同尺度图像中的相对位置关系,同时不增加额外的训练参数,有利于提升模型在高分辨率图像生成上的能力。
高效训练策略: 先在低分辨率图像上进行大规模训练,然后在高分辨率图像上微调,这样的训练策略结合归一化位置编码,使模型能够快速收敛并生成高质量图像,降低了训练成本和时间。(STAR)
内容链接:https://krennic999.github.io/STAR/
三、学术研究:
超算互联网收录世界经济论坛《2024年十大新兴技术报告》,附原文、中文译文
世界经济论坛发布《2024年十大新兴技术报告》,重点介绍了未来三至五年内有望对世界产生积极影响的技术。十大新兴技术主要包括:人工智能促进科学发现(AI for scientific discovery)、 隐私增强技术(Privacy-enhancing technologies)、 智能超表面RIS(Reconfigurable intelligent surfaces)、高空平台基站(High-altitude platform stations)、通信感知一体化(Integrated sensing and communication)、建筑世界的沉浸式技术(Immersive technology for the built world)、弹性热学(Elastocalorics)、碳捕获微生物(Carbon-capturing microbes)、替代性牲畜饲料(Alternative livestock feeds)、移植基因组学(Genomics for transplants)。
本周,《2024年十大新兴技术报告》的英文原文和中文译文均已收录至超算互联网,感兴趣的技术人员可登录超算互联网搜索“2024年十大新兴技术报告”在线查阅。
哈佛&MIT联手,打造病理学界AI超级副驾“PathChat”
PathChat是一款由哈佛大学和MIT研究人员最新开发的针对人类病理学的创新性视觉语言通才AI助手。它作为一种视觉语言通才AI副驾,能够在理解病理图像及文本的基础上,对复杂的病理学查询提供精确回答。该研究通过与多种多模态视觉语言AI助手及GPT-4V进行对比,展示了PathChat在解决来自多样本源和疾病模型的病例多项选择诊断问题上的优越性能。
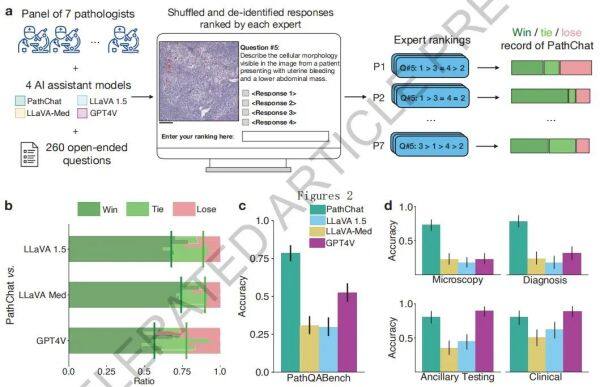
图示:开放式问题回答的表现
其主要特点为:
多模态处理能力:PathChat是一款多模态生成式AI助手,能够同时理解并处理视觉图像(如病理学显微图像)和自然语言输入,这是针对病理学领域特有需求的重大进步。
高度准确性:在多项选择诊断问题和开放式问题的评估中,PathChat展现了卓越的诊断准确性和响应质量,优于同类最佳的商业解决方案和公开测试的多模态大型语言模型(MLLM)。
灵活的交互性:支持交互式多轮对话,使得PathChat能够适应复杂的诊断情景,分析组织学图像中的显著形态细节,并就涉及病理学和生物医学背景知识的问题给出精准回答。
定制化与高效微调:基于一个自定义、经过微调的MLLM,该模型通过精心设计的数据集和大量问答轮次的微调,确保了对病理学领域专业内容的深入理解。
以上研究以「A Multimodal Generative AI Copilot for Human Pathology」为题,并于2024年6月12日发布在《Nature》上。
论文链接:https://www.nature.com/articles/s41586-024-07618-3

点击链接https://bvjoh3z2qoz.feishu.cn/docx/O1Cndurj0oFVUhx1bS9cjySinLf,进入HPC&AI应用知识库
相关新闻
-
2024-06-27
【超算前沿直播间】国产多相流仿真前沿技术及应用
-
2024-06-24
【超算前沿直播间】探索PWmat的无穷潜力
-
2024-06-22
超算&AI应用周报|阿里Qwen2、Little Tinies等5款大模型上线,多语言、动漫、卡通、手绘模型全支持
-
2024-06-20
「超」级「模」力,现在开SHOW!
-
2024-06-15
超算&AI应用周报|SD3 Medium、3款SDXL-1.0 ControlNet模型上线,提升多模态图像生成能力

