用户手册
>
平台使用
>
人工智能
>
Notebook
>
Notebook快速使用
>
镜像说明
提交训练任务前,请准备训练环境需要安装的镜像,以下镜像任选其一即可。
针对人工智能训练任务,平台提供了基于不同框架的基础镜像,此类镜像适合在平台上进行训练任务,能够获得更好的性能。如果平台提供的框架版本或Python版本不满足需求,请查看配置其他版本的框架或Python方法:
(1)平台镜像中有没有您需要的Torch、TensorFlow等框架的相应版本,如果有首选平台内置的镜像;
(2)如果平台中没有合适的Torch、TensorFlow等框架版本,那么查询自己的框架需要什么CUDA版本,比如PyTorch=1.9.0需要CUDA=11.1,那么可以选择Miniconda/CUDA=11.1的平台镜像,然后在镜像内安装自己需要的框架,免去安装cudatoolkit的麻烦;(平台内置的CUDA均带.h头文件,如有二次编译代码的需求更方便)
(3)如果以上条件都不满足,则可随便挑选一个Miniconda镜像,在开机后自行安装相关框架、CUDA、甚至其他版本的Python;
(4)若您需要使用其他Python版本(比如TensorFlow1.14必须3.6/3.7),那么可以使用Miniconda创建其他版本的Python虚拟环境。
Bash
# 构建一个虚拟环境名为:my-env,Python版本为3.7
conda create -n my-env python=3.7
# 更新bashrc中的环境变量
conda init bash && source /root/.bashrc
# 切换到创建的虚拟环境:my-env
conda activate my-env
# 验证
python平台针对常用的AIGC模型提供了模型镜像,方便用户在不同的环境中进行快速部署和迁移,确保在新的环境中能够准确重现原模型的功能和性能;若平台提供的模型镜像不能满足您的需求,您可以联系平台客服,我们会持续丰富模型内容。
| 序号 | 镜像 | 描述 |
|---|---|---|
| 1 | jupyterlab-langchain-chatllm:pytorch2.1.0-cuda12.1-py3.10-model | 基于Langchain与ChatGLM3-6B语言模型的本地问答 |
| 2 | jupyterlab-yolov5:pytorch2.2.0-py3.10-cuda12.1-model | 基于 YOLOv5 算法的多目标检测工具,用于提供高效、精确的目标识别功能 |
| 3 | jupyterlab-stable-diffusion-webui:pytorch2.2.0-py3.10-cuda12.1-model | 带 WebUI 的文生图工具,用于将文本输入生成高质量图像 |
| 4 | jupyterlab-bert-vits2:pytorch2.1.0-py3.10-cuda12.1-model | 基于Bert-Vits2的高级语音合成模型,用于生成高质量的自然语音 |
您可以在控制台的我的镜像页面中进行管理镜像,便于在不同任务中直接选择使用。
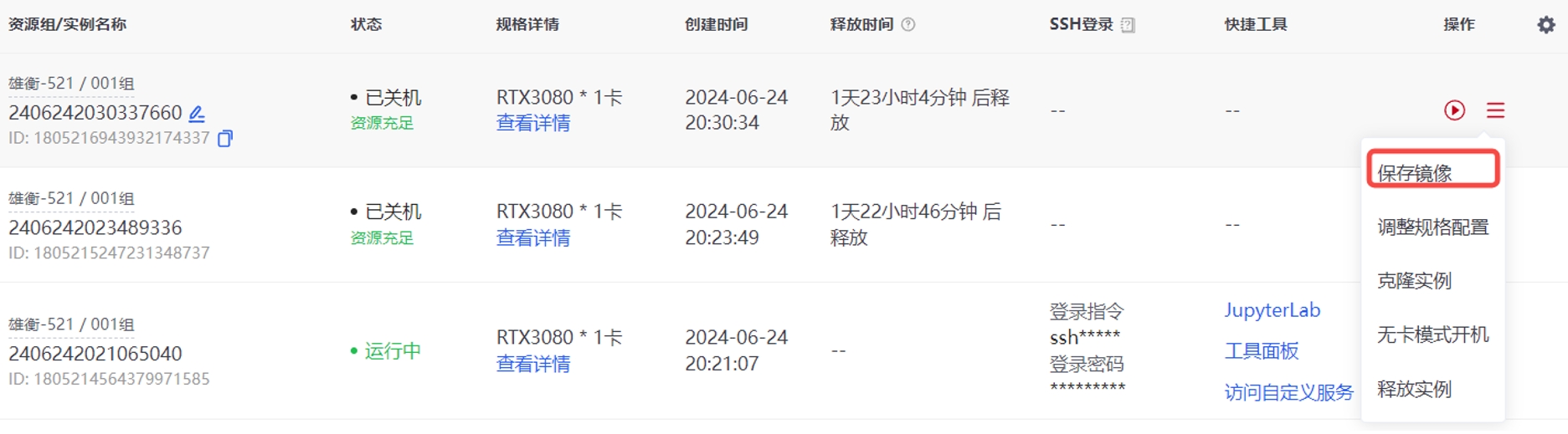
(1)保存镜像。在实例运行中或关机后,在更多操作中点击保存镜像,则可以将该实例的整个环境保存至我的镜像。
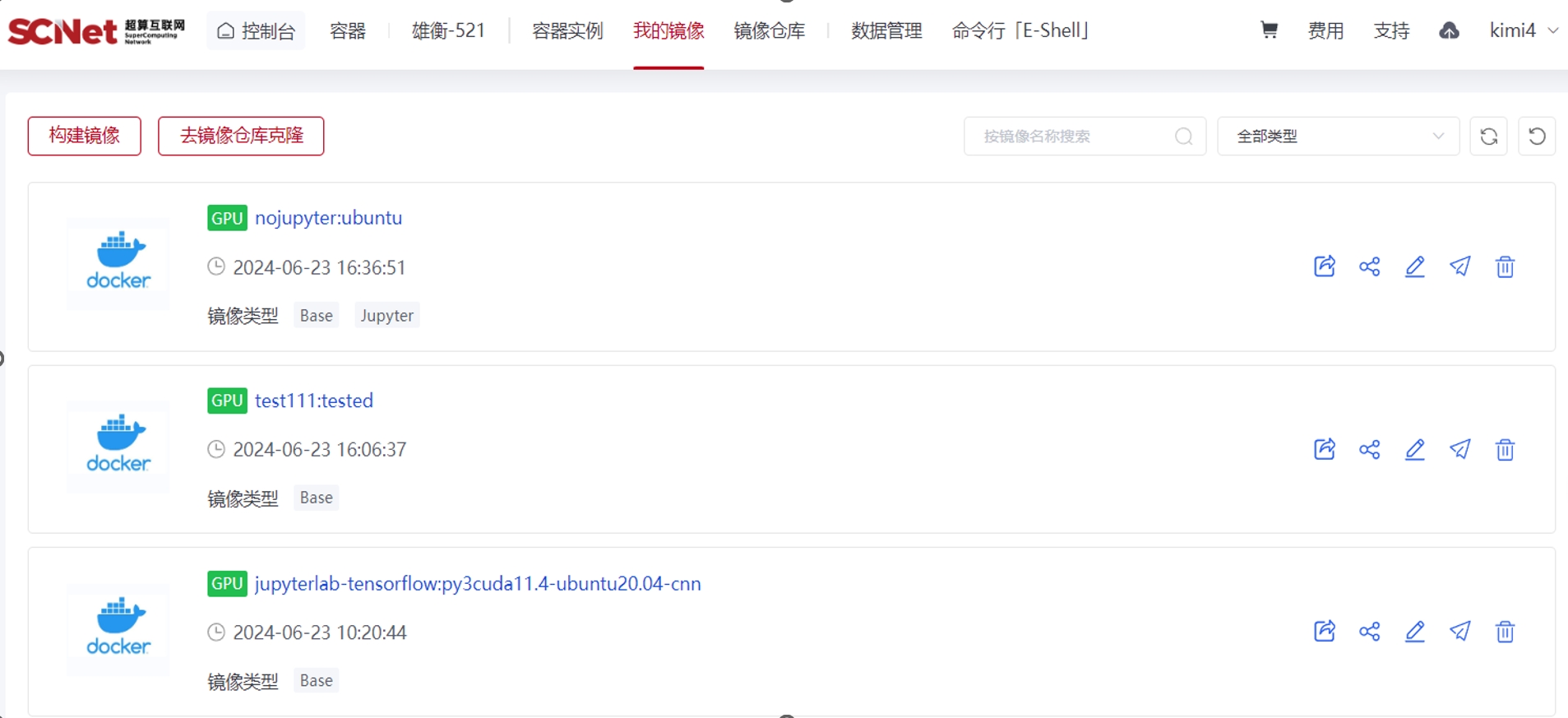
(2)查看镜像。
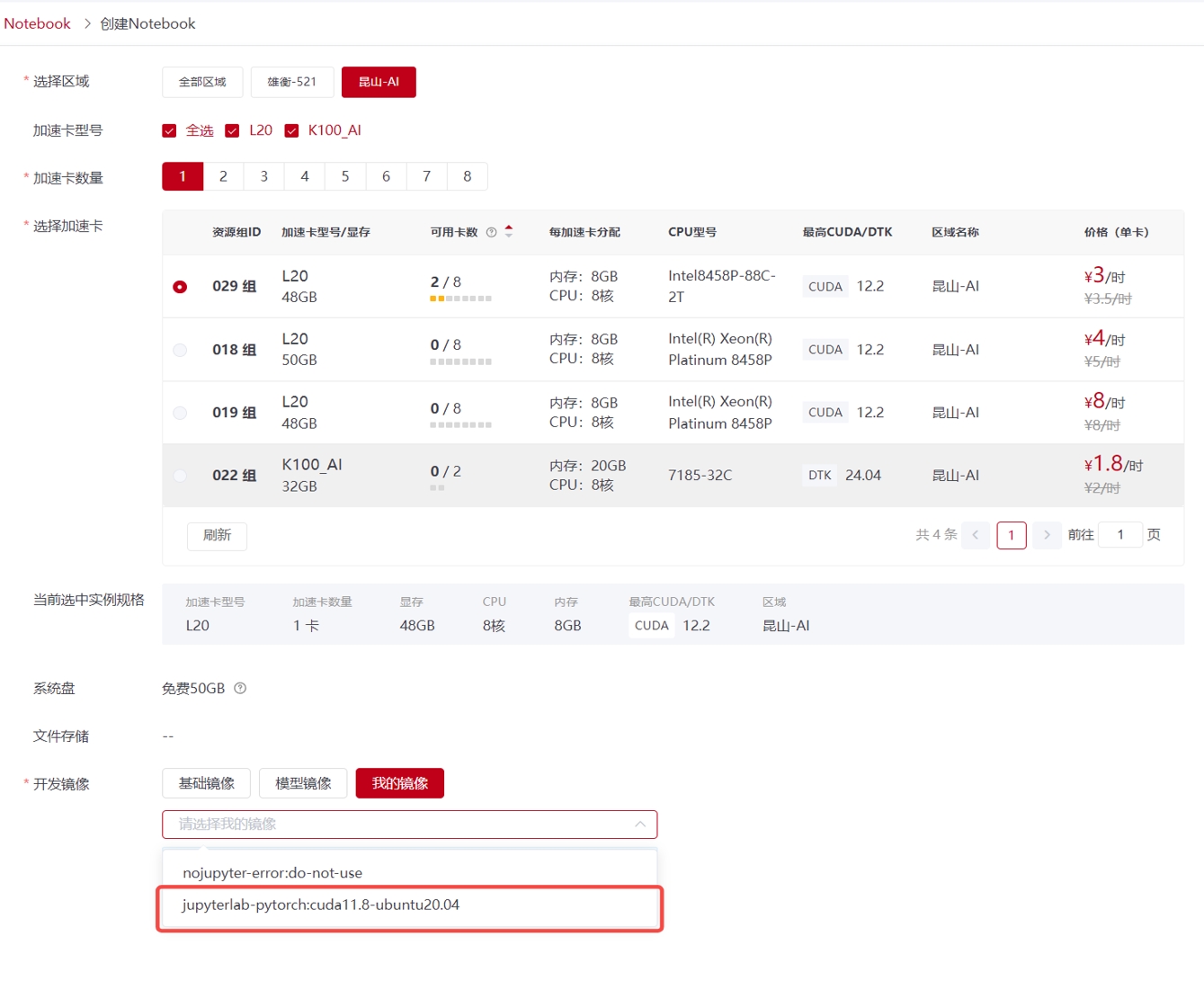
(3)加载镜像。租用新实例或者老实例选择更换镜像时,选择自己保存的镜像,这样即可恢复原来实例环境中所有内容。