人工智能服务
>
模型训练
>
最佳实践


 复制下面的代码,进行依赖安装
复制下面的代码,进行依赖安装 pip install git+https://github.com/huggingface/diffusers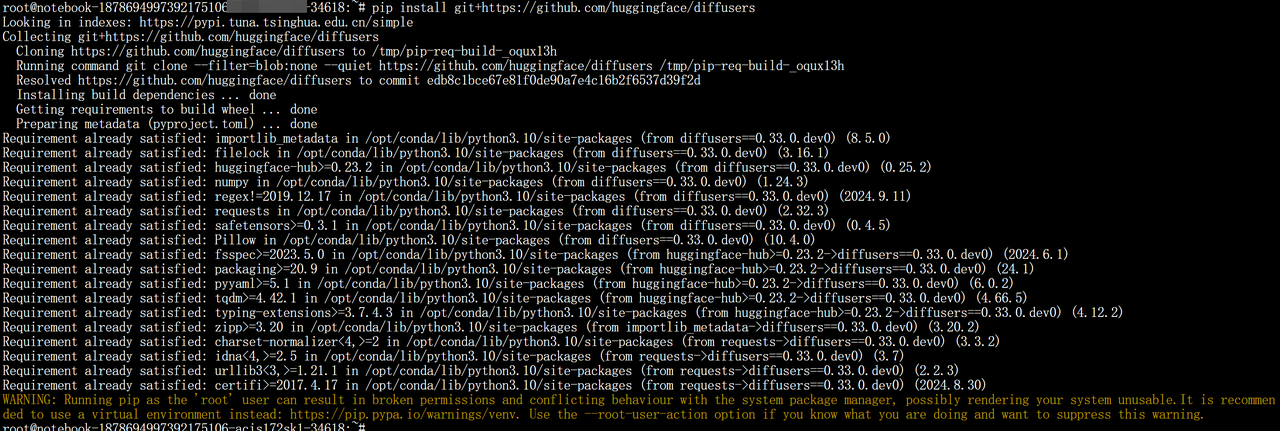
train_text_to_image_lora.py 下载
vjacc.yaml 下载
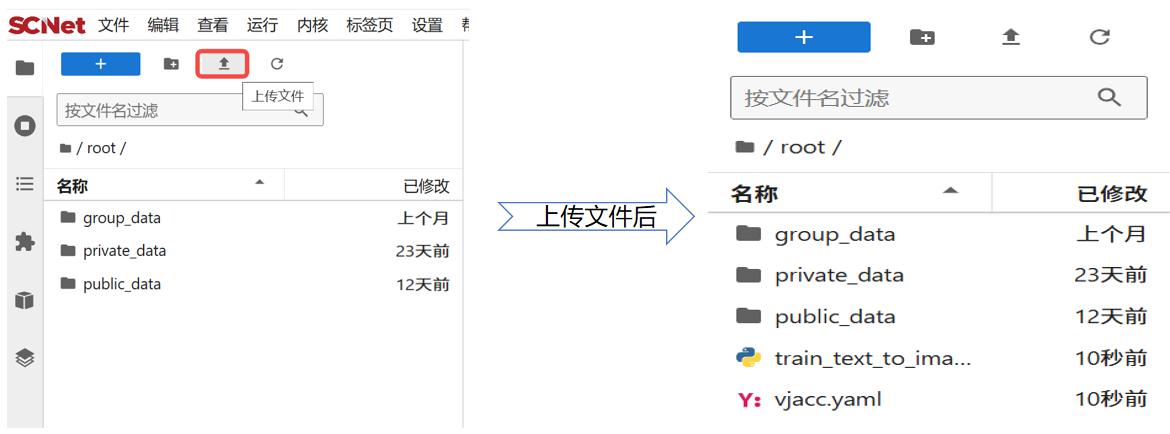
注意:保存镜像过程中,容器必须保持运行状态
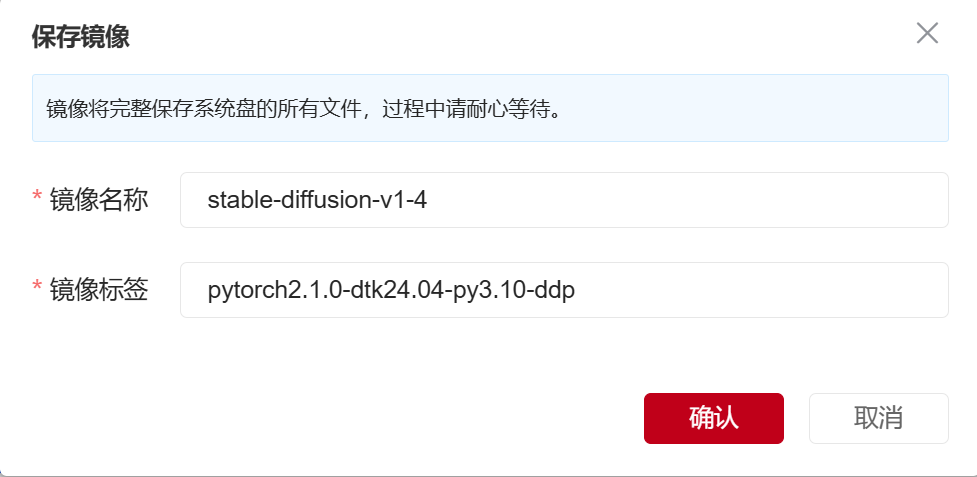
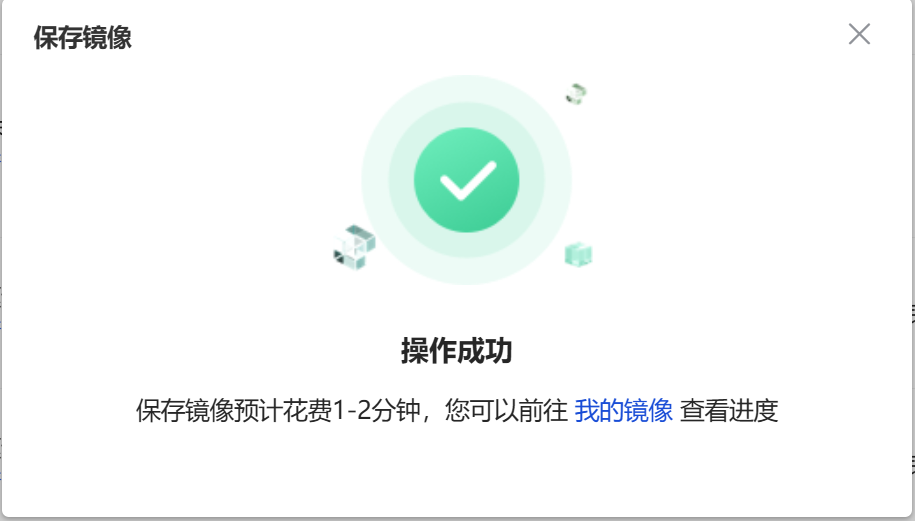 9. 可以在【我的镜像】模块,查看到已经保存好的镜像,接下来我们将使用这个保存好的镜像,创建多机多卡分布式训练任务
9. 可以在【我的镜像】模块,查看到已经保存好的镜像,接下来我们将使用这个保存好的镜像,创建多机多卡分布式训练任务 
这里使用的是stable-diffusion-v1.4模型和Tuxemon数据集,有2种获取方式( AI社区 和 应用商城),具体获取说明如下:
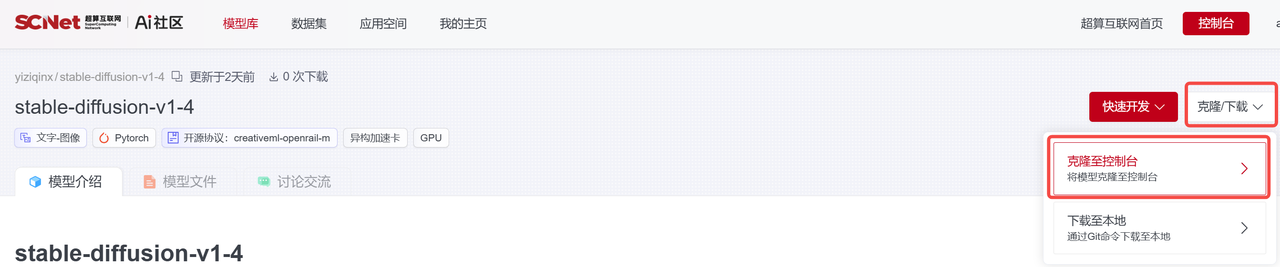

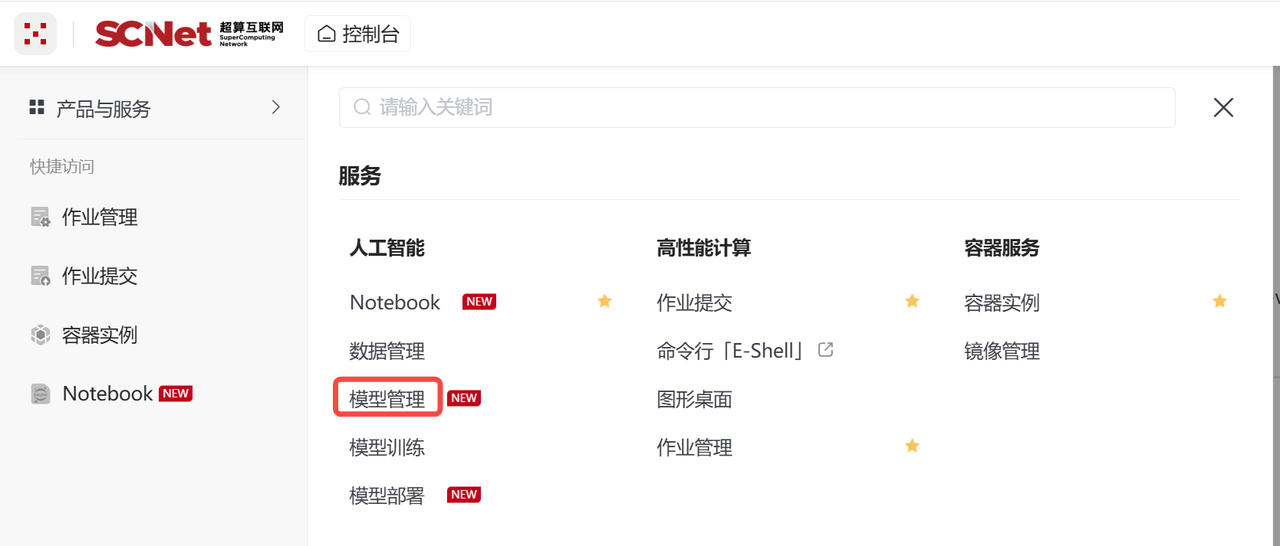
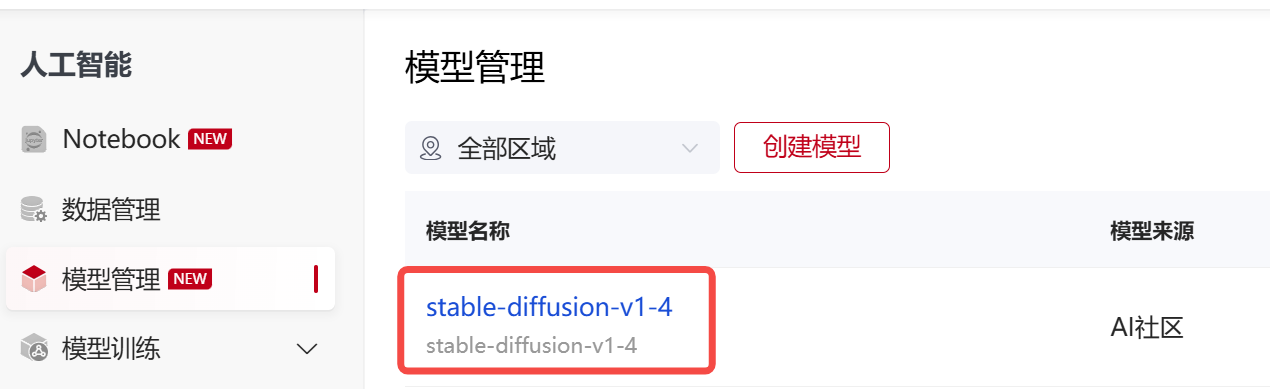
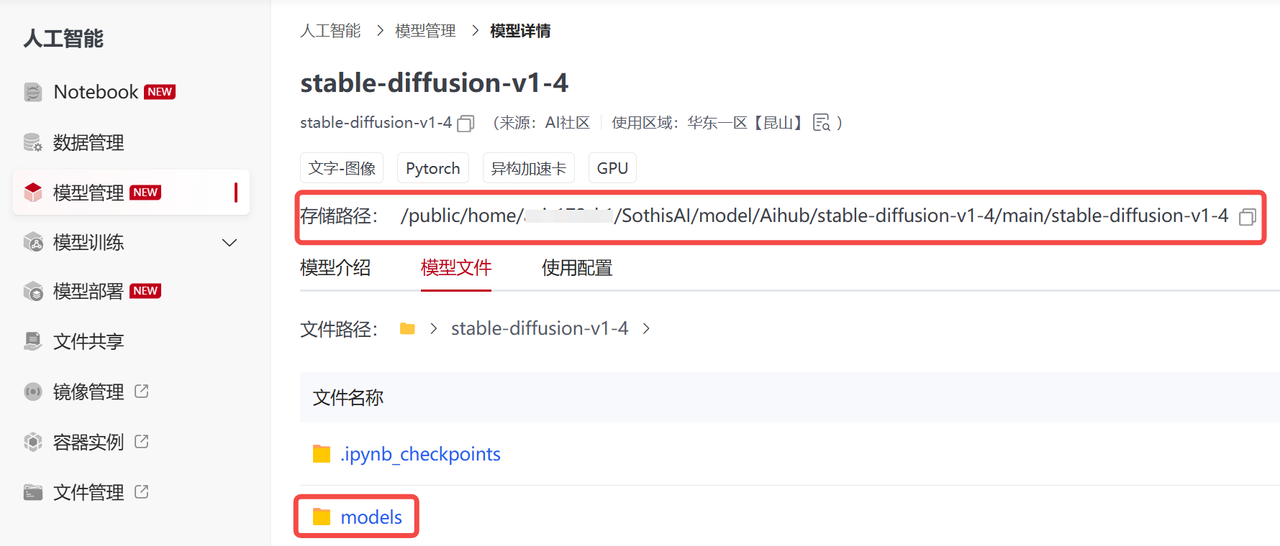 源路径:/public/home/{user_name}/SothisAI/model/Aihub/stable-diffusion-v1-4/main/stable-diffusion-v1-4/models
源路径:/public/home/{user_name}/SothisAI/model/Aihub/stable-diffusion-v1-4/main/stable-diffusion-v1-4/models
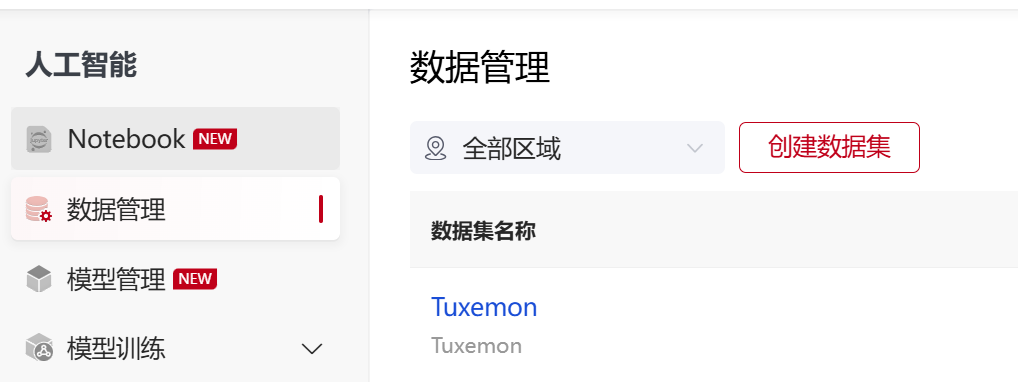
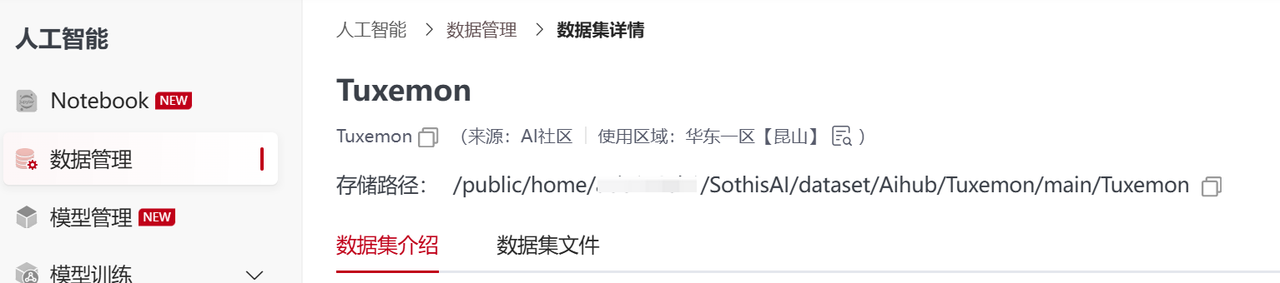 源路径:/public/home/{user_name}/SothisAI/dataset/Aihub/Tuxemon/main/Tuxemon
源路径:/public/home/{user_name}/SothisAI/dataset/Aihub/Tuxemon/main/Tuxemon 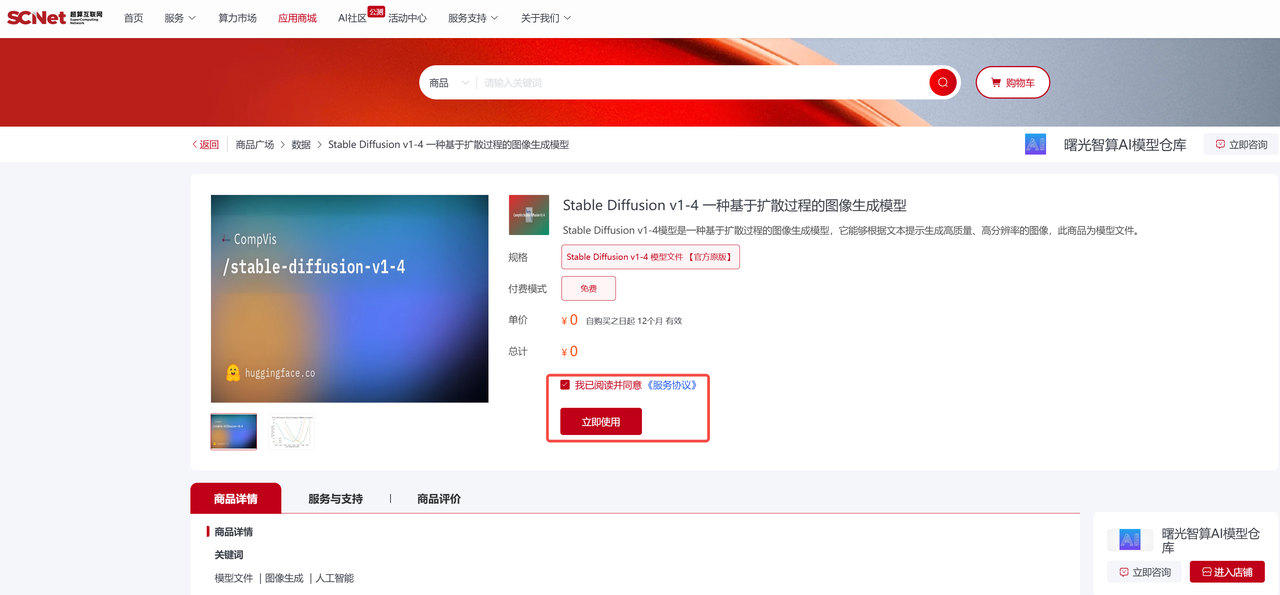
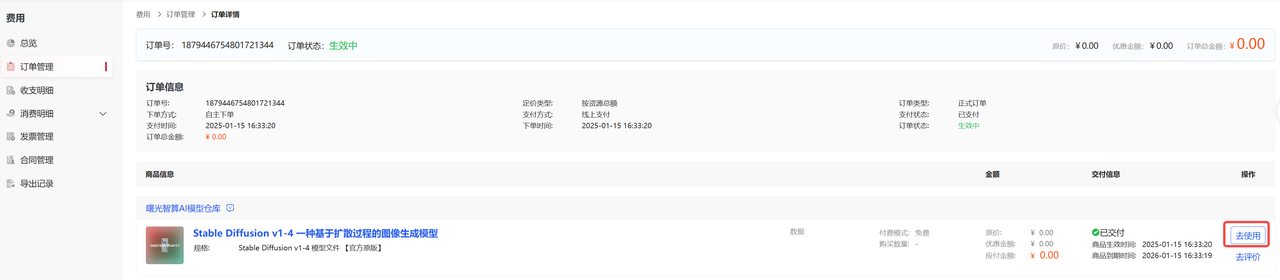

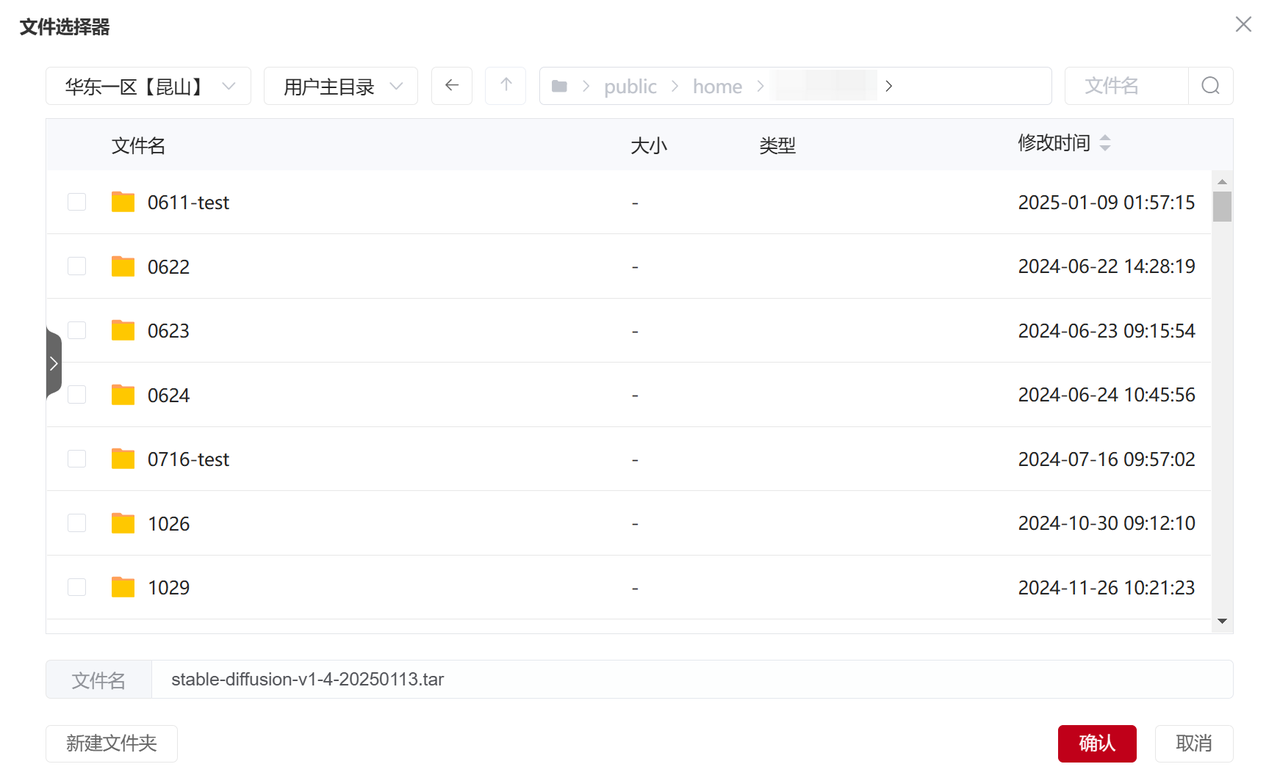

 源路径:/public/home/{user_name}/stable-diffusion-v1-4
源路径:/public/home/{user_name}/stable-diffusion-v1-4

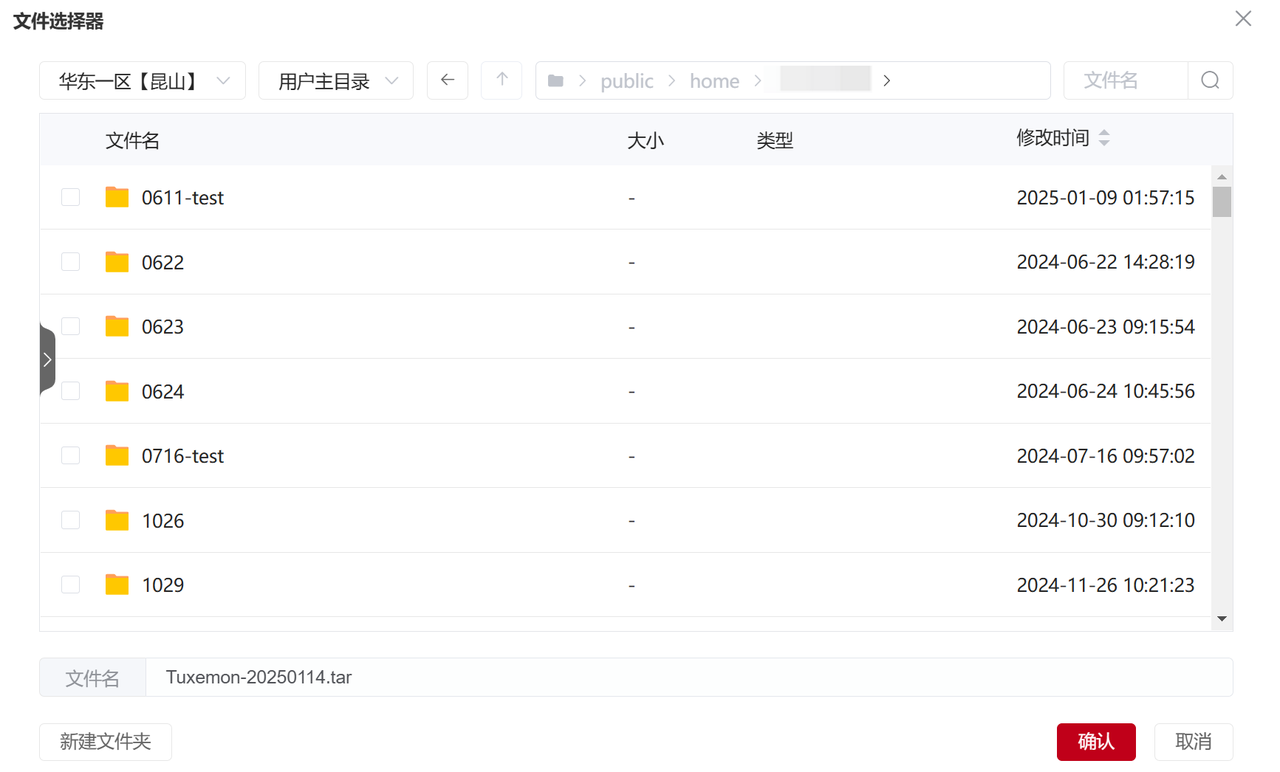

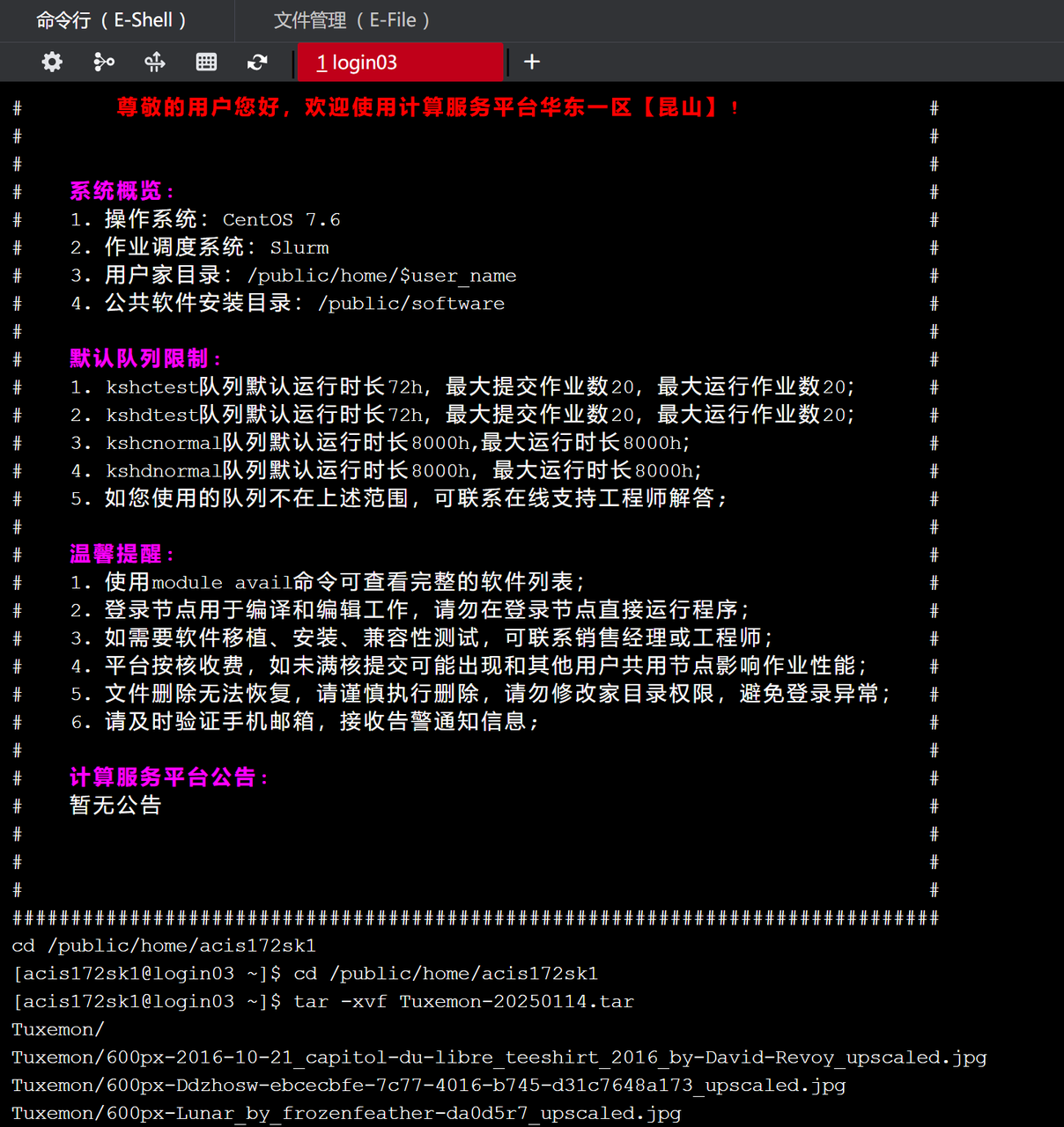 源路径:/public/home/{user_name}/Tuxemon
源路径:/public/home/{user_name}/Tuxemon
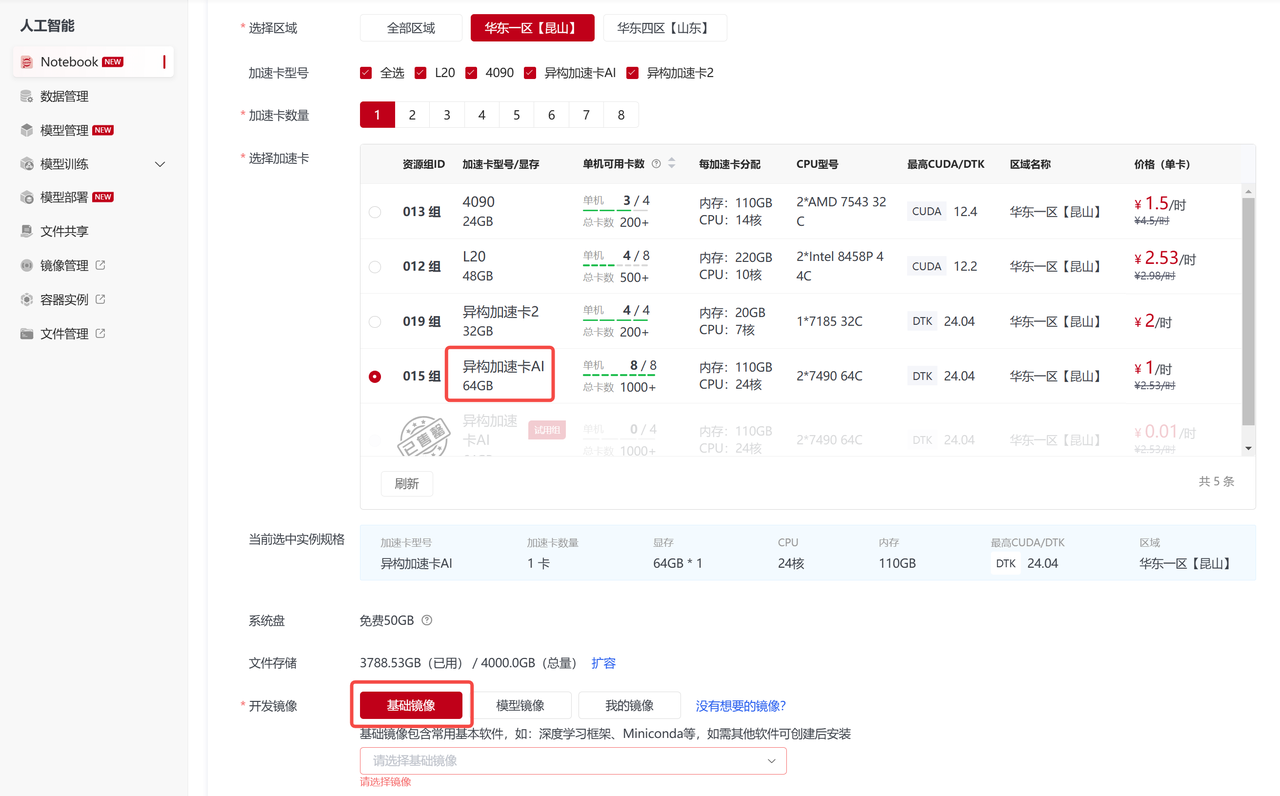
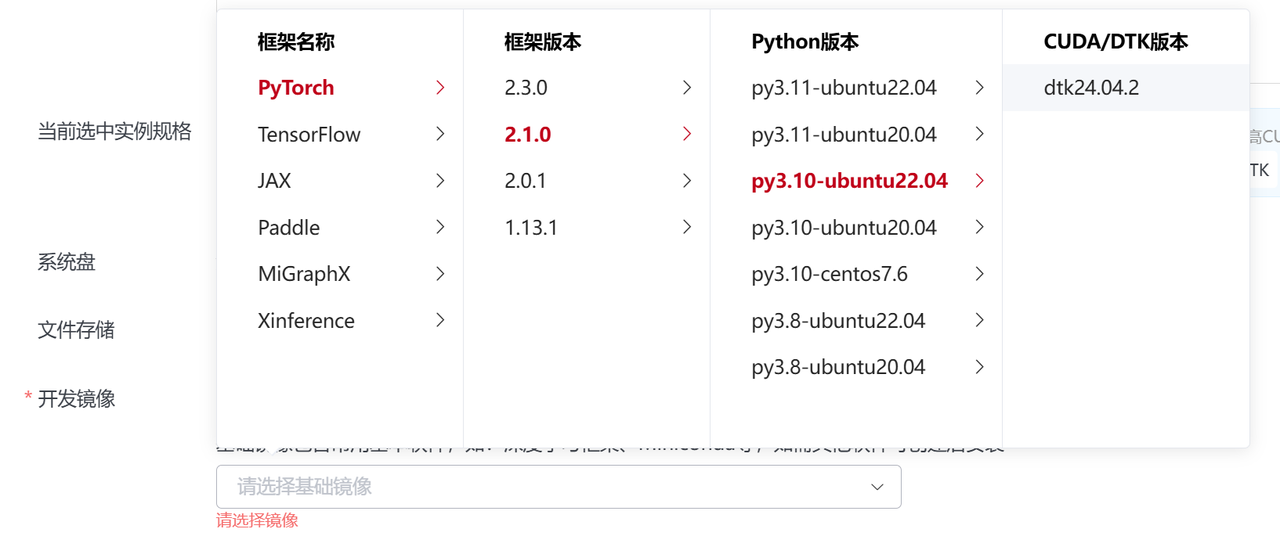
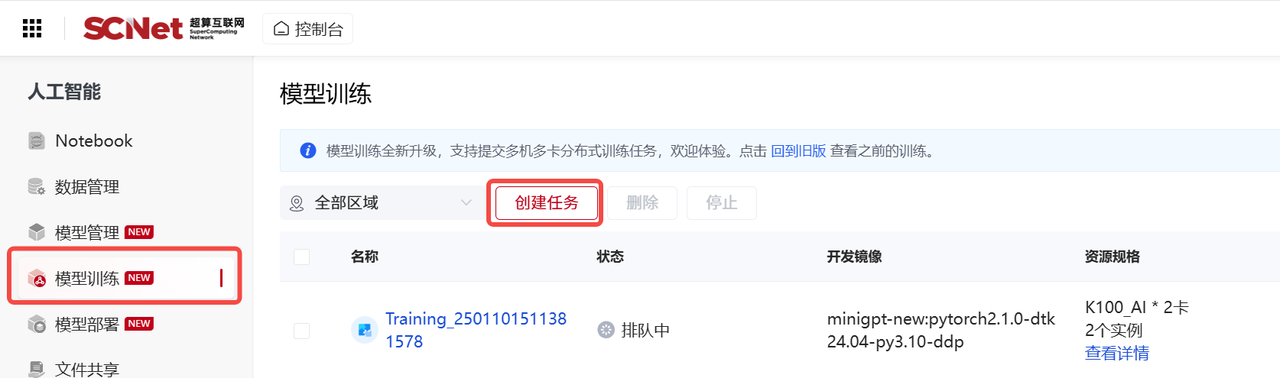 在此示例中,是选择昆山区域的【异构加速卡AI-64GB】,【每实例加速卡数量】处选择1,【实例数】选择2,代表使用两个容器,每个容器中一张加速卡,点击【我的镜像】,在列表中选择示例镜像 stable-diffusion-v1-4:pytorch2.1.0-dtk24.04-py3.10-ddp, 启动脚本为:
在此示例中,是选择昆山区域的【异构加速卡AI-64GB】,【每实例加速卡数量】处选择1,【实例数】选择2,代表使用两个容器,每个容器中一张加速卡,点击【我的镜像】,在列表中选择示例镜像 stable-diffusion-v1-4:pytorch2.1.0-dtk24.04-py3.10-ddp, 启动脚本为:accelerate launch \
--config_file /root/vjacc.yaml \
--main_process_ip $MASTER_ADDR \
--main_process_port $MASTER_PORT \
--machine_rank $RANK \
--num_processes 2 \
--num_machines 2 \
/root/train_text_to_image_lora.py \
--pretrained_model_name_or_path="/root/stable-diffusion-v1-4" \
--dataset_name="/root/Tuxemon" \
--resolution=1024 --center_crop --random_flip \
--train_batch_size=1 \
--dataloader_num_workers=8 \
--mixed_precision="fp16" \
--max_train_steps=100 \
--num_train_epochs=1 \
--learning_rate=1e-05 \
--max_grad_norm=1 \
--lr_scheduler="constant" --lr_warmup_steps=0 \
--output_dir="/root/private_data/sd-lora-model"
# 参数解释
--main_process_ip $MASTER_ADDR 分布式训练的主节点IP地址,$MASTER_ADDR 为平台自动填充,无需更改
--main_process_port $MASTER_PORT 分布式训练的主节点端口号,$MASTER_PORT 为平台自动填充,无需更改
--machine_rank $RANK 分布式训练节点的排序,$RANK 为平台自动填充,无需更改其他参数解释:
accelerate launch \
--config_file /root/vjacc.yaml \
--main_process_ip localhost \ # 多机训练时的主节点ip
--main_process_port 1234 \ # 多机训练时的主节点端口号
--machine_rank 0 \ # 当前主机的序号
--num_processes 1 \ # 训练机器数 * 每个机器上的加速卡数
--num_machines 1 \ # 训练机器数
/root/train_text_to_image_lora.py \ # 脚本文件
--pretrained_model_name_or_path="your_pretrained_model_path" \ # 预训练模型权重文件的存放位置
--dataset_name="your_dataset_path" \ # 数据集位置,可以参考给出的示例数据集准备您自己的数据集
--resolution=1024 --center_crop --random_flip \
--train_batch_size=1 \
--dataloader_num_workers=8 \
--mixed_precision="fp16" \
--max_train_steps=100 \
--num_train_epochs=1 \
--learning_rate=1e-05 \
--max_grad_norm=1 \
--lr_scheduler="constant" --lr_warmup_steps=0 \
--output_dir="your_lora_model_path" # lora 微调后模型权重存放位置其中,
--pretrained_model_name_or_path #填写模型的路径;
--dataset_name #填写数据集的路径;
--output_dir #填写训练完成后模型存储的位置,您可以将微调后模型权重存放在预训练模型stable-diffusion-v1-4的同级文件夹内,例如:
AI社区下载的预训练权重路径:/public/home/{user_name}/SothisAI/model/Aihub/stable-diffusion-v1-4/main/stable-diffusion-v1-4/models
应用商城下载的预训练权重路径:/public/home/{user_name}/stable-diffusion-v1-4
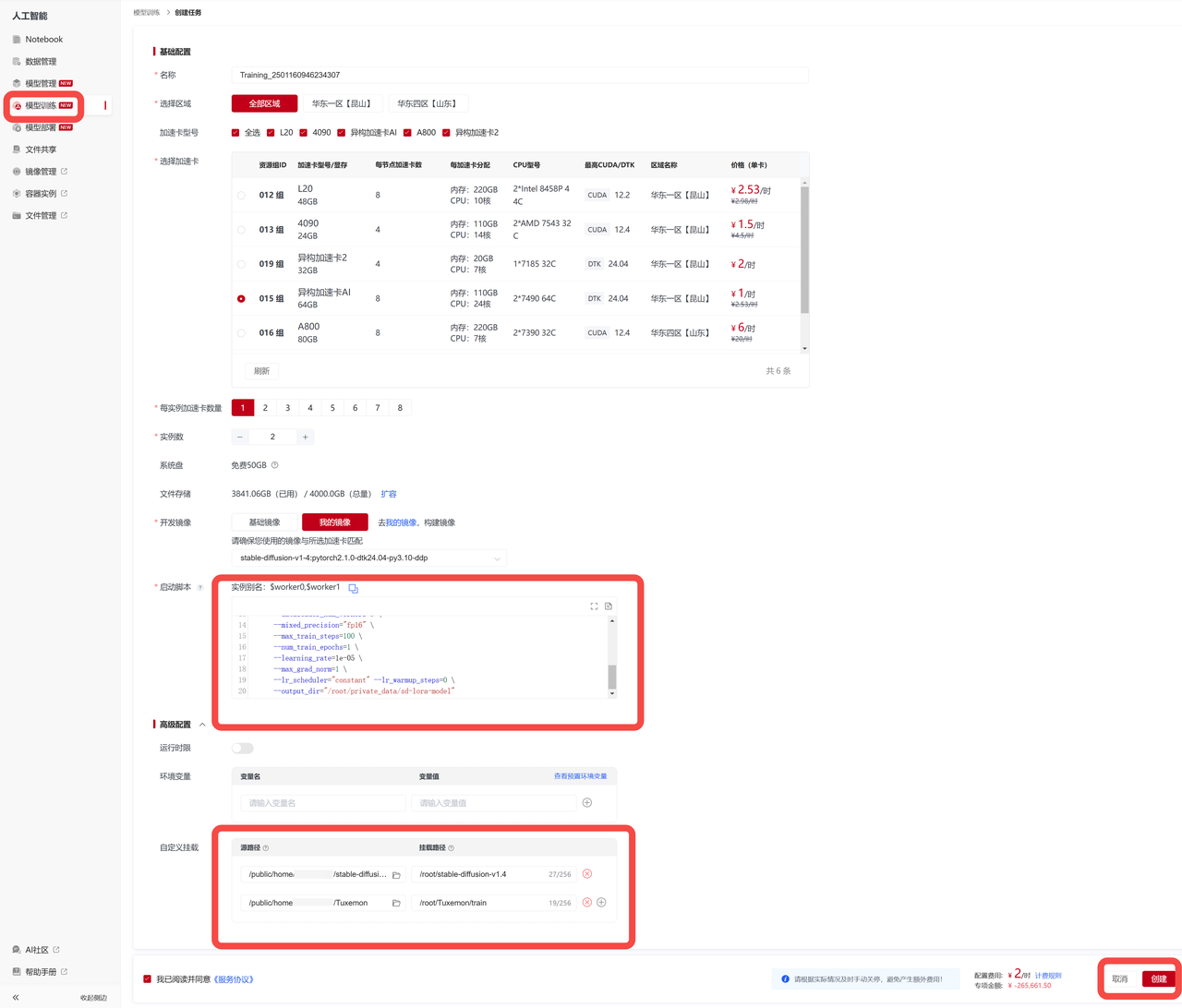 至此,多机多卡分布式训练任务创建完毕,接下来就可以运行此任务了。
至此,多机多卡分布式训练任务创建完毕,接下来就可以运行此任务了。
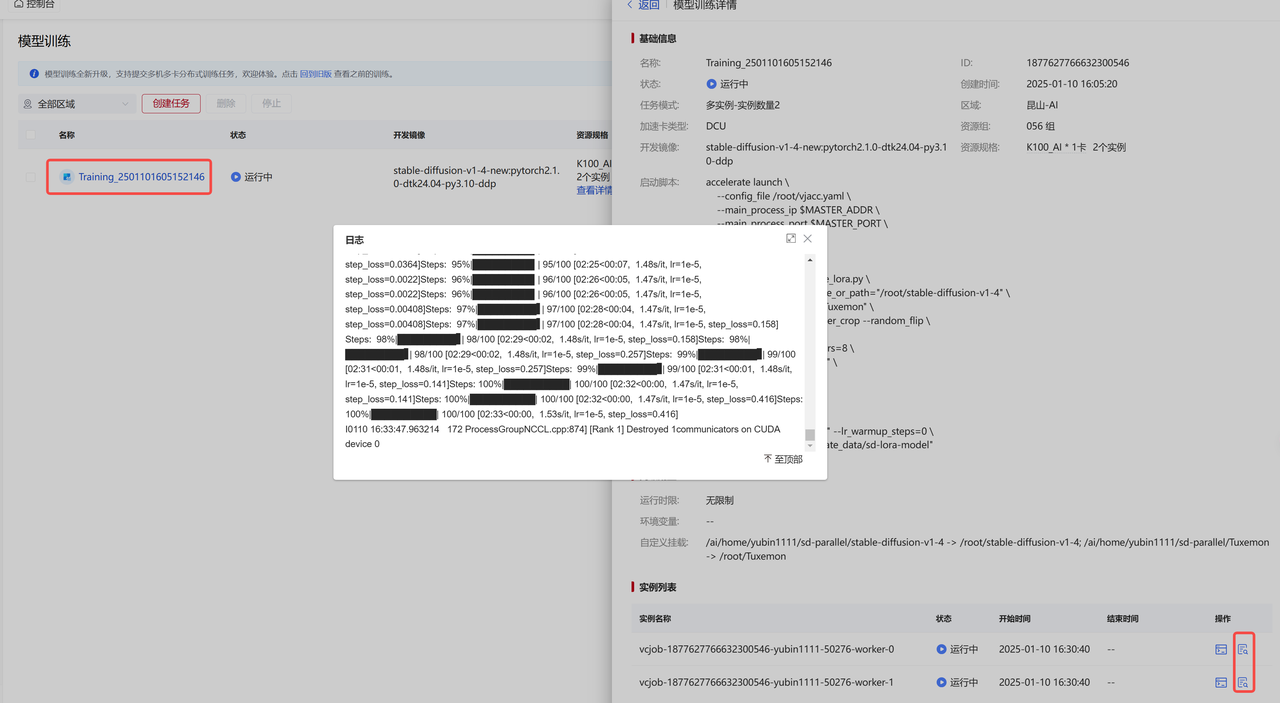 由上图可知,此训练示例有2个实例,分别为 'worker0' 和 'worker1',具体运行情况如下:
由上图可知,此训练示例有2个实例,分别为 'worker0' 和 'worker1',具体运行情况如下: 这是 'worker1' 实例运行详情截图(说明'worker1'在正常运行):
这是 'worker1' 实例运行详情截图(说明'worker1'在正常运行): 
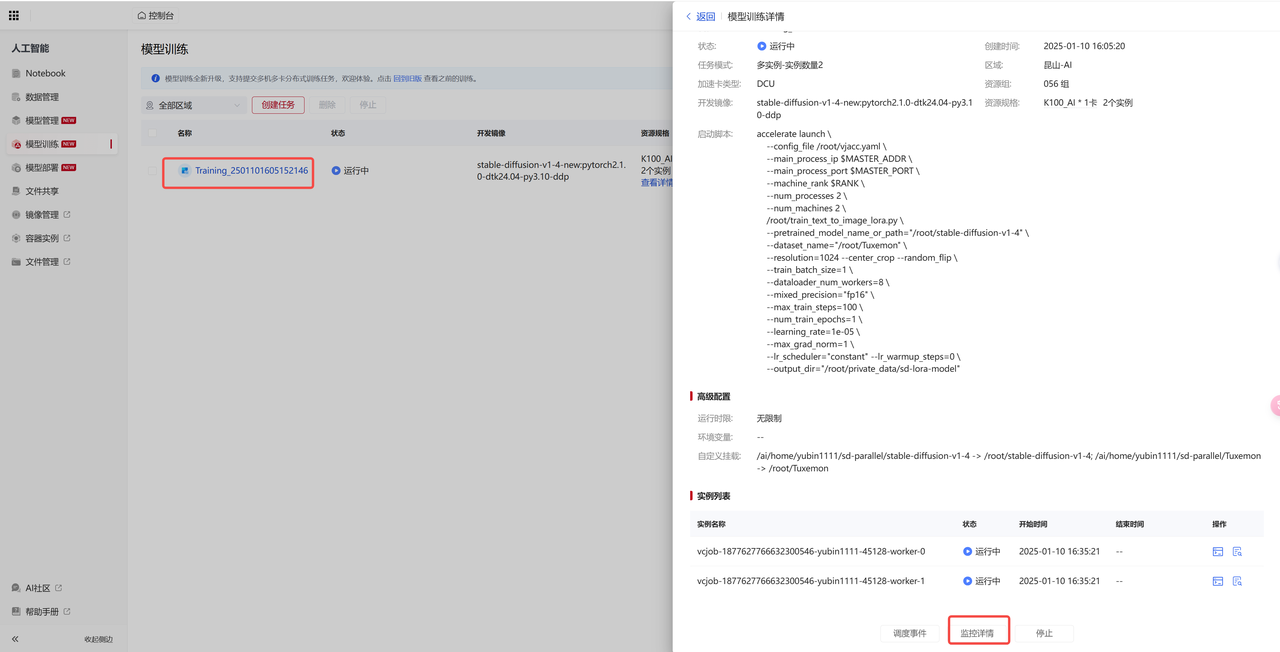
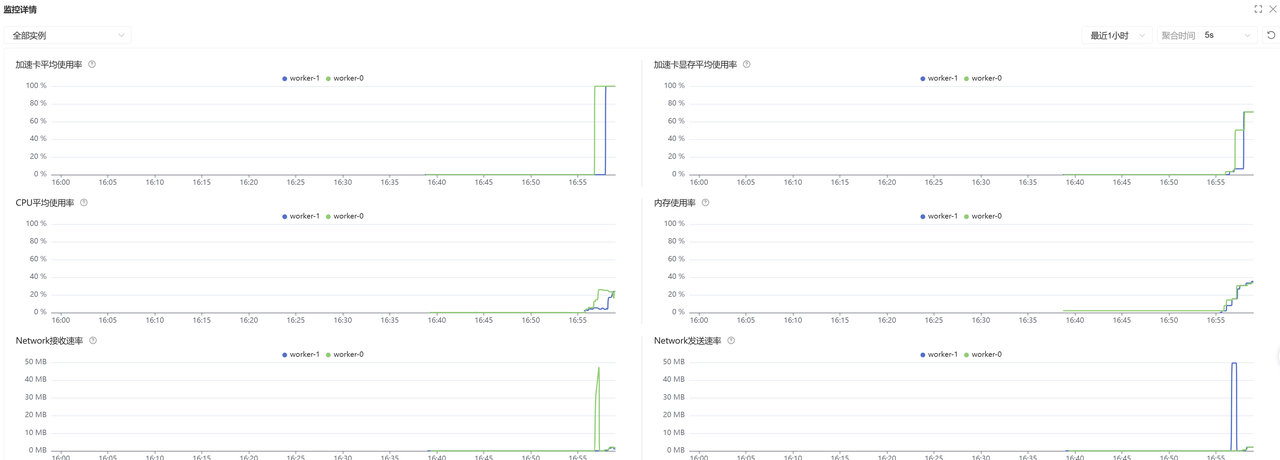

 以上,我们就完成了在 超算平台-模型训练模块 提交多机多卡训练任务的完整流程。
以上,我们就完成了在 超算平台-模型训练模块 提交多机多卡训练任务的完整流程。注:本篇实践是以stable-diffusion-v1.4模型为例,使用超算平台-模型训练模块相关功能进行分布式模型训练任务,旨在描述平台模型训练模块的功能使用情况,若扩展至其他模型或场景,可根据需要调整相应镜像、模型、数据集及运行脚本即可。希望本篇实践案例内容能为您提供一些指导和建议。