高性能计算服务
>
常见问题
答:由于集群采用共享存储,文件一旦删除无法找回,请谨慎执行rm命令。
答:如果是脚本提交,提交作业时可以使用SBATCH -x 节点名 脚本名排除异常节点再重新提交,如果是其他方式提交,您可以直接重新提交。 温馨提示:节点异常的情况后台会进行统一赔付。
答:重置/修改密码请参考 个人中心->安全设置。
答:如果是使用网页进行下载,请换成快传客户端进行上传下载。
答:方法一:在弹出的“已拦截弹出式窗口:”选中“始终允许https://www.scnet.cn显示弹出式窗口和进行重定向”;
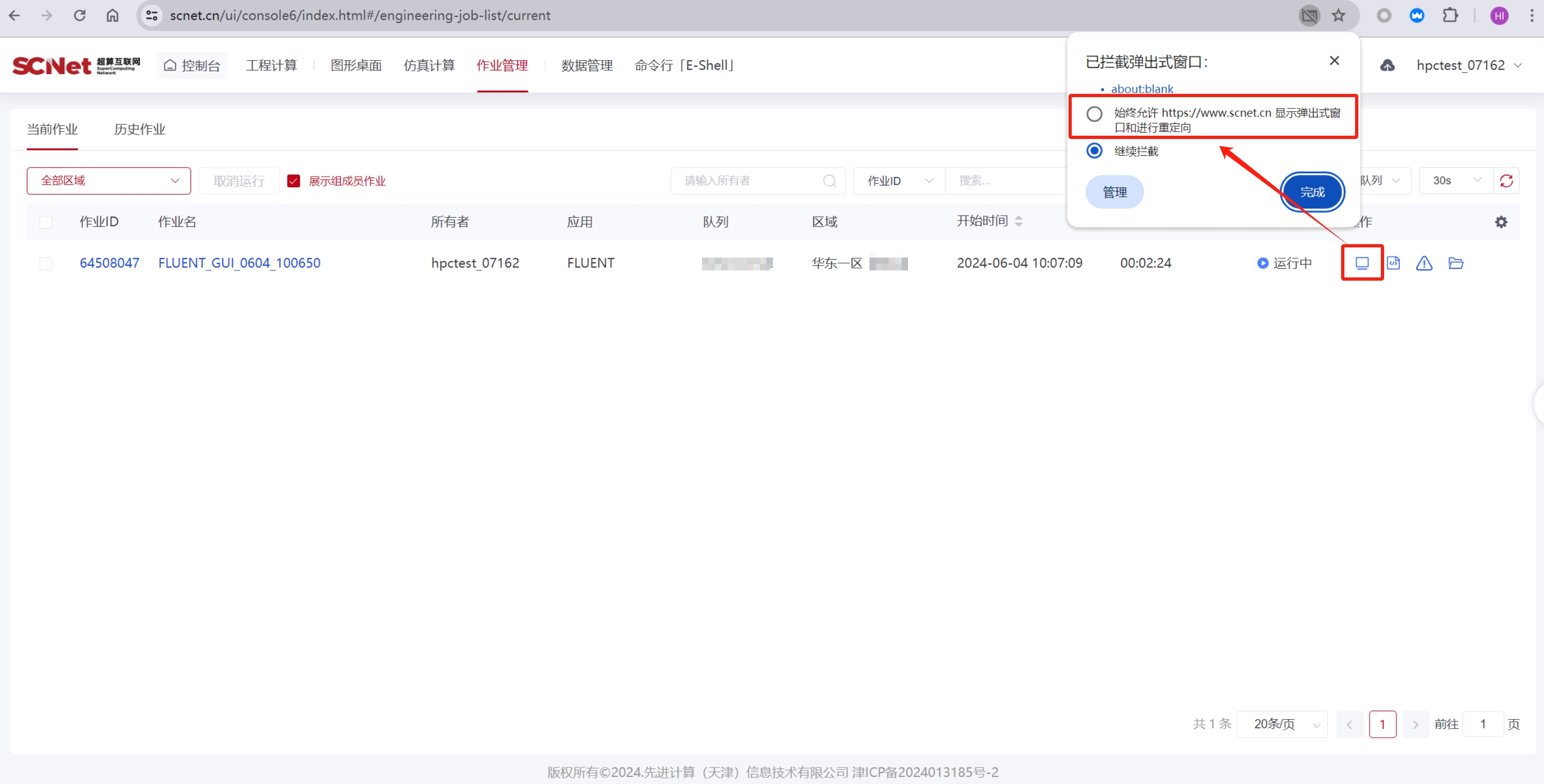
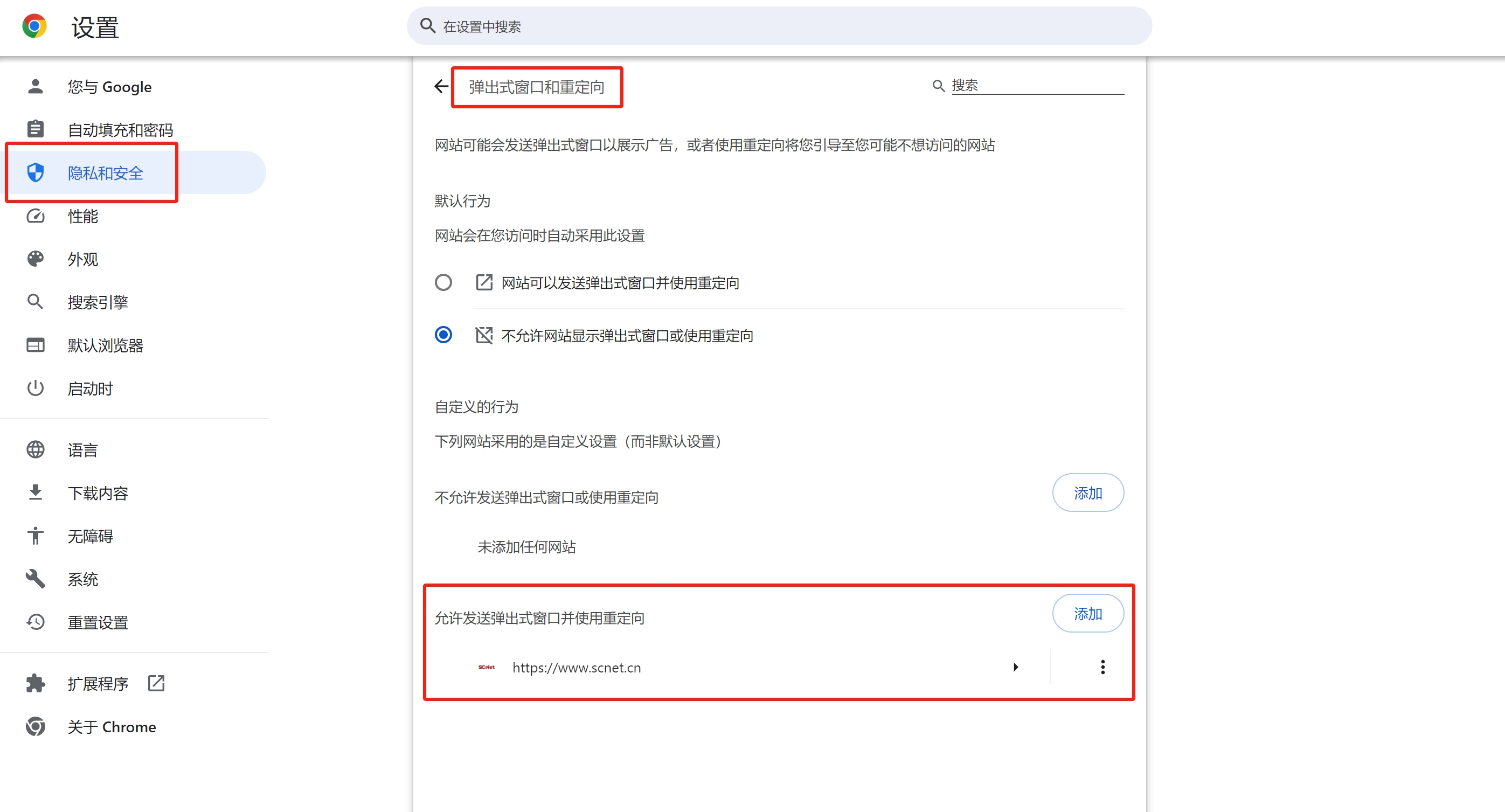
方法二:手动设置,以谷歌浏览器为例,在“浏览器的设置”>“隐私和安全”>“网站设置”>“弹出式窗口和重定向”,在下面的“允许发送弹出式窗口并使用重定向”添加网站https://www.scnet.cn。
答:目前计算节点是不支持上网功能的,可以告知值班工程师具体需求,工程师评估后会帮忙申请开通代理,配置后进行上网。
答:方法一:登录https://www.ip138.com/,将返回的ip地址告诉值班工程师,并请求加入超算白名单。
方法二:已添加白名单的ip仍无法登录的话,尝试本地网络,如手机热点。
答:添加加速代理服务。如https://mirror.ghproxy.com/或https://hub.nuaa.cf/均有不错的加速效果。使用如下:
git clone https://github.com/lammps/lammps.git
修改为
git clone https://mirror.ghproxy.com/https://github.com/lammps/lammps.git