人工智能服务
>
最佳实践
>
异构加速卡基础镜像部署Qwen-VL-Chat
在AI领域,多模态交互正成为推动人工智能发展的重要技术方向之一。多模态交互意味着AI能够同时处理和理解来自不同模态的信息,如文本、图像、音频等。想象一下,当艺术家让AI描述一张摄影作品,以寻找创作灵感;当游客在一个陌生的城市中游览时,可以通过手机拍摄景点的照片,并询问AI有关该地点的历史背景或实用信息,如开放时间、票价等。这种能力在日常生活、教育等多个领域都有着广泛的应用前景。
在SCNet最佳实践系列第12期,我们介绍了如何在超算互联网使用官方GPU基础镜像部署仅支持文本输入的语言模型 Llama3,为了满足用户不同场景下的模型开发需求,超算互联网提供38个基于官方GPU、异构加速卡的基础镜像,开发者可从超算互联网下载多模态模型,平台提供包括模型训练、推理、部署、微调等在内的全方位服务。
您可以参照下表了解官方异构加速卡基础镜像的基本信息:
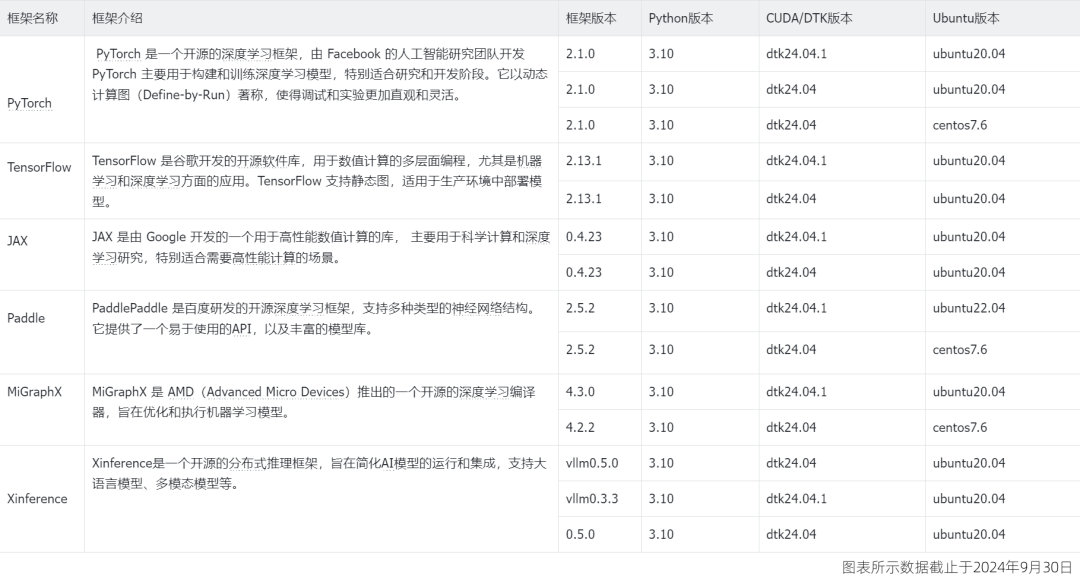
本次实操,我们手把手演示如何在超算互联网使用官方的异构加速卡基础镜像部署多模态模型Qwen-VL-Chat,一键创建容器实例,快速部署 AI 大模型推理服务。
第一步:创建Notebook在线启动异构加速卡基础镜像
登录超算互联网https://www.scnet.cn个人账号,点击右上角“控制台”;
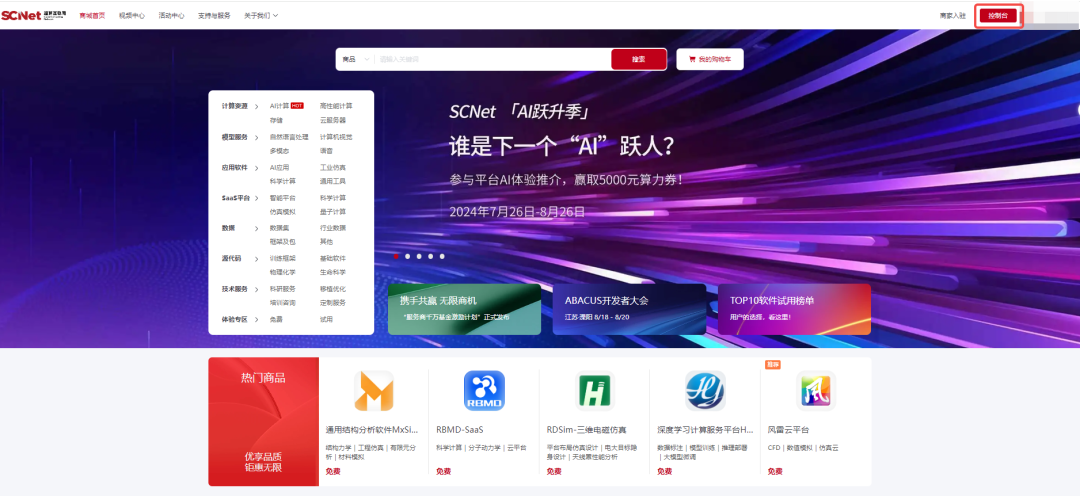
点击快捷入口中的“Notebook”,进入创建Notebook页面;
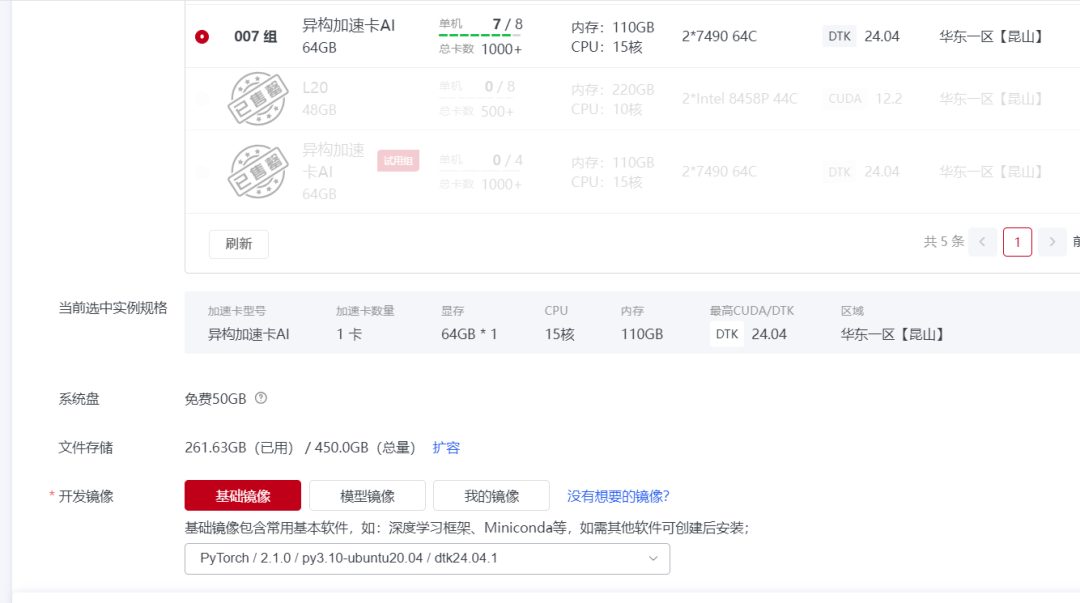
选择区域、选择异构加速卡,点击“基础镜像”,在列表中选择想要配置的镜像,这里我们选择PyTorch / 2.1.0 / py3.10-ubuntu20.04 / dtk-24.04.1,点击创建;
创建成功后,点击“JupyterLab”进入Notebook页面;

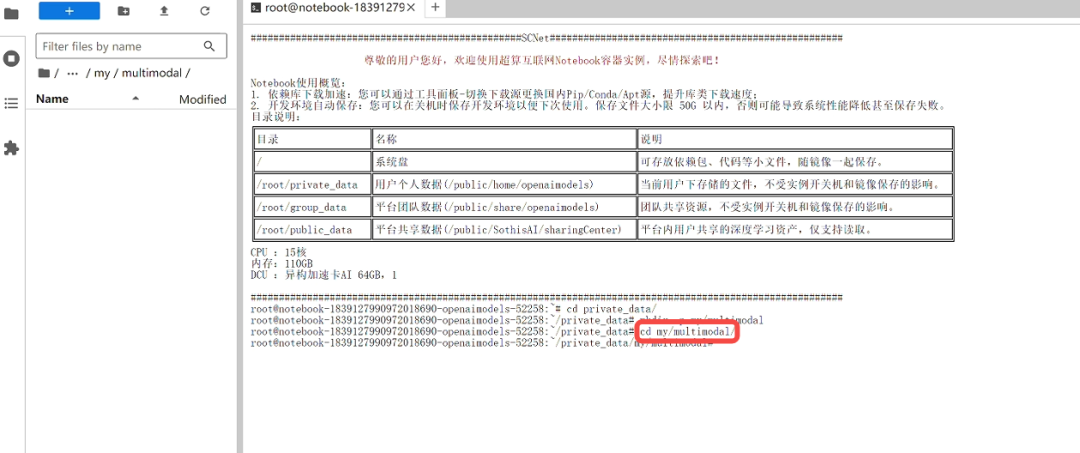
在Notebook中打开“终端”页面,使用命令进入private_data文件夹,创建个人空间和项目文件夹;
cd private_data
mkdir -p my/multimodal随后进入项目文件夹cd my/multimodal,此时的notebook处在一个完全干净的运行环境与项目空间。
第一步:导入模型文件
导入模型文件有多种方法,我们推荐从超算互联网获取Qwen-VL-Chat模型文件,登录超算互联网搜索并选择“Qwen-VL-Chat”模型商品,勾选服务协议后,点击“立即使用”,等待商品交付完成,点击“查看”;如果之前购买过商品,点击“去使用”,即可进入已购商品详情页面。
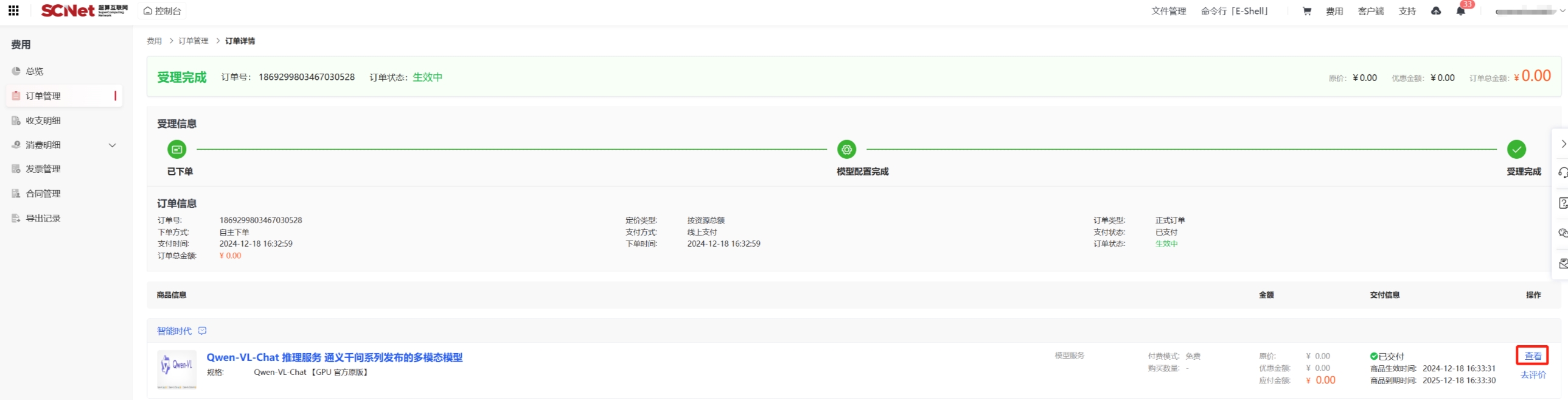
点击“文件管理”。

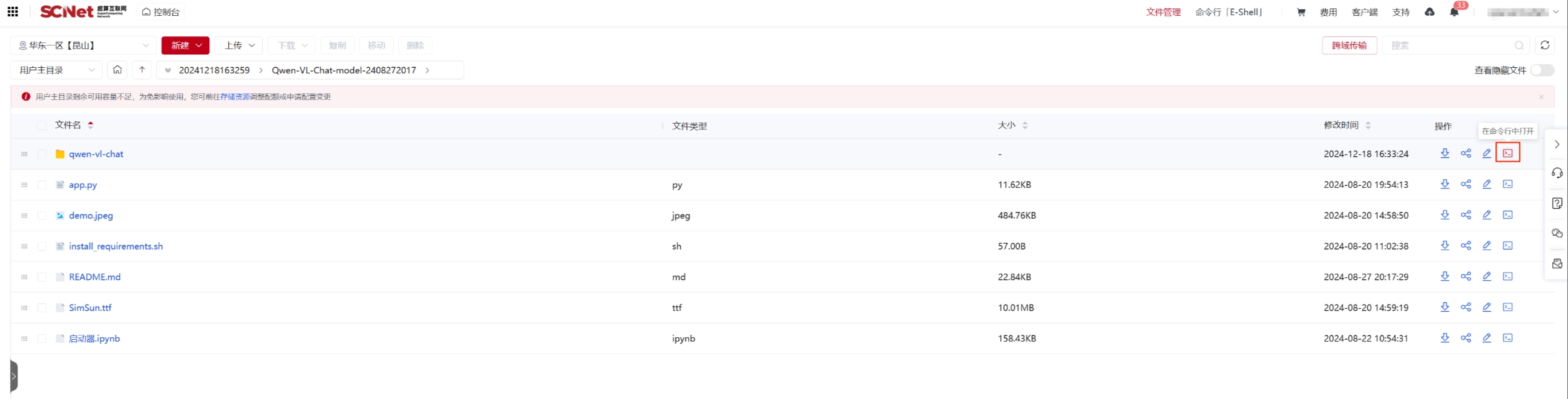
找到模型文件对应的文件夹(购买的模型在apprepo/model/购买日期/模型名 文件夹下),点击“在命令行中打开"按钮。
使用pwd查看模型文件路径,并复制路径
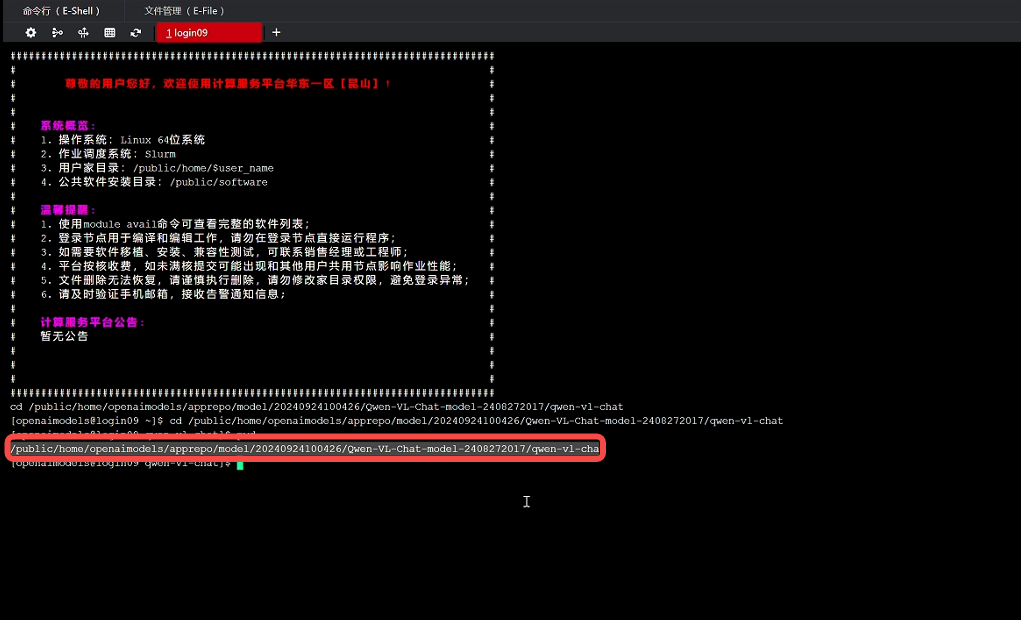
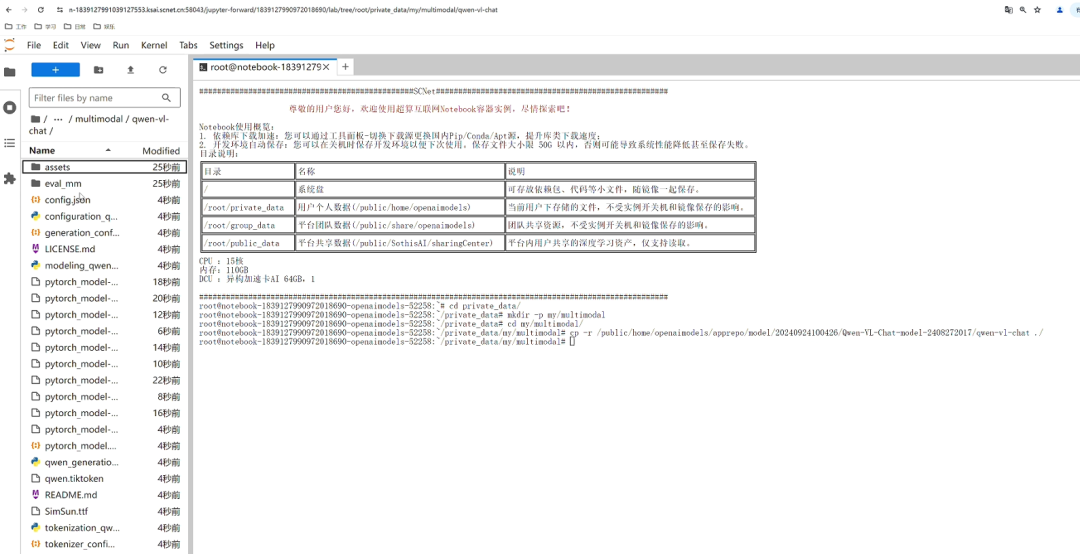
再回到之前创建的项目文件夹终端页面,使用命令cp -r 路径 ./ 复制模型文件,等待模型文件复制完成后,即可看到Qwen-VL-Chat模型文件:
第二步:安装模型运行的依赖包
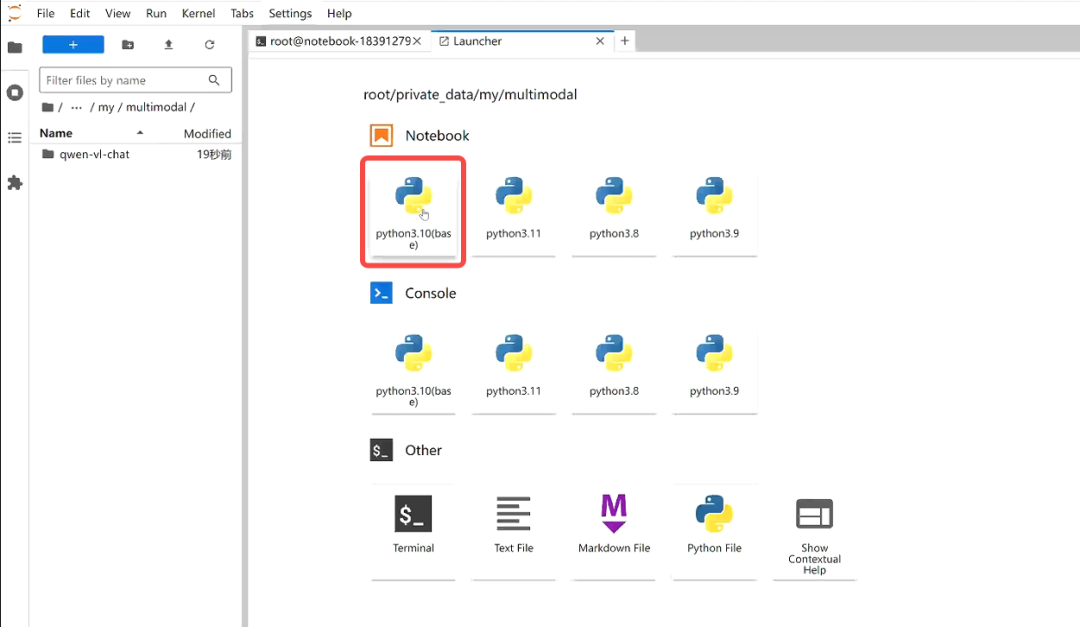
pip install tiktoken einops transformers_stream_generator第三步:新建笔记本,重命名为inference,用于编写代码运行模型
第四步:编写代码,先导入相关模块,然后以此运行代码
#导入相关模块
import os
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from IPython.display import display, Image
from transformers.generation import GenerationConfig#设置tokenizers 是否使用并行处理
os.environ["TOKENIZERS_PARALLELISM"] = "false"#检查是否有可用的加速卡
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")#设置模型路径
model_id = "./qwen-vl-chat"#加载模型之前释放显存
torch.cuda.empty_cache(#加载模型
print(f"开始加载 qwen-vl-chat 模型...")
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_id, device_map=device, trust_remote_code=True).eval()等待模型加载完成,由于Qwen-VL-Chat模型支持图片和文本输入,需要上传图片,点击上传本地图片,图片上传完成后,设置输入为图片名称和prompt。
#设置输入
image_url = "demo.jpeg"
prompt = '这是什么?'最后进行模型推理:
#模型推理
query = tokenizer.from_list_format([
{'image': image_url}, # Either a local path or an url
{'text': prompt},
])
response, history = model.chat(tokenizer, query=query, history=None)#显示输入的图片,并打印输出
display(Image(image_url))
print(response)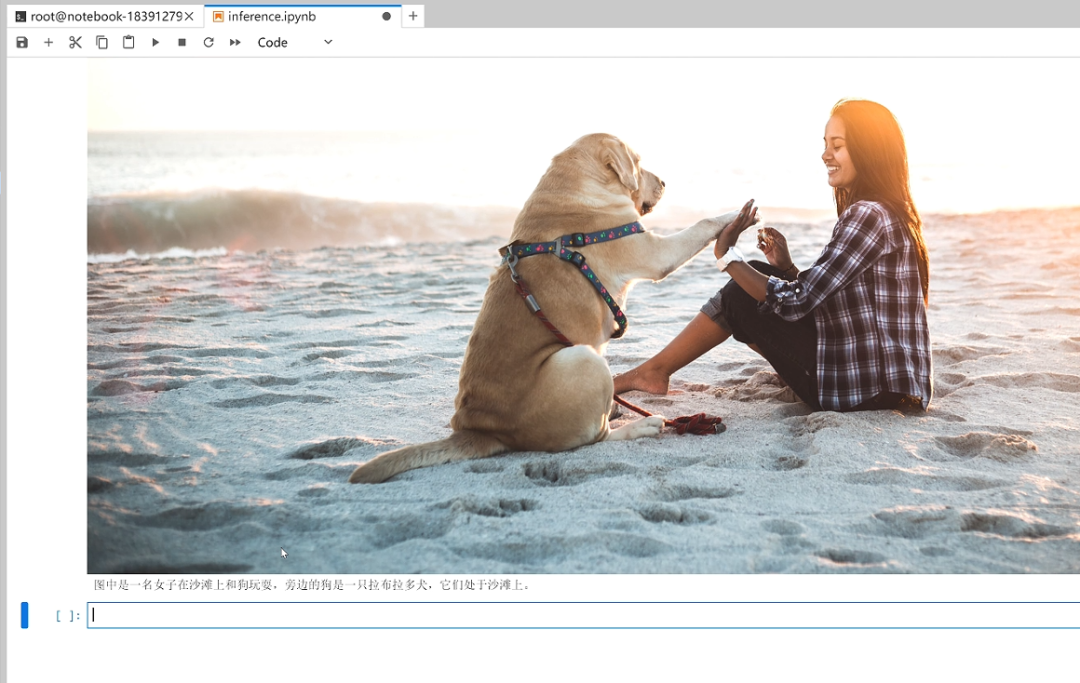
在单元格下方即可看到Qwen-VL-chat模型针对输入的图片和问题所生成的答案。如果想更换图片进行提问,您可以继续点击上传本地图片,修改图片名称和prompt,运行单元格代码查看答案,也可以根据自己的喜好设置相关参数和最终表现形式。
以上就是本次实操教程的全部内容了,大家可参照此步骤,在超算互联网使用异构加速卡基础镜像部署想要的大模型服务。