人工智能服务
>
最佳实践
>
GPU基础镜像部署Llama3
无需管理底层基础设施,无需繁琐配置流程,现在,超算互联网提供33个基于AI开发所需的常用基础镜像,可实现零门槛快速部署 AI 推理应用。开发者可直接使用相应镜像创建训练任务或容器实例,包括 PyTorch、TensorFlow、TensorRT等多种依赖。
您可以参照下表了解官方GPU基础镜像的基本信息:
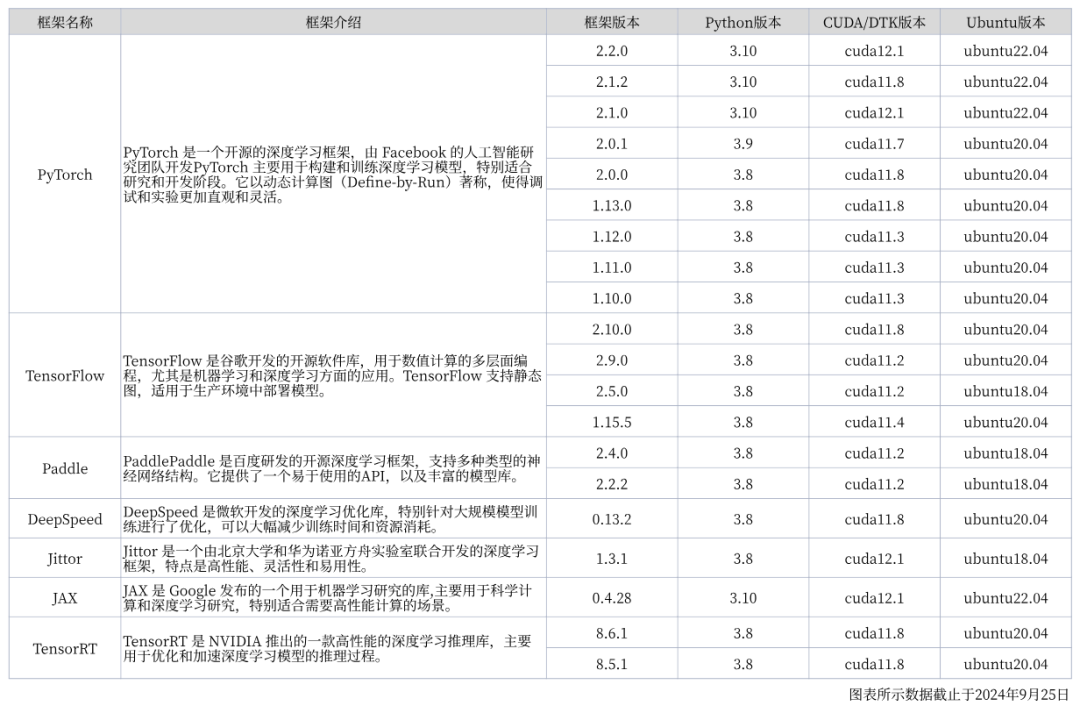
本次实操,我们手把手演示如何在超算互联网使用官方GPU基础镜像部署 Llama3 ,一键创建容器实例,快速部署 AI 大模型推理服务。
第一步:创建Notebook在线启动GPU基础镜像
登录超算互联网https://www.scnet.cn个人账号,点击右上角“控制台”;
点击快捷入口中的“Notebook”,进入创建Notebook页面;
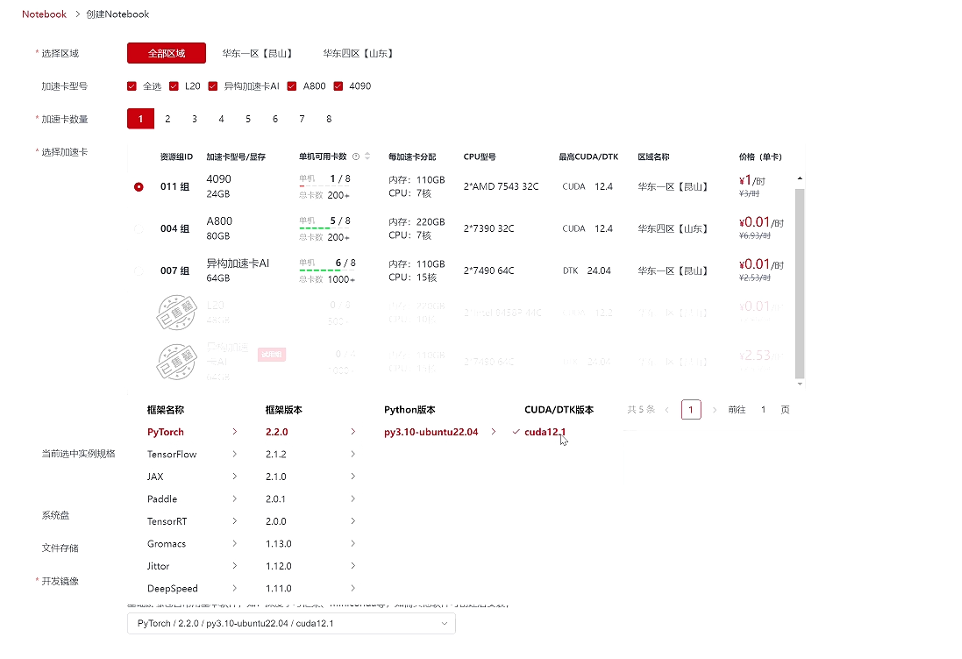
选择区域、选择4090加速卡,点击“基础镜像”,在列表中选择想要配置的镜像,这里我们选择PyTorch / 2.2.0 / py3.10-ubuntu22.04 / cuda12.1,点击创建;
创建成功后,点击“jupyterLab”进入Notebook页面;

在Notebook中打开“终端”页面,使用命令进入private_data文件夹,创建个人空间和项目文件夹;
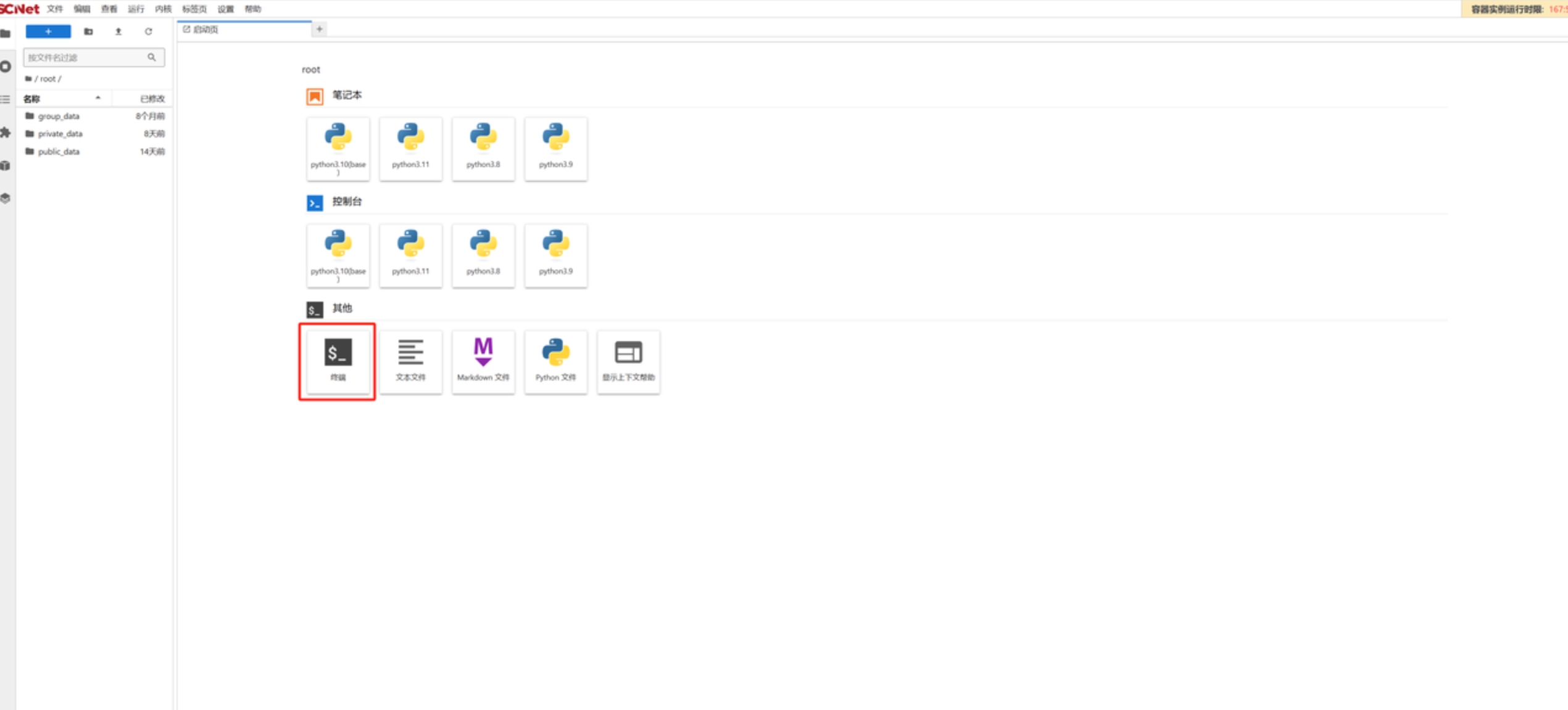
cd private_data
mkdir -p my/Llama3随后进入项目文件夹cd my/ Llama3 ,此时的notebook处在一个完全干净的运行环境与项目空间。
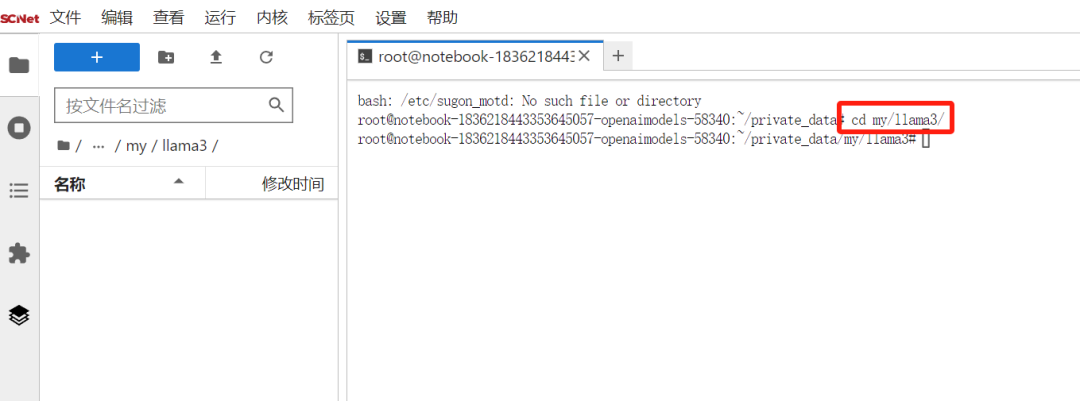
第一步:导入模型文件
导入模型文件有多种方法,我们推荐从超算互联网获取Llama3模型文件,登录超算互联网搜索并选择“Meta-Llama-3-8B-Instruct”模型商品,勾选服务协议后,点击“立即使用”,等待商品交付完成,点击“查看”;如果之前购买过商品,点击“去使用”,即可进入已购商品详情页面。
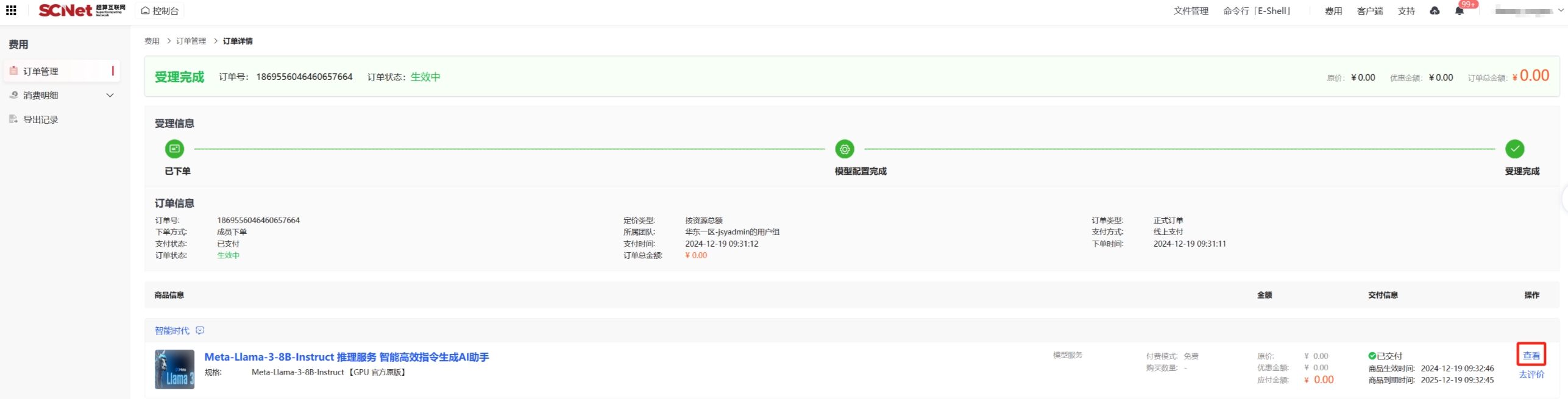
点击“文件管理”

找到模型文件对应的文件夹(购买的模型在apprepo/model/购买日期/模型名 文件夹下)。点击“在命令行中打开"按钮。

然后使用pwd查看模型文件路径,并复制路径
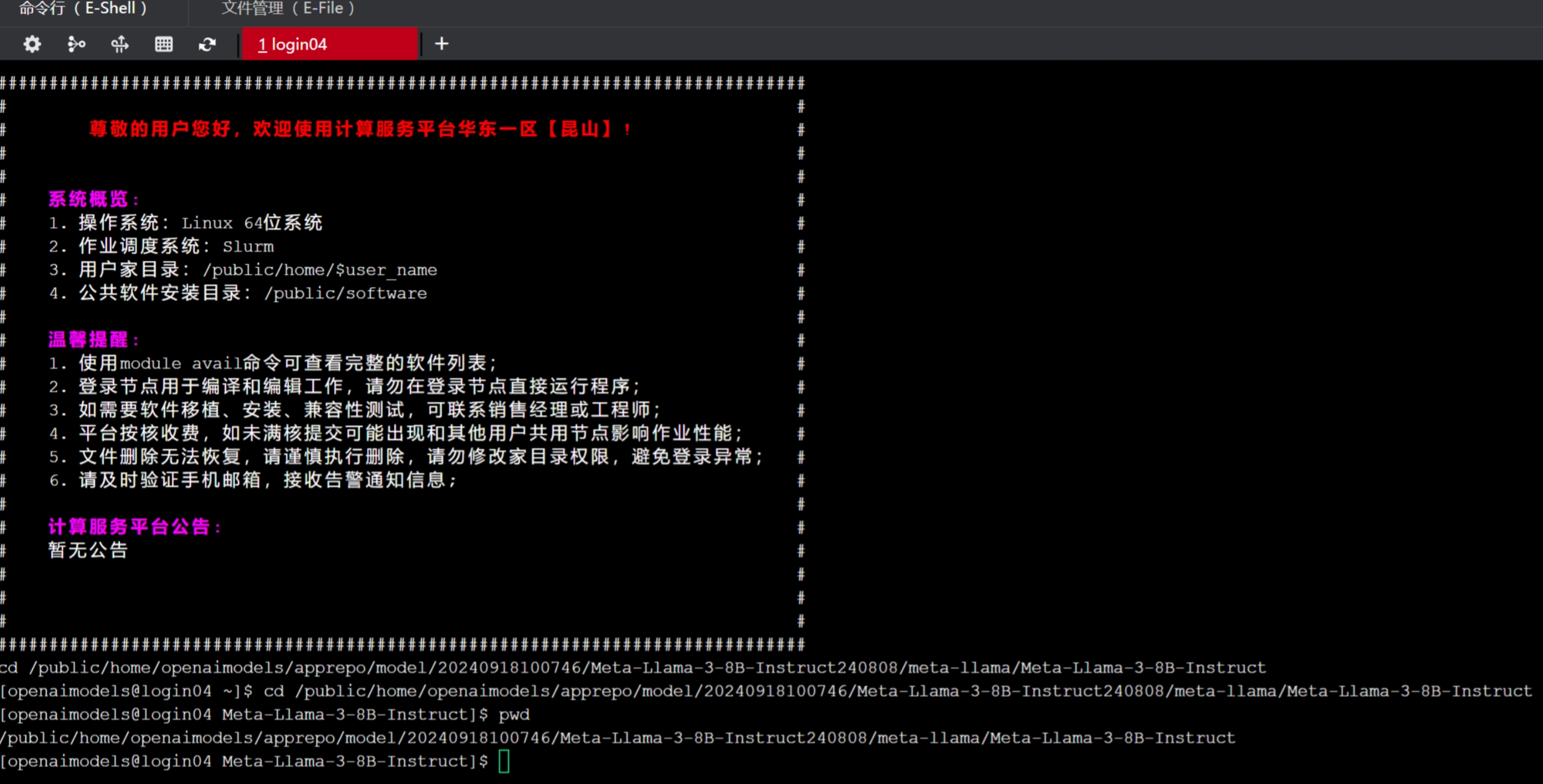
再回到之前创建的项目文件夹终端页面,使用命令cp -r 路径 ./ 复制模型文件,等待模型文件复制完成后,即可看到Meta-Llama-3-8B-Instruct模型文件:
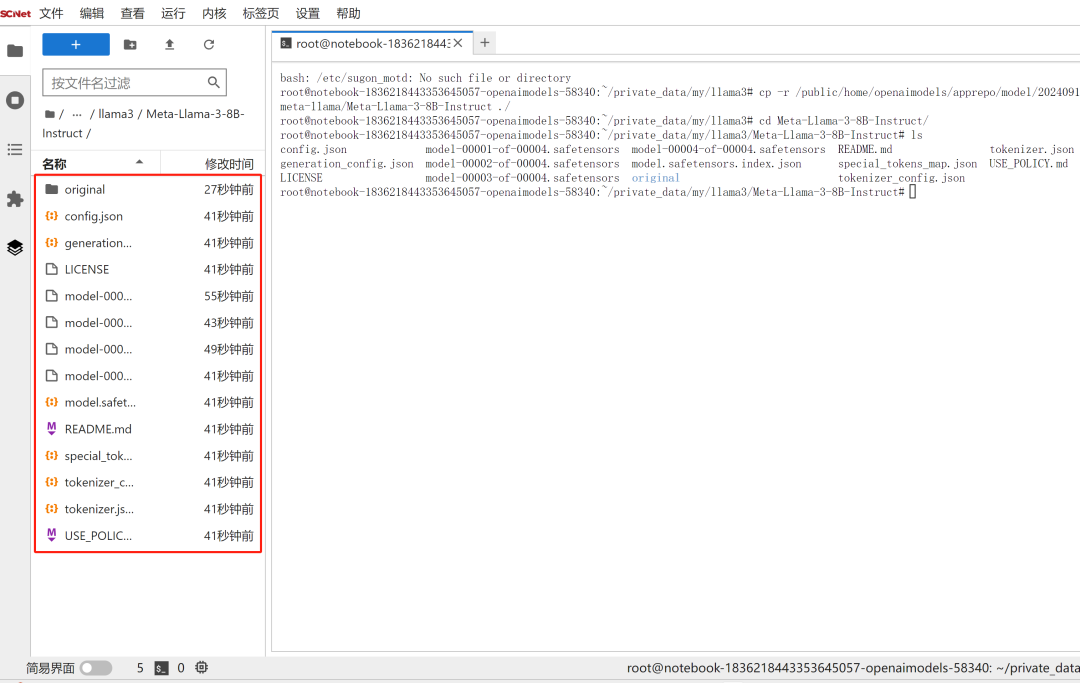
第二步:安装模型运行的依赖包:
pip install transformers第三步:新建笔记本,重命名为inference,用于编写代码运行模型:
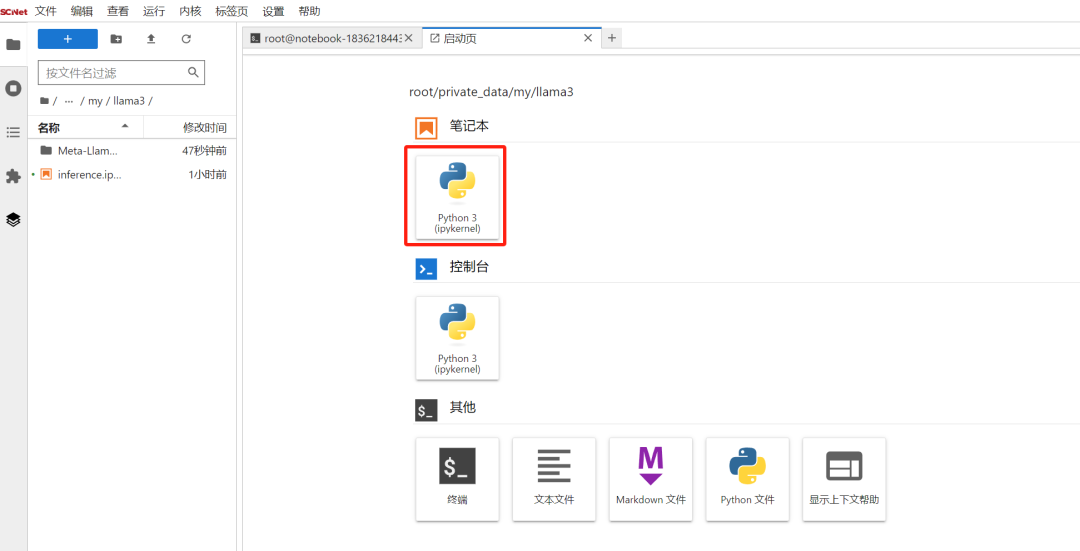
第四步:编写代码,先导入相关模块,依次运行代码:
#导入相关模块
import os
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer#设置tokenizers 是否使用并行处理
os.environ["TOKENIZERS_PARALLELISM"] = "false"#检查是否有可用的 GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")#设置模型路径
model_id = "./Meta-Llama-3-8B-Instruct"#加载模型之前释放显存
torch.cuda.empty_cache()#加载模型
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
device_map=device
).eval()
tokenizer = AutoTokenizer.from_pretrained(model_id)#输入prompt
prompt = "请介绍一下自己"#模型推理
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to("cuda")#设置流式输出
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512,
temperature = 0.7,
streamer=streamer,
pad_token_id=tokenizer.eos_token_id
)模型加载完成后,输入prompt,进行模型推理。这里,您也可以设置流式输出,以便实时查看推理结果。
最后,我们可以在单元格下方看到Meta-Llama-3-8B-Instruct模型对问题的回答,如果想继续提问,可修改prompt,运行单元格代码查看答案,也可以根据自己的喜好设置相关参数和表现形式。
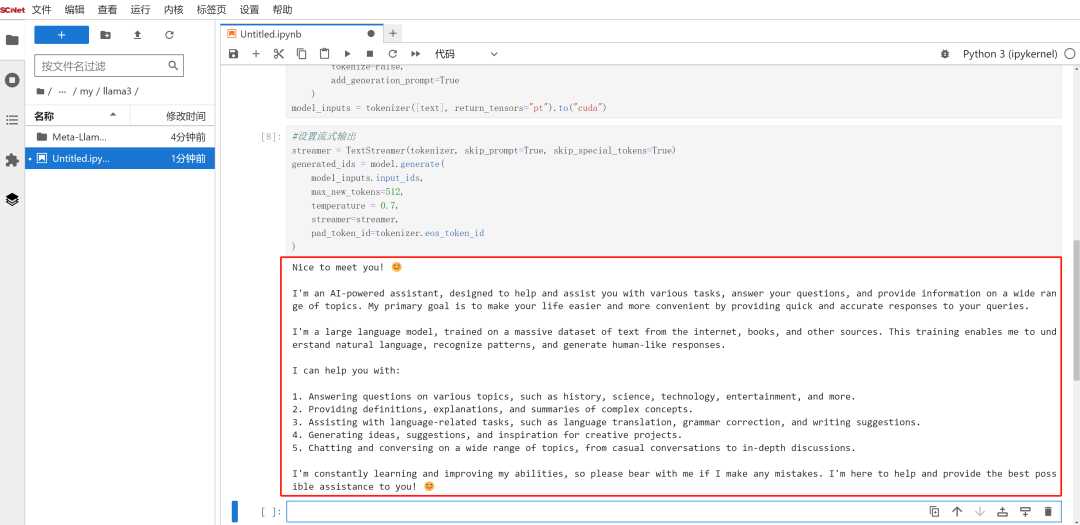
以上就是本次实操教程的全部内容了,大家可参照此步骤,在超算互联网使用GPU基础镜像部署想要的大模型服务。