人工智能服务
>
最佳实践
>
异构加速卡基础镜像微调Llama3
在SCNte最佳实践系列第12期,我们介绍了如何在超算互联网使用官方GPU基础镜像部署大语言模型 Llama3,虽然Llama3的预训练数据里包含多种语言,但原生模型在处理中文时表现并不理想。
为了进一步提升Llama 3在中文语境下的应用能力和满足特定领域的需求,本次实操,我们手把手演示如何在超算互联网使用官方的异构加速卡基础镜像微调Llama-3-8B-Instruct,使其更好地适应中文的语言特点,提供更加个性化和高效的交互体验。
登录超算互联网https://www.scnet.cn个人账号,点击右上角“控制台”;
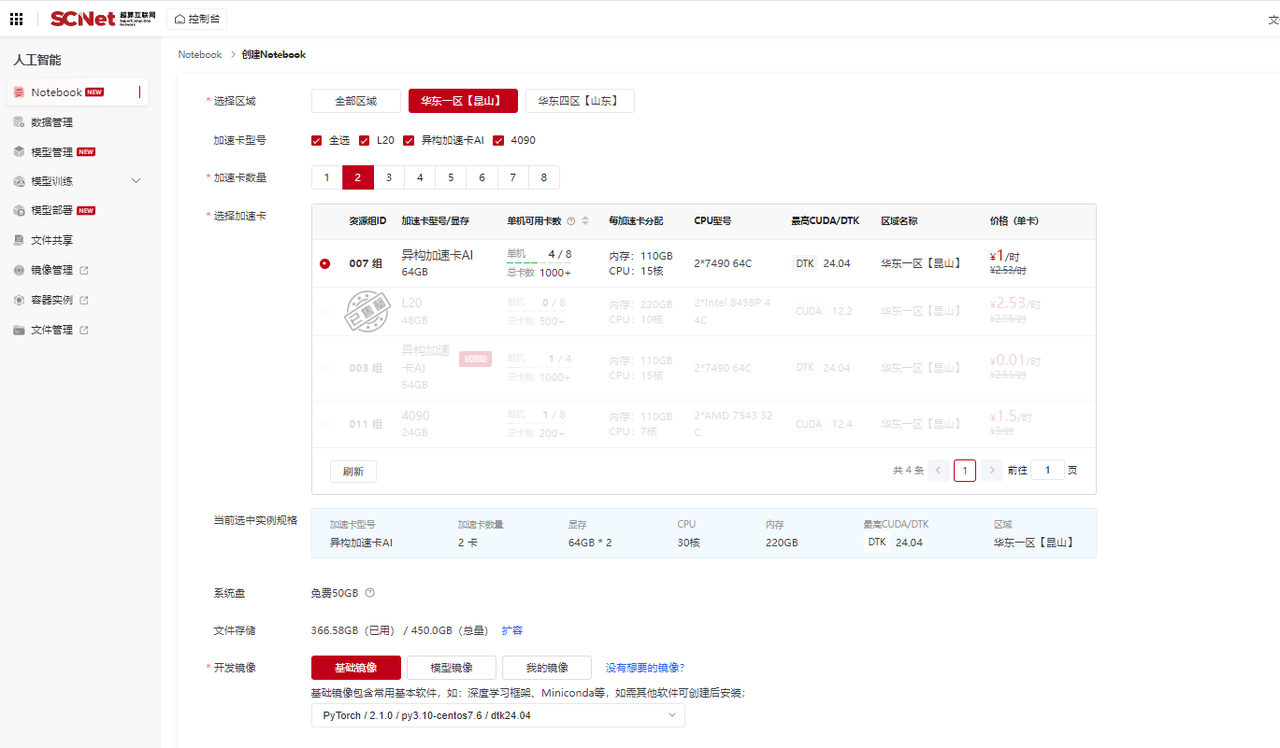
点击快捷入口中的“Notebook”,进入创建Notebook页面;

选择区域、两张异构加速卡AI,点击“基础镜像”,在列表中选择PyTorch-2.1.0/py-3.10/centos-7.6/dtk-24.04 镜像,点击创建;
创建成功后,点击“JupyterLab”进入Notebook页面;

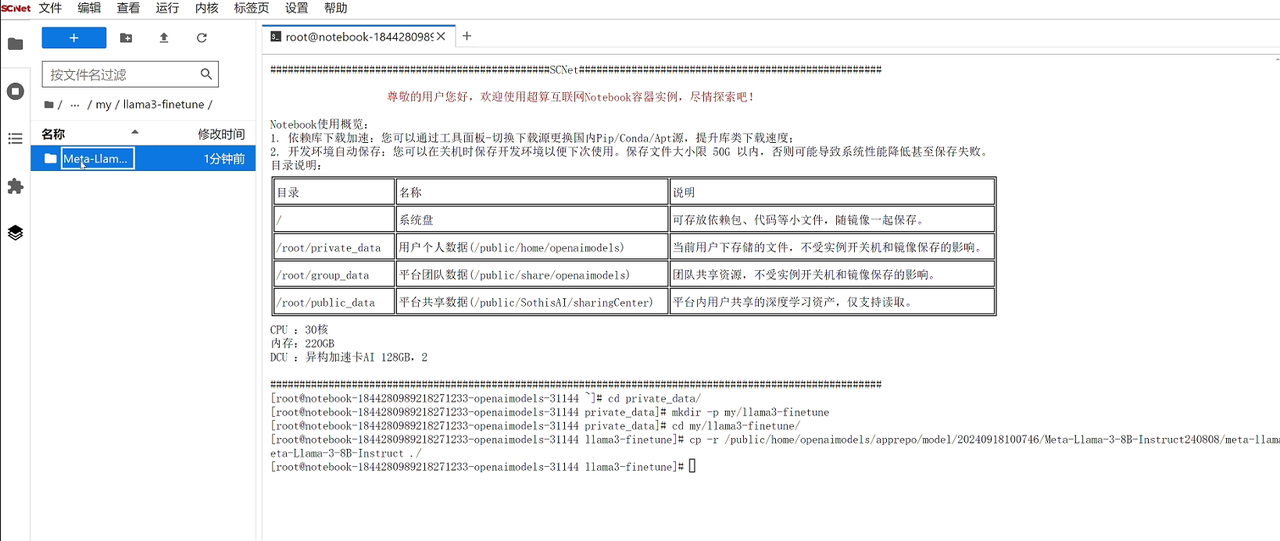
在Notebook中打开“终端”页面,使用命令进入private_data文件夹,创建个人空间和项目文件夹;
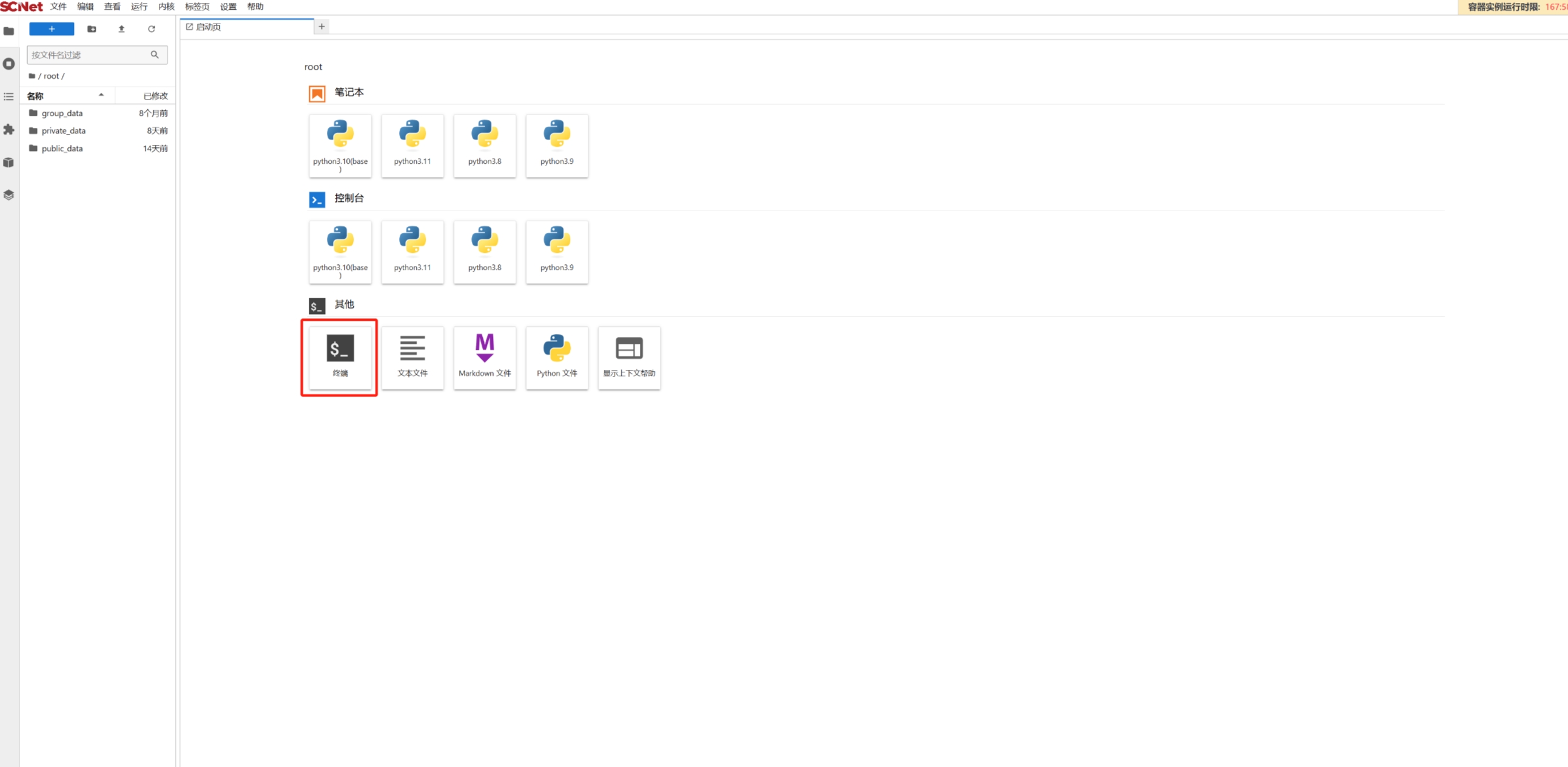
cd private_data
mkdir -p my/llama3-finetune随后进入项目文件夹cd my/llama3-finetune,此时的notebook处在一个完全干净的运行环境与项目空间。
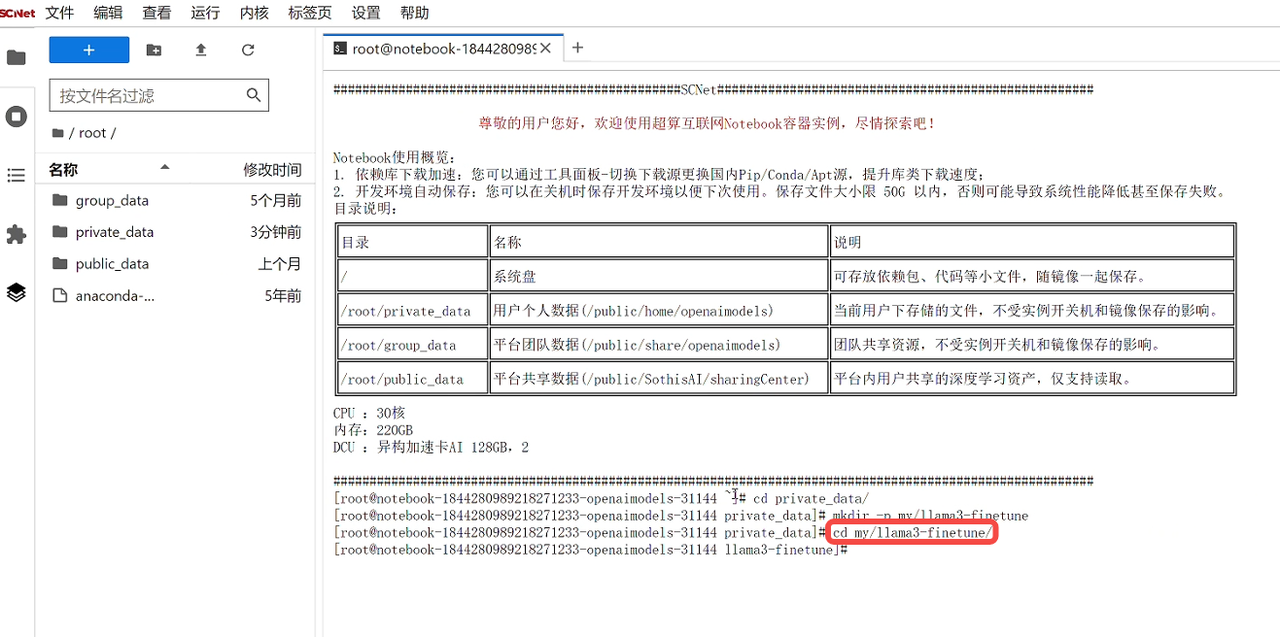
第一步:导入模型文件
导入模型文件有多种方法,我们推荐从超算互联网获取Meta-Llama-3-8B-Instruct模型文件,登录超算互联网搜索并选择“Meta-Llama-3-8B-Instruct”模型商品,勾选服务协议后,点击“立即使用”,等待商品交付完成,点击“查看”;如果之前购买过商品,点击“去使用”,即可进入已购商品详情页面,点击“文件管理”,找到模型文件对应的文件夹(购买的模型在apprepo/model/购买日期/模型名 文件夹下),点击“在命令行中打开"按钮。

使用pwd查看模型文件路径,并复制路径:
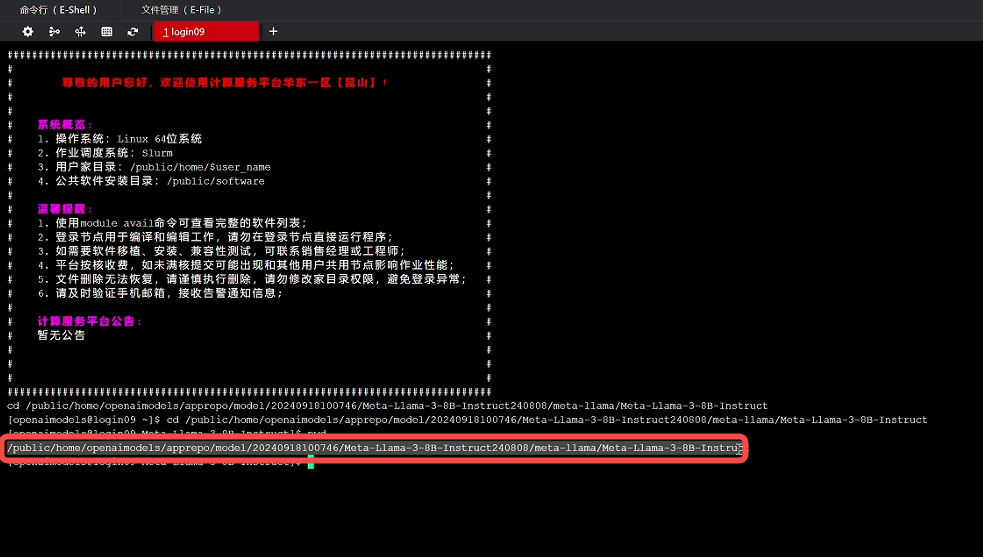
再回到之前创建的项目文件夹终端页面,使用命令cp -r 路径 ./ 复制模型文件,等待模型文件复制完成后,即可看到Meta-Llama-3-8B-Instruct模型文件:
第二步:安装模型运行的依赖包:
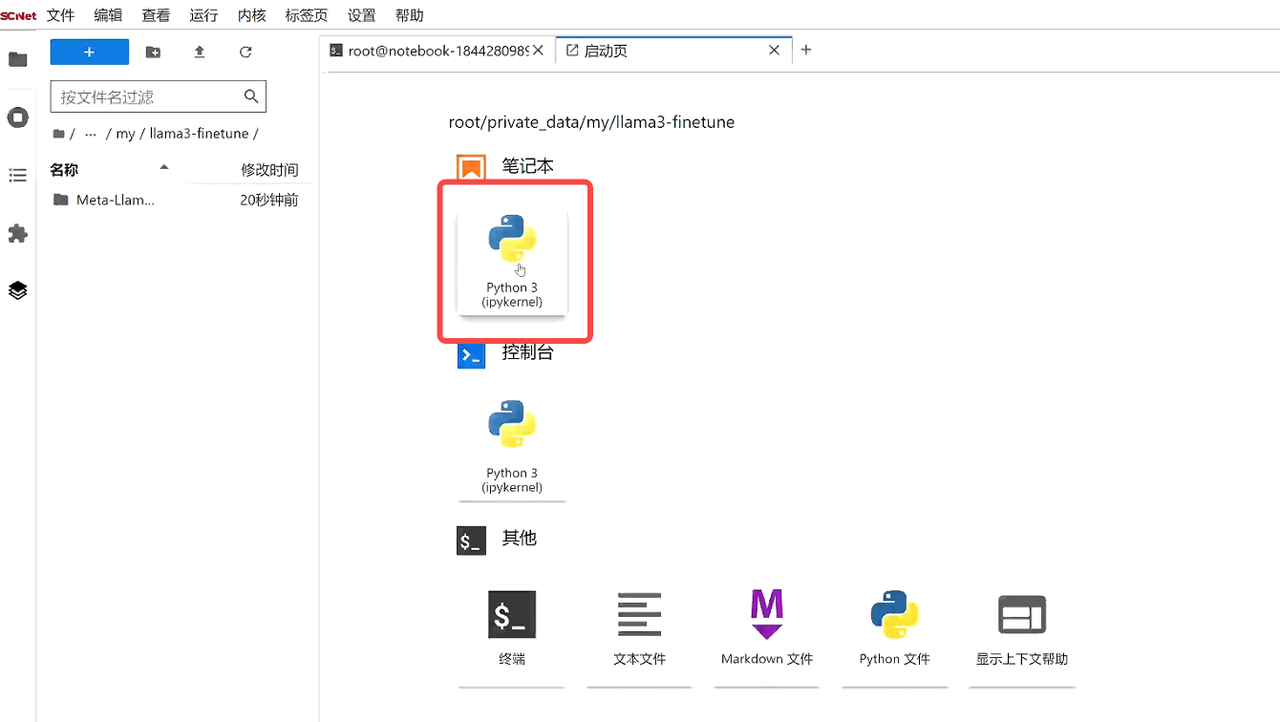
pip install transformers accelerate第三步:新建笔记本,重命名为inference,用于编写代码运行模型:
第四步:编写模型加载代码,随后使用“shift+enter”运行代码:
#导入相关模块
import os
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
#设置tokenizers 是否使用并行处理
os.environ["TOKENIZERS_PARALLELISM"] = "false"
#检查是否有可用的 GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
#设置模型路径
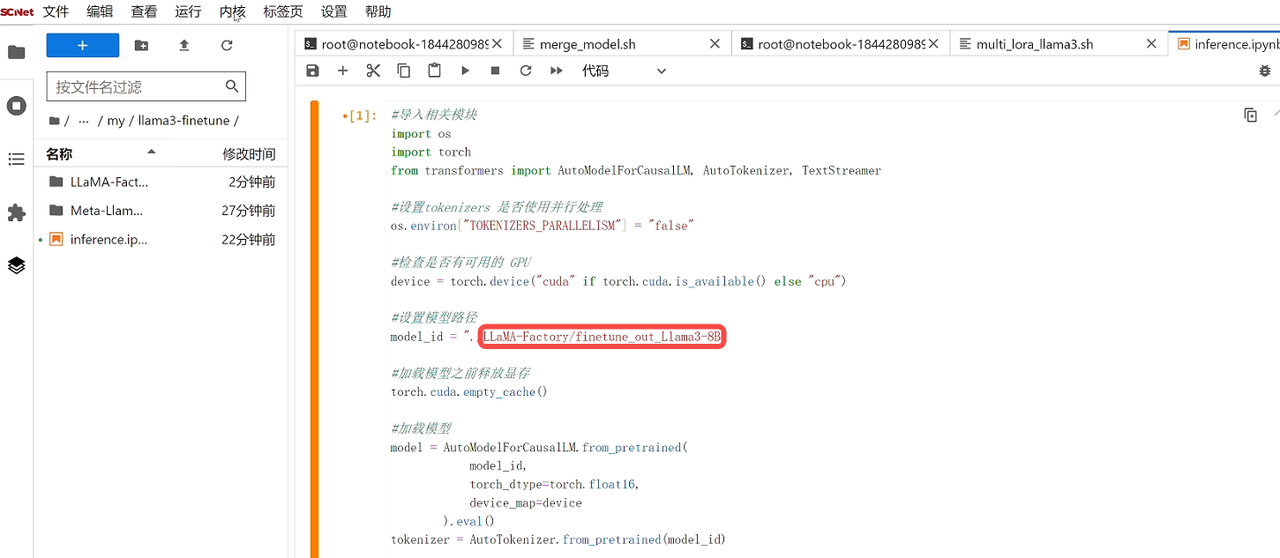
model_id = "./Meta-Llama-3-8B-Instruct"
#加载模型之前释放显存
torch.cuda.empty_cache()
#加载模型
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
device_map=device
).eval()
tokenizer = AutoTokenizer.from_pretrained(model_id)第五步:编写模型推理代码:
#输入prompt
prompt = "请介绍一下自己"
#模型推理
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to("cuda")
#设置流式输出
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512,
temperature = 0.7,
streamer=streamer,
pad_token_id=tokenizer.eos_token_id
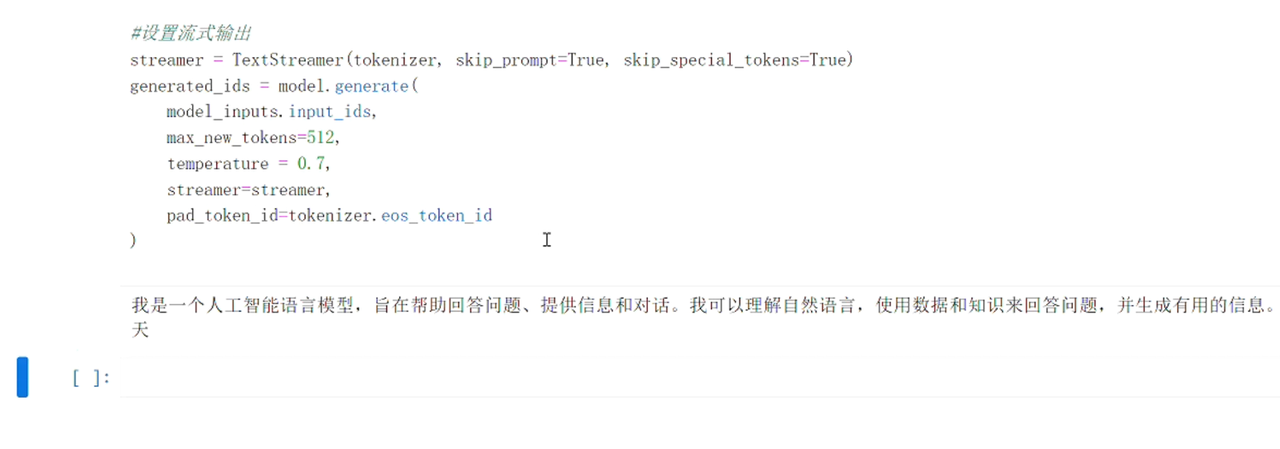
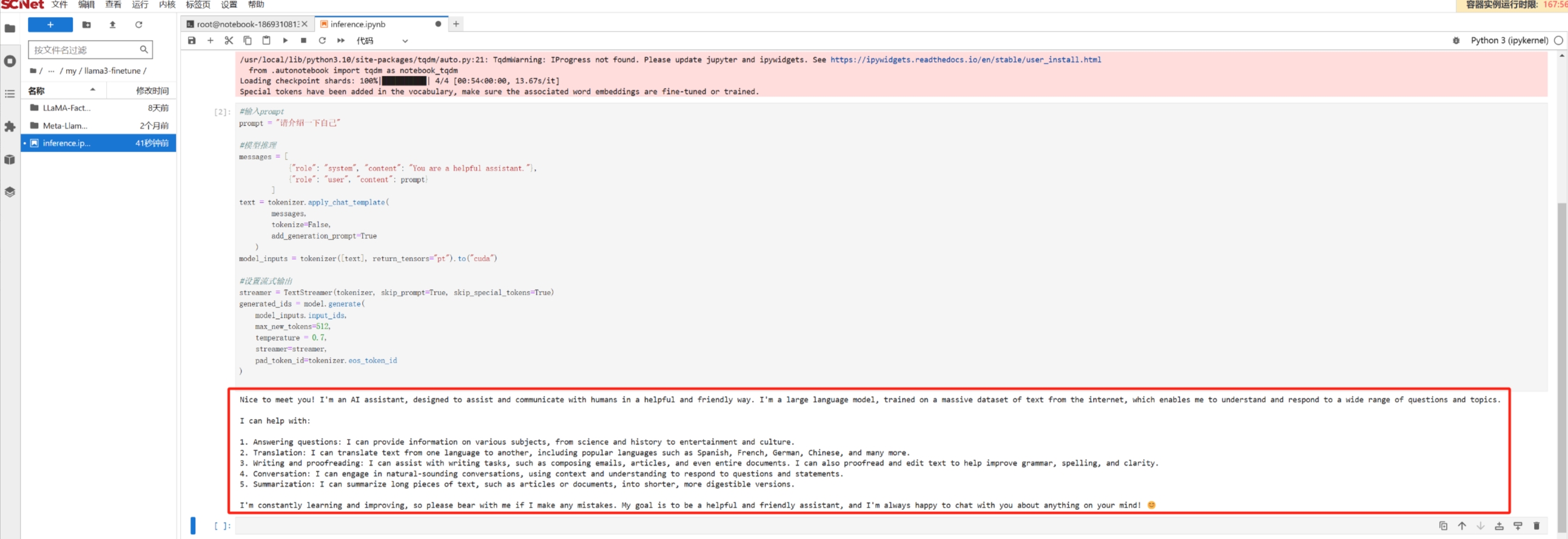
)此时,我们可以在单元格下方看到Meta-Llama-3-8B-Instruct模型使用英文对问题进行回答,说明原模型没有中文能力。
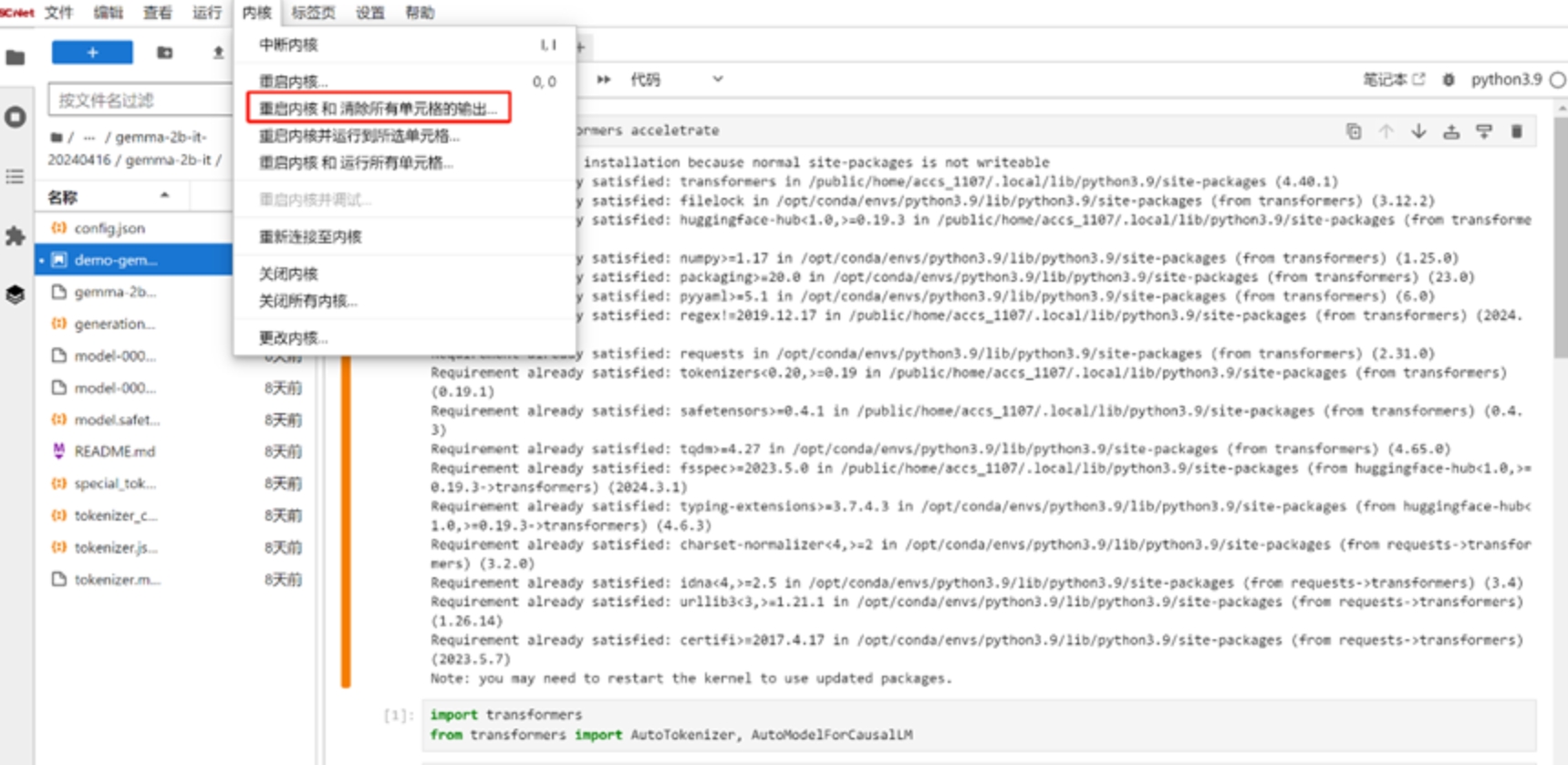
随后重启内核以释放资源。
第一步:导入微调模型的框架:
微调有很多方法,我们采用LLaMA-Factory方法,推荐在超算互联网搜索LLaMA-Factory,选择应用商城中的“LLaMA-Factory”商品,勾选服务协议后,点击“立即使用”,如果之前购买过商品,点击“去使用”,交付完成后点击下载到区域:
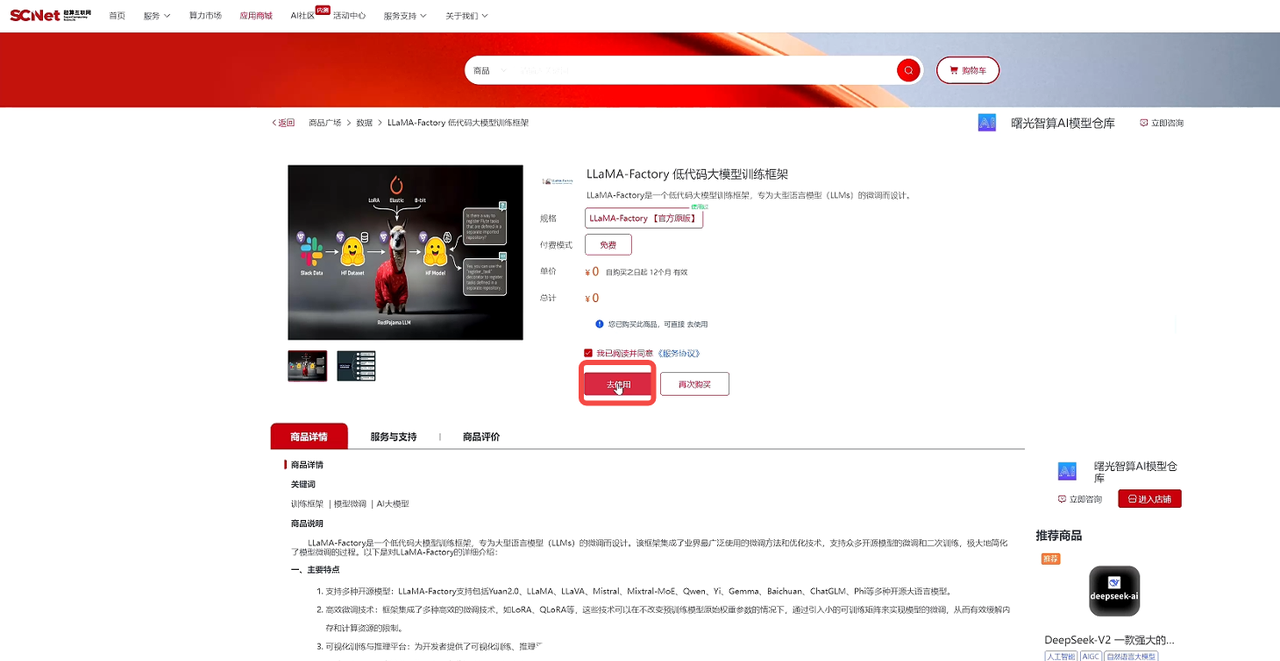
点击新建文件夹,命名为LLaMA-Factory,再选择该文件夹,点击确认,开始下载:
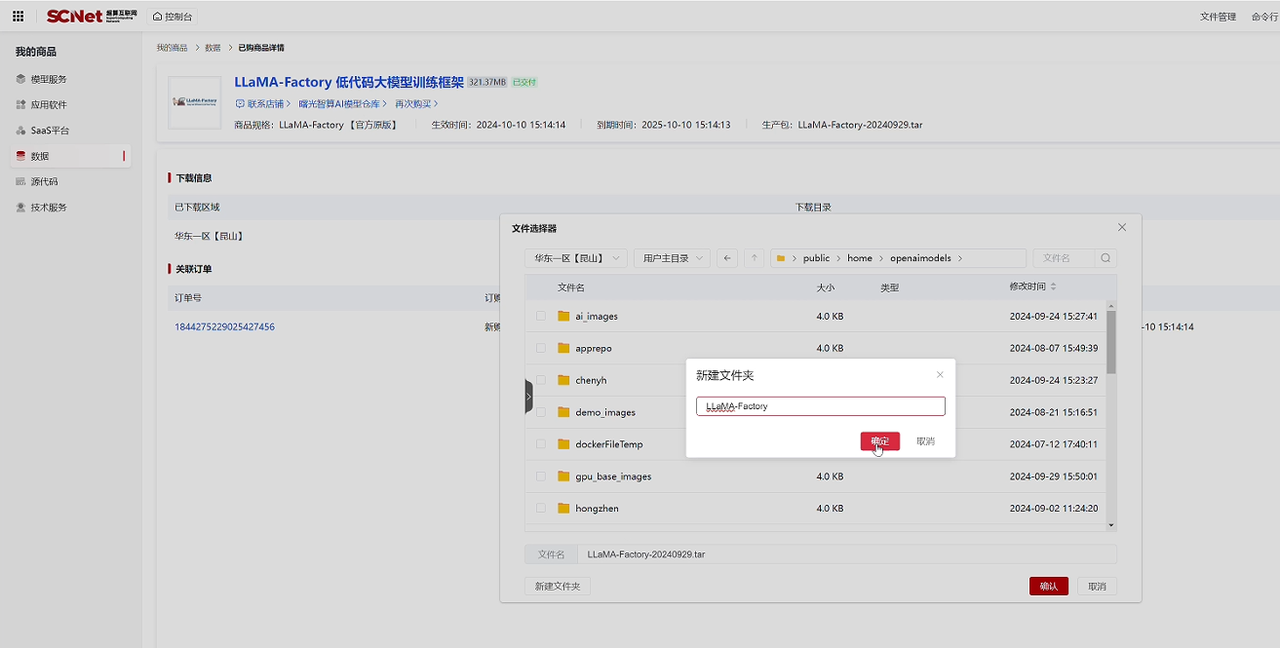
下载完成后,点击“在区域中打开”,再点击“在命令行中打开”: 

使用 pwd 查看模型文件路径,并复制路径:
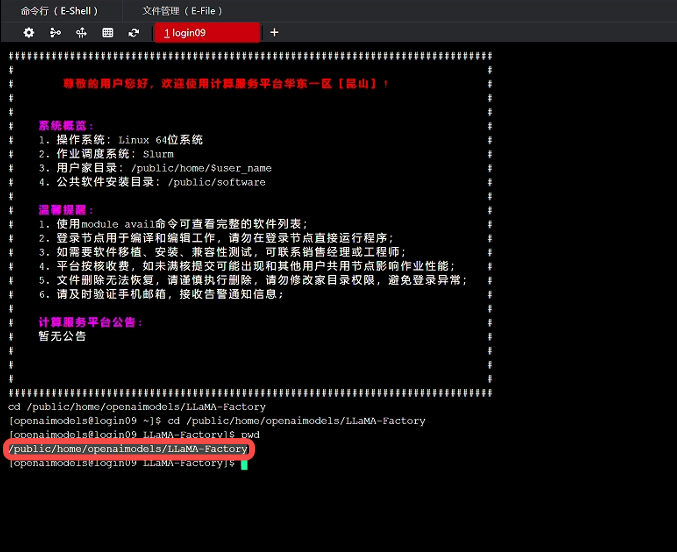
回到之前创建的项目文件夹终端页面,移动LLaMA-Factory工程文件,即可看到LLaMA-Factory工程文件的压缩包:
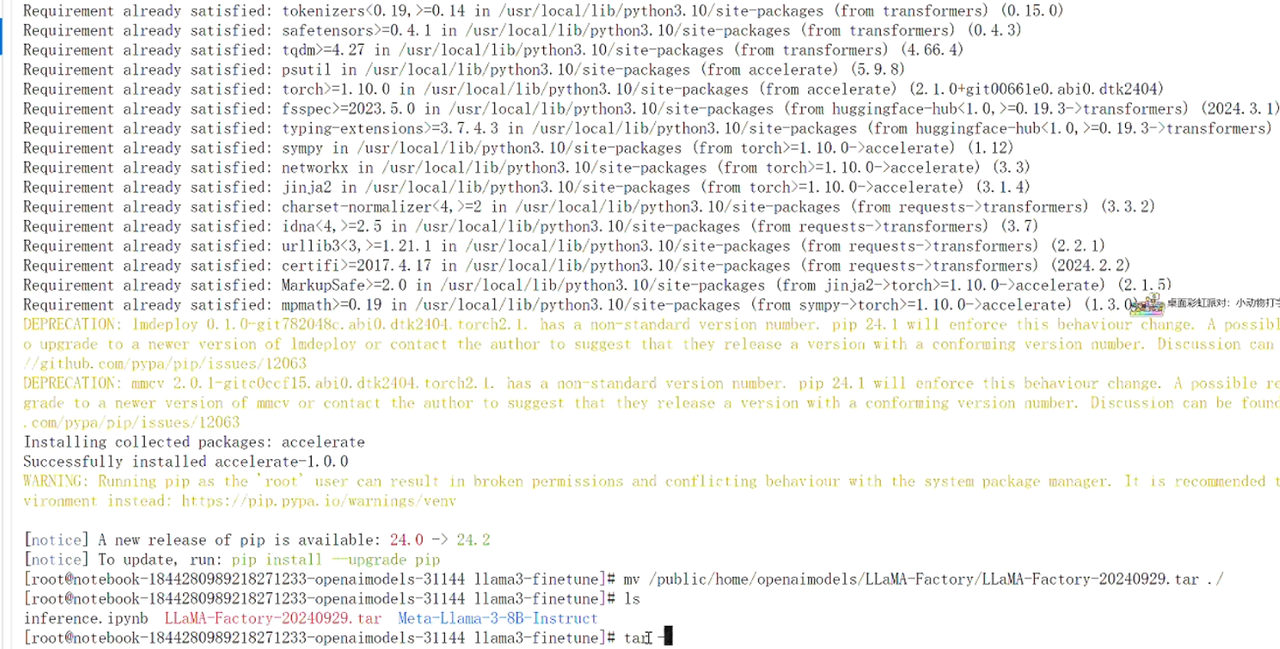
最后解压压缩包,解压完成后删除压缩包:

第二步:进入LLaMA-Factory文件夹:
cd LLaMA-Factory
进入data文件夹,准备微调模型数据,首先将原始数据备份一份,再删除原数据:
cd data
cp alpaca_data_zh_51k.json alpaca_data_zh_51k.json.bak
rm alpaca_data_zh_51k.json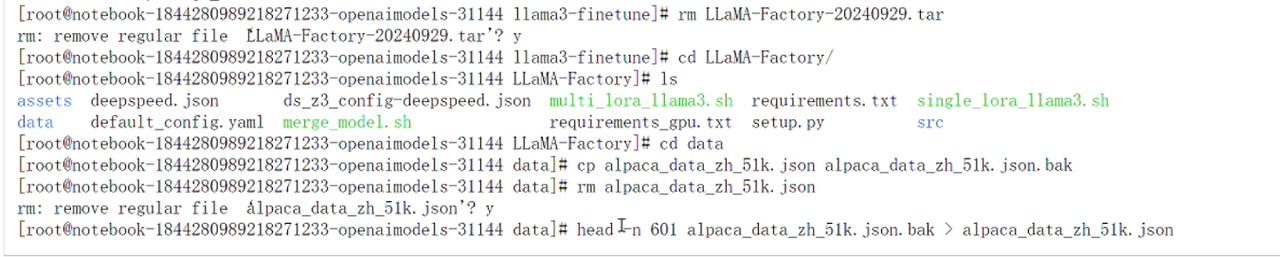
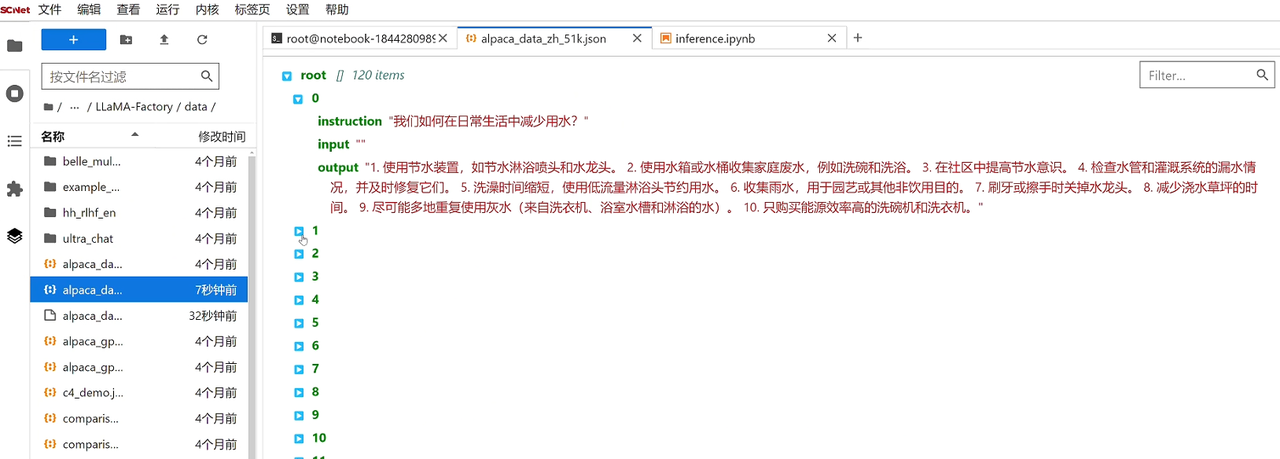
我们取前120条数据进行微调,由于1条数据在文件中占据5行位置,所以取head -n 601,并在数据的末尾添加上结束符。
head -n 601 alpaca_data_zh_51k.json.bak > alpaca_data_zh_51k.json
sed -i '$ s/,$/]/' alpaca_data_zh_51k.json
最后查看训练数据:这里可以自定义训练数据的大小,训练数据越大,训练时间越长:
第三步:安装模型微调需要的依赖包:
异构加速卡所需要的依赖包已写在requirements文件中,直接使用pip install安装即可:
pip install -r requirements.txt
第四步:运行脚本,训练模型:
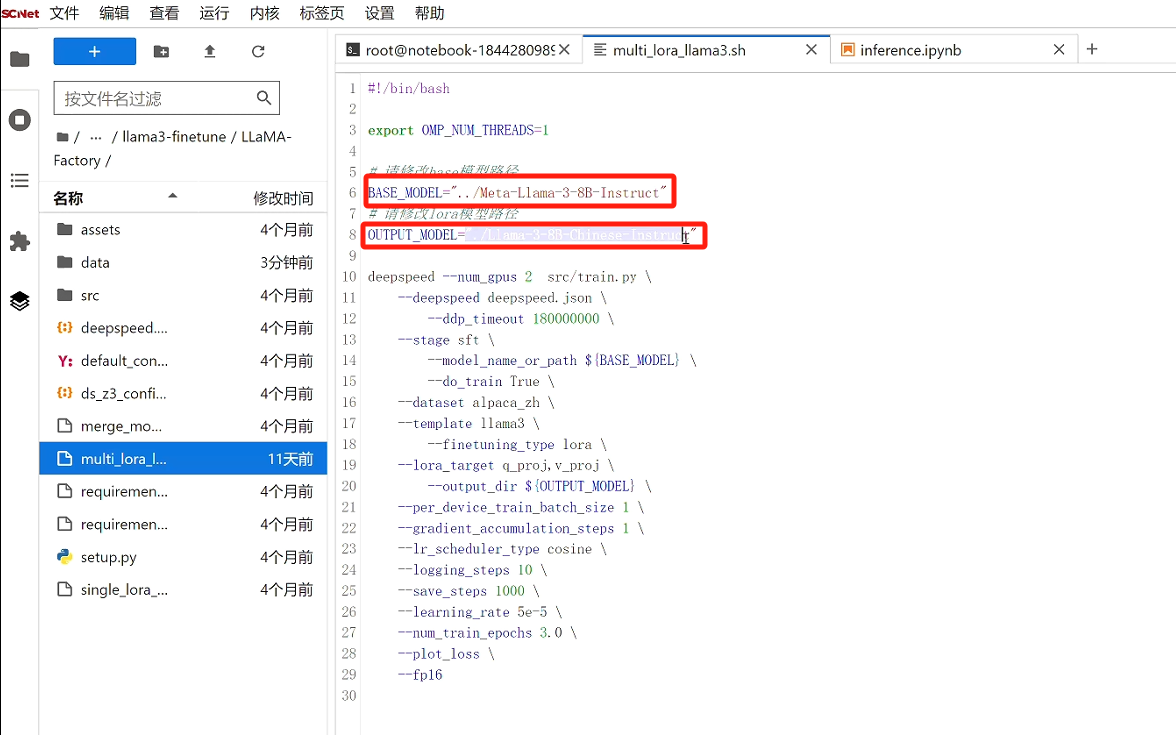
点击LLaMA-Factory文件夹下的multi_lora_llama3.sh文件,保证基座模型路径正确,并自定义微调后模型名称:
使用命令在后台运行 multi_lora_llama3.sh 脚本文件,开始训练模型,并将脚本的所有输出都记录到 output.log 文件中,使用tail命令实时查看 output.log 文件的末尾内容,在终端可以实时看到训练过程,数据量和参数的设置都会影响训练时间:
nohup ./multi_lora_llama3.sh > output.log 2>&1 &
tail -f output.log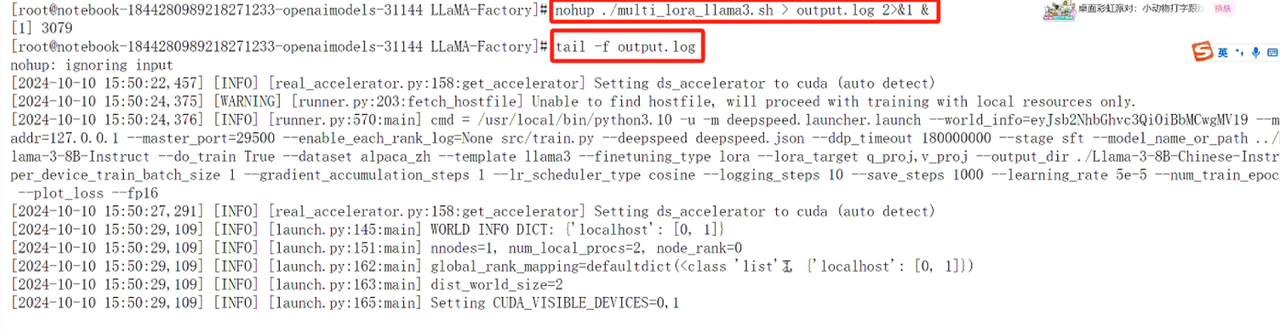
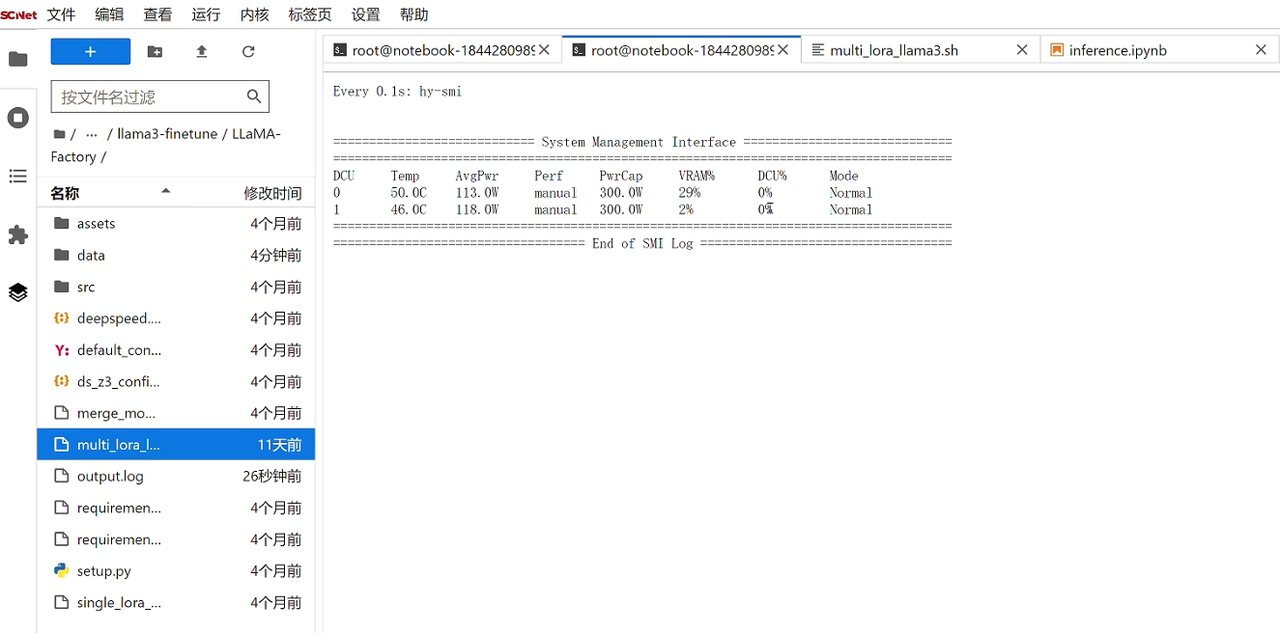
期间可另起一个终端,输入命令 watch -n 0.1 hy-smi,查看加速卡占用情况:
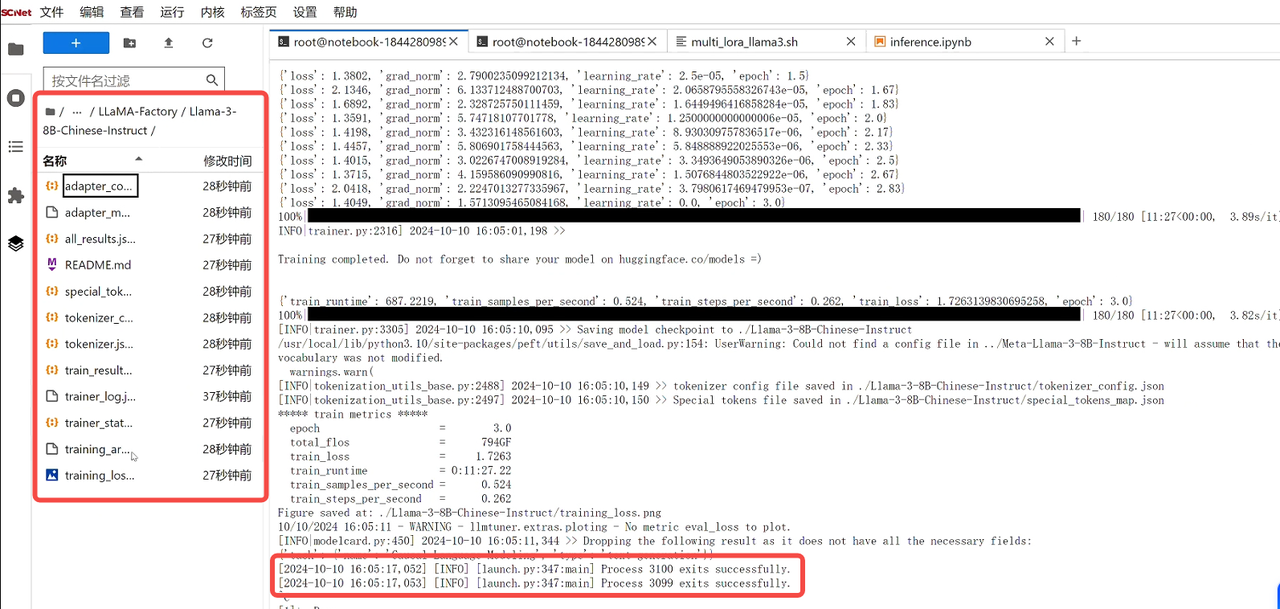
模型训练完成后,在终端会出现对应的标志,同时在定义的路径下,会生成微调后的文件:
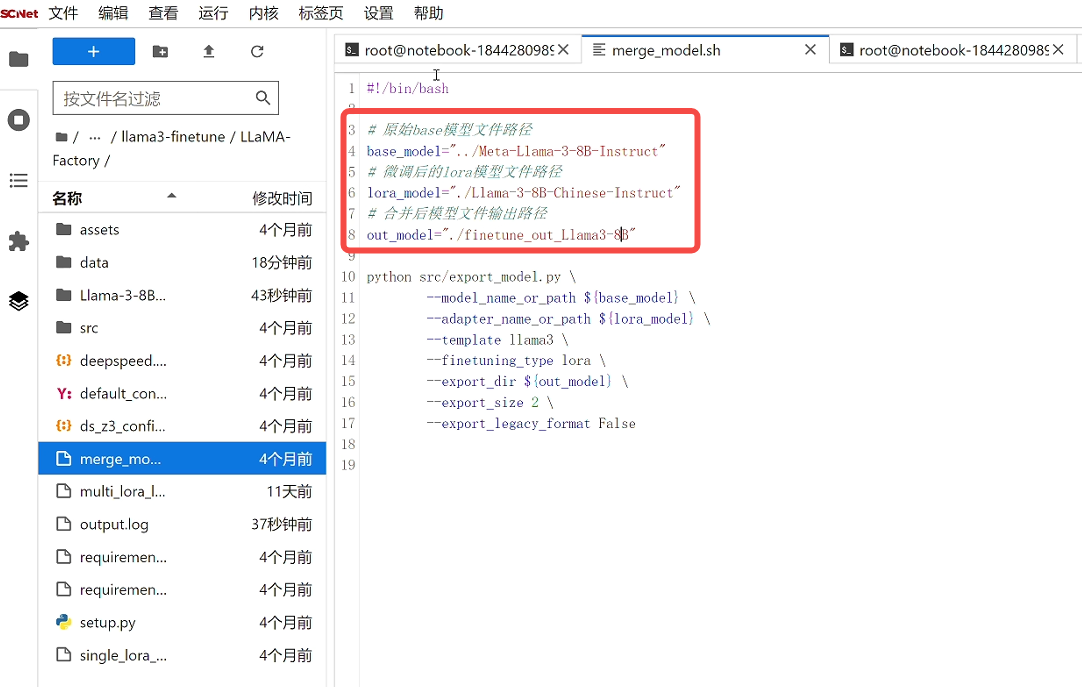
我们打开merge_model.sh文件,确认基座模型、微调权重模型是否正确,并自定义合并后模型文件的路径和名称:
输入命令 ./merge_model.sh 运行脚本,进行模型合并。
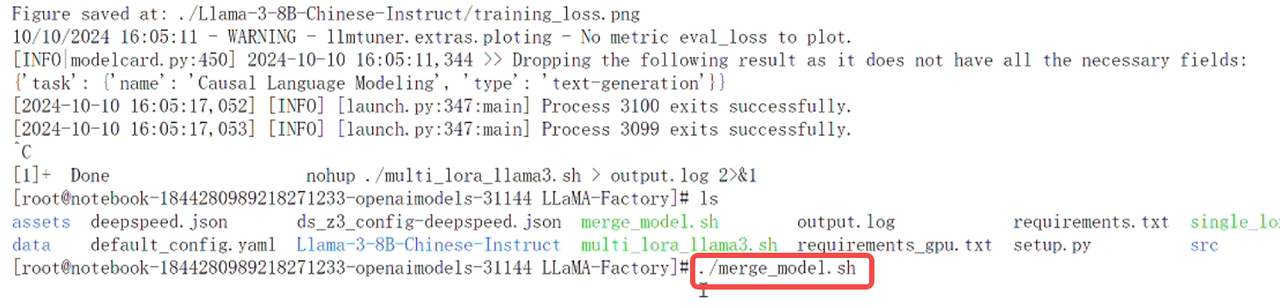
脚本执行完成后,会在指定的路径下生成合并后的模型文件,我们进入目录,使用pwd获取模型路径,并复制路径。
最后,我们验证微调后的模型的效果。回到inference文件,将模型路径更改为合并后的模型,重启内核以释放显存,依次运行单元格代码。我们可以在单元格下方看到,微调后的模型针对同一个问题,此时使用中文进行回答,说明微调后的模型具有中文能力。