高性能计算服务
>
命令行专区
>
安装自定义软件
本章主要介绍如何在集群上面安装自定义软件。
对于C、C++、Frortran等编译型语言,需要使用编译器将源代码,转变为计算机可以执行的二进制文件。下面会介绍如何使用gcc编译器和intel编译器来编译源代码。
GCC(GNU Compiler Collection)即GNU编译器套件,属于一种编程语言编译器,其原名为GCC(GNU C Compiler)即GNU c语言编译器。GCC可处理C、C++、Fortran、Pascal、Objective-C、Java,以及Ada与其它语言,以下是对应的编程语言和编译器类型。
| 编程语言 | 编译器名称 |
|---|---|
| C | gcc |
| C++ | g++ |
| Fortran77 | gfortran |
| Fortran90/95 | gfortran |
准备好需要编译的C语言源代码如下,命名为hello.c。
#include<stdio.h>
int main(){
printf("hello word!\n");
return 0;
}在命令行中使用下面的命令查看编译器。
module av compiler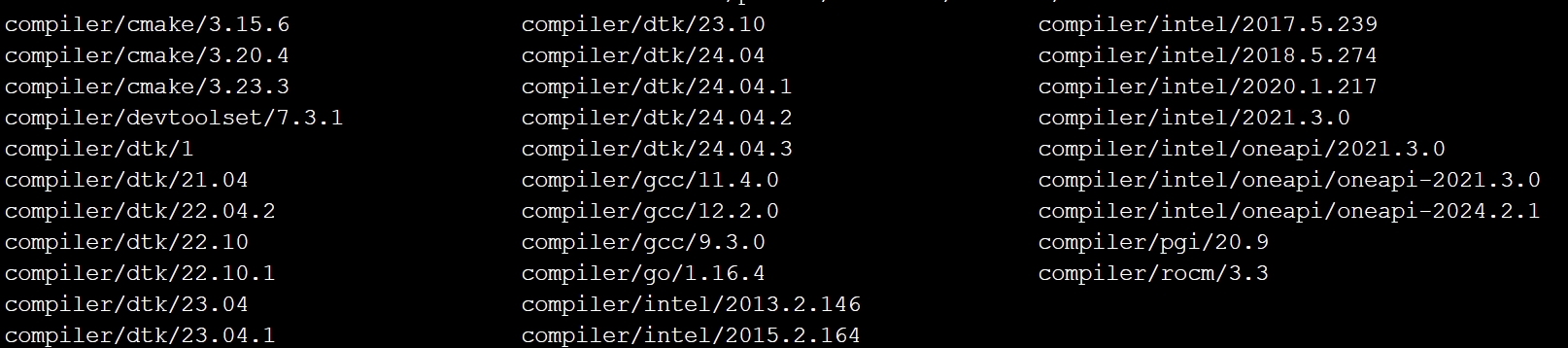
在命令行中使用下面的命令加载相应的编译器环境,这边使用gcc9.3.0。
module purge
module load compiler/gcc/9.3.0查看编译器环境。
module list
编译C语言代码。
gcc hello.c -o hello.out编译完成后在和hello.c的同级目录下面会生成hello.out文件

运行程序,需要使用提交任务的脚本,相应的脚本示例如下,命名为c.slurm。
#!/bin/bash
#SBATCH -J hello_world # 作业的名称 可根据需要自行命名
#SBATCH -p xahcnormal # 在指定分区中分配资源,根据所拥有的资源修改
#SBATCH -N 1 # 申请的节点数1个
#SBATCH --ntasks-per-node=4 # 每个节点运行4个任务,使用4个核心
module purge
module load compiler/gcc/9.3.0 #加载编译环境
./hello.out提交作业。
sbatch c.slurm查看作业运行状态,R就表示作业在运行当中。
squeue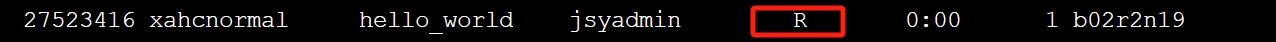
运行结束之后会在当前目录生成slurm-xxx.out,其中作业xxx为作业号,即上图中的27523416,每个作业的作业号都是不一样的。这个文件很重要,请不要随意删除这个文件。如果遇到作业报错,这个文件可以帮工程师分析报错原因。

查看结果。
cat slurm-27523416.out
如果需要编译C++、Frortran等源码,编译方式是类似的,只是编译器的名称不一样而已。
OpenMPI是一个免费的、开源的MPI实现,兼容MPI-1和MPI-2标准。它用于在集群计算环境中进行并行计算,采用消息传递编程模型,支持多种并行计算的应用场景,包括科学计算、机器学习、数据分析等。
| 编程语言 | 编译器名称 |
|---|---|
| C | mpicc |
| C++ | mpicxx和mpic++ |
| Fortran | mpifort,mpif90和mpif77 |
准备好需要编译的C语言源代码如下,命名为hello_openmpi.c。
#include <mpi.h>
#include <stdio.h>
int main(int argc, char** argv){
MPI_Init(NULL, NULL);
int world_size;
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
int world_rank;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
char processor_name[MPI_MAX_PROCESSOR_NAME];
int name_len;
MPI_Get_processor_name(processor_name, &name_len);
printf("Hello world from processor %s, rank %d out of %d processors\n",processor_name, world_rank, world_size);
MPI_Finalize();
}在命令行中使用下面的命令查看mpi编译器。
module av mpi
在命令行中使用下面的命令加载相应的编译器环境,这边使用gcc9.3.0和openmpi-4.1.5,注意相应的gcc和openmpi需要同时加载。
module purge
module load compiler/gcc/9.3.0
module load mpi/openmpi/openmpi-4.1.5-gcc9.3.0编译C语言代码。
mpicc hello_openmpi.c -o hello_openmpi.out运行程序,需要使用提交任务的脚本,相应的脚本示例如下,命名为c_openmpi.slurm。
#!/bin/bash
#SBATCH -J hello_world_openmpi # 作业的名称 可根据需要自行命名
#SBATCH -p xahcnormal # 在指定分区中分配资源,根据所拥有的资源修改
#SBATCH -N 1 # 申请的节点数1个
#SBATCH --ntasks-per-node=4 # 每个节点运行4个任务,使用4个核心
module purge
module load compiler/gcc/9.3.0
module load mpi/openmpi/openmpi-4.1.5-gcc9.3.0 #加载编译环境
mpirun -np $SLURM_NTASKS ./hello_openmpi.out提交任务。
sbatch c_openmpi.slurm查看结果。
cat slurm-27523924.out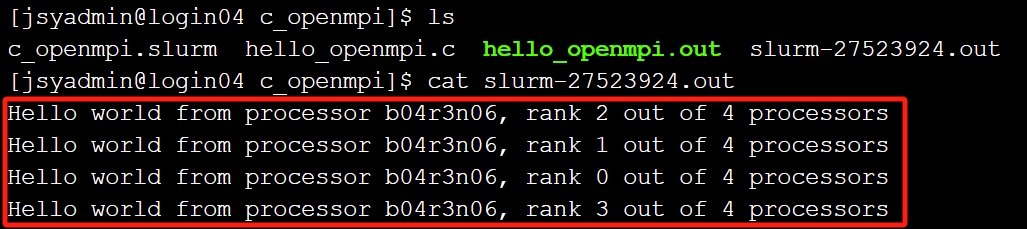
如果需要编译C++、Frortran等源码,编译方式是类似的,只是编译器的名称不一样而已。
Intel编译器是Intel公司发布的x86平台(IA32/INTEL64/IA64/MIC)编译器 产品,支持C/C++/Fortran编程语言。安装Intel编译器之后,一般会自动安装MKL(Math Kernel Library)数学核心库。
| 编程语言 | 编译器名称 |
|---|---|
| C | icc |
| C++ | icpc |
| Fortran77 | ifort |
| Fortran90/95 | ifort |
准备好需要编译的C语言源代码如下,命名为hello_Intel.c。
#include<stdio.h>
int main(){
printf("hello word!\n");
return 0;
}在命令行中使用下面的命令查看编译器。
module av compiler
在命令行中使用下面的命令加载相应的编译器环境,这边使用Intel2017。
module purge
module load compiler/intel/2017.5.239编译C语言代码。
icc hello_Intel.c -o hello_Intel.out运行程序,需要使用提交任务的脚本,相应的脚本示例如下,命名为c_Intel.slurm。
#!/bin/bash
#SBATCH -J hello_world_Intel # 作业的名称 可根据需要自行命名
#SBATCH -p xahcnormal # 在指定分区中分配资源,根据所拥有的资源修改
#SBATCH -N 1 # 申请的节点数1个
#SBATCH --ntasks-per-node=4 # 每个节点运行4个任务,使用4个核心
module purge
module load compiler/intel/2017.5.239 #加载编译环境
./hello_Intel.out提交任务。
sbatch c_Intel.slurm查看结果。
cat slurm-27524070.out
如果需要编译C++、Frortran等源码,编译方式是类似的,只是编译器的名称不一样而已。
英特尔MPI 库是一个实现开源 MPICH 规范的多结构消息传递库。使用该库创建、维护和测试高级、复杂的应用程序,这些应用程序在高性能计算 (HPC) 集群上表现很好。
| 编程语言 | 编译器名称 |
|---|---|
| C | mpiicc |
| C++ | mpiicpc |
| Fortran | mpiifort,mpiif90和mpiif77 |
准备好需要编译的C语言源代码如下,命名为hello_Intelmpi.c。
#include <mpi.h>
#include <stdio.h>
int main(int argc, char** argv){
MPI_Init(NULL, NULL);
int world_size;
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
int world_rank;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
char processor_name[MPI_MAX_PROCESSOR_NAME];
int name_len;
MPI_Get_processor_name(processor_name, &name_len);
printf("Hello world from processor %s, rank %d out of %d processors\n",processor_name, world_rank, world_size);
MPI_Finalize();
}在命令行中使用下面的命令查看mpi编译器。
module av mpi
在命令行中使用下面的命令加载相应的编译器环境,这边使用Intel2017和Intelmpi2017,注意相应的intel编译器和Intelmpi需要同时加载。
module purge
module load compiler/intel/2017.5.239
module load mpi/intelmpi/2017.4.239编译C语言代码。
mpiicc hello_Intelmpi.c -o hello_Intelmpi.out运行程序,需要使用提交任务的脚本,相应的脚本示例如下,命名为c_Intelmpi.slurm。
#!/bin/bash
#SBATCH -J hello_world_Intelmpi # 作业的名称 可根据需要自行命名
#SBATCH -p xahcnormal # 在指定分区中分配资源,根据所拥有的资源修改
#SBATCH -N 1 # 申请的节点数1个
#SBATCH --ntasks-per-node=4 # 每个节点运行4个任务,使用4个核心
module purge
module load compiler/intel/2017.5.239
module load mpi/intelmpi/2017.4.239 #加载编译环境
mpirun -np $SLURM_NTASKS ./hello_Intelmpi.out提交任务。
sbatch c_Intelmpi.slurm查看结果。
cat slurm-27524196.out
如果需要编译C++、Frortran等源码,编译方式是类似的,只是编译器的名称不一样而已。
Anaconda/miniconda是一个开源的python和R语言的发行版本,提供了一个方便的环境管理工具,主要用于数据科学、机器学习和科学计算。

chmod +x Miniconda3-py310_24.5.0-0-Linux-x86_64.sh #可以替换成自己上传的文件
bash Miniconda3-py310_24.5.0-0-Linux-x86_64.sh -b -f -p ~/miniconda3 #可以替换成自己上传的文件
source ~/miniconda3/bin/activate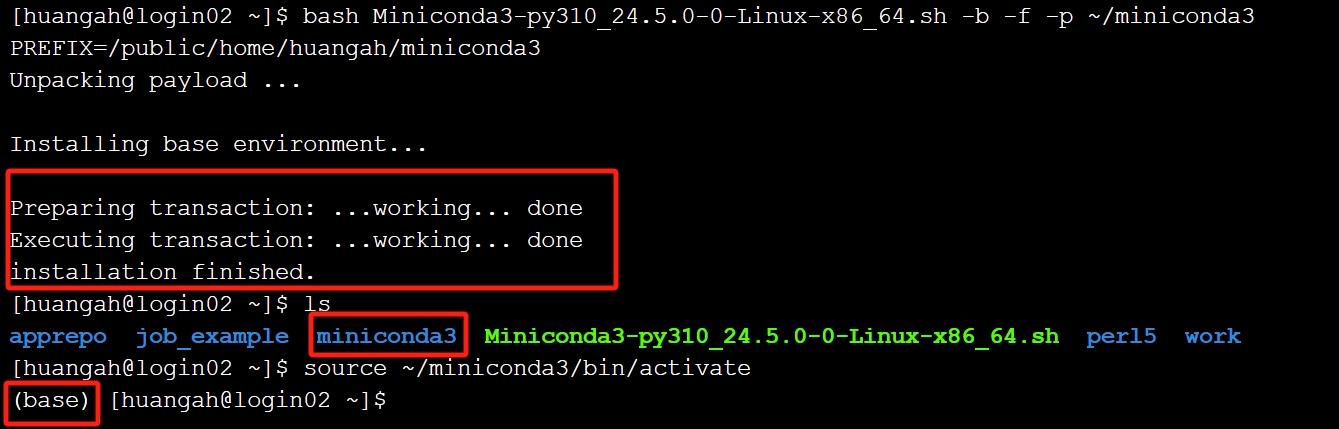
conda create -n py3.10 python=3.10 -y #创建名字为py3.10的环境,该环境中的python版本为3.10
conda activate py3.10
pip install numpy scipy matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple
准备好python源码如下命名为hello.py
import numpy as np
import scipy
import matplotlib.pyplot as plt
a = np.array([5, 2, 0])
print(f"hello scnet: {a}")运行程序,需要使用提交任务的脚本,相应的脚本示例如下,命名为python.slurm。
#!/bin/bash
#SBATCH -J hello_python # 作业的名称 可根据需要自行命名
#SBATCH -p xahcnormal # 在指定分区中分配资源,根据所拥有的资源修改
#SBATCH -N 1 # 申请的节点数1个
#SBATCH --ntasks-per-node=4 # 每个节点运行4个任务,使用4个核心
source ~/miniconda3/bin/activate py3.10 #激活python环境
python hello.py提交任务。
sbatch python.slurm查看结果。
cat slurm-11314770.out