高性能计算服务
>
>
GROMACS是一款广泛使用的分子动力学(MD)模拟软件,主要用于模拟生物大分子(如蛋白质、核酸和脂质等)的运动和相互作用,其核心功能之一是 mdrun,用于执行分子动力学模拟。
在SCNte最佳实践系列第9期,我们介绍了在超算互联网使用GROMACS软件,从原始的PDB结构文件开始,经过一系列系统构建、文件转化等步骤,最终执行mdrun进行生物分子模拟的过程。本文我们将继续研究并探讨如何提升GROMACS分子动力学模拟的并行计算性能。
在使用GROMACS进行生物分子模拟前,准备工作涉及多个方面,包括软件安装、环境配置、测试算例准备等。
精确配置是编译GROMACS时提升性能的关键因素之一,其中,选择合适的 SIMD(单指令多数据)指令集至关重要。通过使用 SIMD 指令,GROMACS 能在同一时间处理多个数据点,显著提升非键合和键合力计算、PME(Particle-Mesh Ewald)及邻居搜索的性能。
超算互联网提供GROMACS各个主要版本的已适配编译软件,科研人员能够跳过繁琐的编译过程,极大地提升科研效率和成果产出。
本次实验,我们使用超算互联网v2024.1版本软件,编译采用gcc 9.3.0和intelmpi2017,链接了专为高性能计算设计的MKL数学库,同时开启avx2 SIMD指令级并行和OpenMP支持,能够充分利用硬件的加速能力。
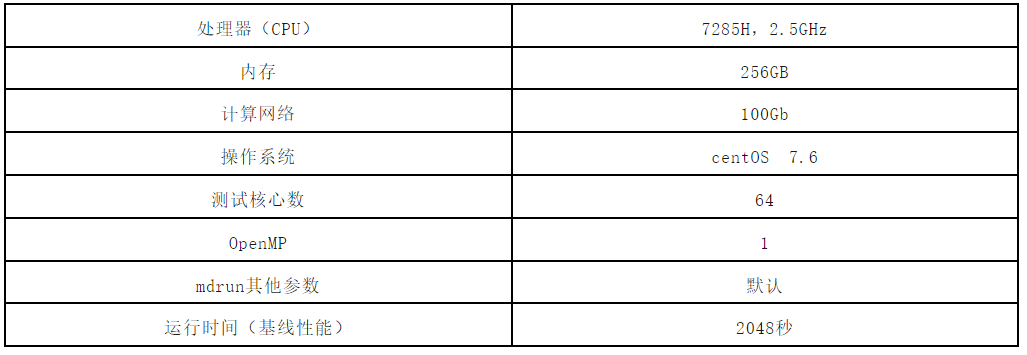
实验使用的算例为含有三百万个原子的蛋白质系统,使用了高精度的 PME 方法来处理长程库仑相互作用,并采用了 Berendsen 耦合方法来维持恒温恒压条件,模拟总步数为10000步。我们将该算例的输入文件命名为3M.tpr,并基于下述测试条件,得到基线性能,后续所有的讨论和优化都将基于该基线进行。
GROMACS支持通过MPI和OpenMP进行并行计算,这两种并行机制能够充分利用现代计算机的多核和多处理器特性,提高模拟的效率和性能。
具体而言,MPI主要用于在分布式内存架构中并行计算,这意味着每个进程拥有自己的内存空间,进程之间通过消息传递进行通信。
OpenMP则用于共享内存系统并行计算,即在同一个计算节点的多个核心之间并行执行任务,使得多个线程共享同一个内存空间,从而提高数据访问的效率。特别是在处理大量数据或密集计算任务时,OpenMP能显著提高程序的运行速度,且允许程序员根据硬件的可用核心数动态调整并行度,从而在不同平台上轻松实现性能优化。但是,使用OpenMP并行也可能遇到一些瓶颈,例如数据竞争、非平衡负载和过多的线程同步开销,这可能会影响整体性能。
MPI进程数量和OpenMP线程数量的设置遵循Ncores = NMPI × Nomp原则。接下来,我们将测试在保持所用核心数不变的前提下,如何设置进程/线程数量,能够获得最佳的运行性能。
在总核心数为64的前提下,我们分别测试OpenMP设置为2、4、8时的mdrun性能。OpenMP线程的数量可以通过mdrun的参数“-ntomp”来设置,运行命令可参考如下,表示使用32进程、2个OpenMP线程运行mdrun,输入文件为3M.tpr。
mpirun -np 32 gmx_mpi mdrun -ntomp 2 -v -s 3M.tpr具体配置和性能如下图所示。
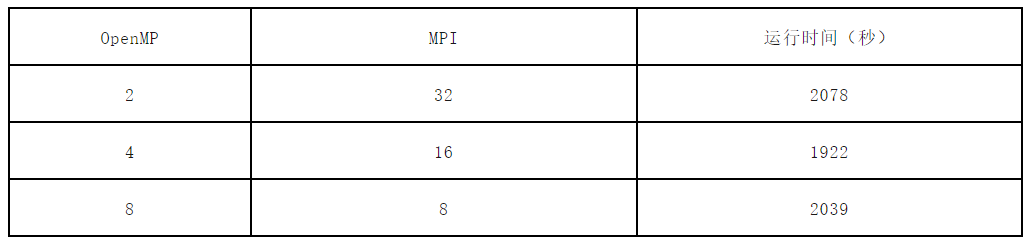
实验表明,总核心数为64的条件下,测试算例在使用16进程,4线程的线程/进程配比时,能够获得最佳的性能,运行时间可减少至1922秒,相较于基线(OpenMP=1)的2048秒,性能提升比例为(2048 - 1922)/ 2048 × 100% ≈ 6.15%。
这一提升表明在使用OpenMP进行并行计算时,系统在多线程处理上的效率得到了改善,多线程并行计算在一定程度上对于特定任务和数据集是有效的,通过引入OpenMP多线程并行处理,确实能够实现一定程度的性能优化。
在GROMACS中,域分解(Domain Decomposition, DD)算法和PME(Particle-Mesh Ewald)算法是实现高效并行计算和精确长范围相互作用的重要工具。
我们首先探讨PME的设置对GROMACS性能的影响。
PME算法是一种在分子动力学模拟中用于处理长程非键合相互作用的方法,尤其是长程库仑相互作用。该算法利用Ewald求和的框架,将长程相互作用分解为真实空间和傅里叶空间的计算,前者处理短程相互作用,后者在网格上进行长程相互作用的求和。这样的分解方法不仅提高了精度,同时也极大地降低了计算开销,使得模拟能够在合理的时间内完成。
但在大规模并行计算中,随着计算节点数量的增加,PME的全局通信和计算等待时间可能导致并行效率的降低,因此负载均衡和参数调优是优化性能的关键。
GROMACS的mdrun程序在运行结束后会输出关于负载均衡的性能分析报告,您可通过运行输出日志或者md.log文件查看,对分析程序的性能瓶颈有很好的指导意义。下面是基线环境下的性能统计。
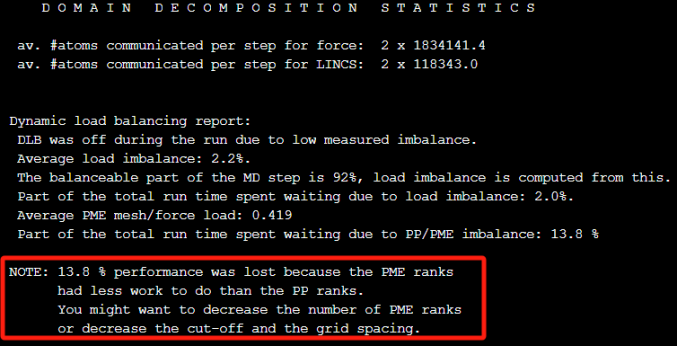
分析指出,由于PME 与 PP(粒子-粒子)之间的工作量不匹配,有13.8%的性能损失了,建议减少PME的进程数。在GROMACS中,当PME与区域分解一起使用时, 可以分配独立的进程只进行PME网格计算,PME进程数可由选项“-npme”设定, mdrun通常会猜测一个PME的rank数,我们也可以在md.log中找到相应的进程配置信息。
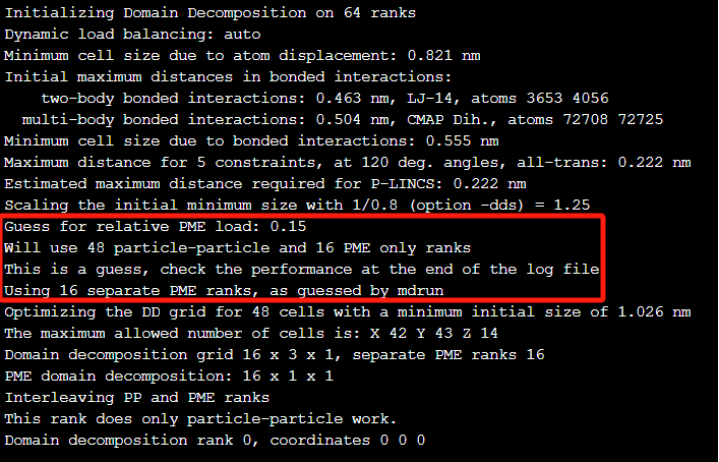
如上图日志信息显示,程序在运行在64核心时,猜测了使用16核心单独计算PME。结合前面基线结果的性能瓶颈分析,我们可以通过修改指定“-npme”参数,减少PME rank数来提高性能,使用的运行命令参考如下:
mpirun -np 64 gmx_mpi mdrun -ntomp 1 -v -s 3M.tpr -npme 8本文我们测试了-npme等于8和10的情况,结果如下表所示。由于mdrun还提供了一个“-ntomp_pme”参数,用于指定pme的线程数,这里我们也做了对比实验。

可以看到指定pme进程数小于16时,确实有明显的性能提升,npme=10时,性能相较于基线,提升了约9.46%,而当npme=8时,性能提升了约12.5%。因此,通过分析日志文件,手动设置PME进程数,对mdrun的性能提升也会有很大的帮助。再来分析下npme等于8时,mdrun的日志文件。
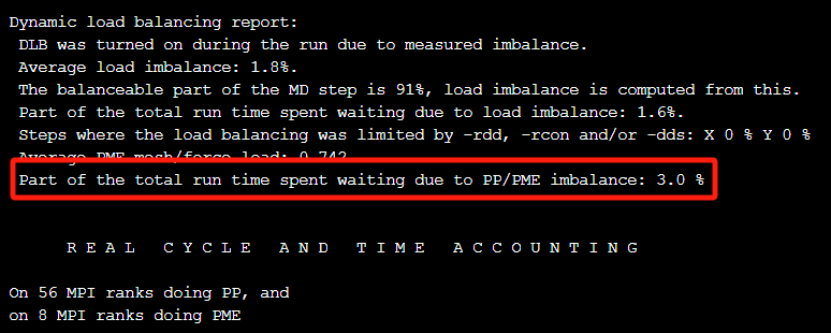
通过日志我们可以看到,PP/PME的负载不均衡从基线的13.8%降到了当前的3%,而且不再提示需要降低PME的rank数量。
上一节提到,域分解(DD)和PME(Particle-mesh Ewald)是gromacs中两个非常重要的算法,影响GROMACS中的并行化任务分配。
这节我们讨论mdrun中的哪些参数的调整可以影响域分解。
域分解的主要目标在于充分利用现代计算机的多核和多处理器架构,该算法将整个计算域划分为多个小域,每个小域内的粒子可以在保持空间局部性的情况下进行相互作用的计算。每个领域由一个MPI进程负责,从而能够并行处理不同领域内的粒子相互作用。这种划分不仅保持了计算的局部性,还避免了全局数据的频繁访问,从而降低了因数据传输造成的延迟。
尽管DD算法在提高计算效率方面具有显著优势,但它也伴随着一些性能影响。首先,域之间的边界处理和信息交流需要一定的同步和通信开销,尤其是在区域规模不均衡时,部分区域可能会成为计算的瓶颈。此外,在使用DD算法时,线程间的负载均衡显得尤为重要。如果某些区域的任务量过重,而其他区域则相对较轻,可能会导致处理器在等待计算任务时空闲,从而降低整体的计算效率。因此,合理的域划分和负载均衡策略是优化DD性能的关键。
在 GROMACS 中,mdrun 命令有多个参数可以用来控制领域分解算法。以下是一些常用的与域分解相关的参数及其作用。

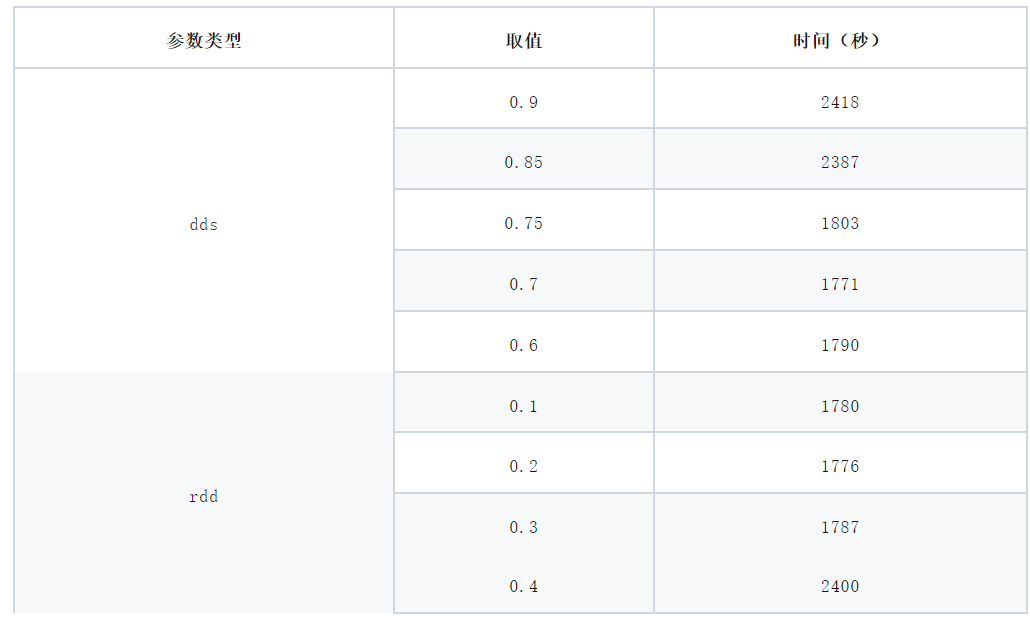
上述参数有可能影响域分解算法的工作负载或者整个mdrun的模拟准确性。结合上一节我们优化PME后的性能输出,报告中提到在负载平衡过程中,与选项 -rdd(与距离有关的选择)、-rcon(约束连接的选择)或 -dds(动态负载平衡的单元格缩放)有关的限制步骤比例均为 0%。这表示这些设置没有导致负载平衡的限制,即这些参数没有影响其有效性。
我们这里也通过尝调整dds和rdd参数,观察他们对性能带来的影响。下表展示了dds和rdd不同参数配置对mdrun整体性能的影响。
本文通过对算法和参数的分析,结合实验研究探讨了如何提升GROMACS mdrun命令的并行计算性能。我们分析了多级并行化策略,包括MPI和OpenMP的结合使用;结合性能分析报告,讨论了PME计算的核心数设置对性能的影响,并展示了如何通过调整 -npme 参数来达到负载均衡,减少计算瓶颈;最后详细介绍了域分解(DD)算法中的参数对区域分解的重要影响。
参考资料: