高性能计算服务
>
>
LAMMPS 的开发始于 20 世纪 90 年代中期,由美国能源部的两个实验室(桑迪亚国家实验室和劳伦斯利弗莫尔国家实验室)和三家公司(Cray、杜邦和百时美施贵宝)合作进行,其目标是创建一个高效利用空间并行性算法的MD(分子动力学)代码,并能充分利用当时拥有的 100 到 1000 个处理器(内核)大型超级计算机进行材料或生物分子模拟,LAMMPS在设计之初便使用 MPI(消息传递接口)进行分布式内存并行计算,以提高其在高性能计算环境中的效率。
最初,LAMMPS是用Fortran语言编写,随后用C++进行重写并于2004年开源,这一决策极大地促进了其在全球范围内的采用和进一步开发。开源模型允许研究人员和开发者自由地访问、修改和分享代码,从而加速了软件的改进和新功能的集成。随着时间的推移,LAMMPS已经成为分子动力学模拟领域最受欢迎和最强大的工具之一,被广泛应用于材料科学、化学、生物学和物理学的研究中。
LAMMPS能够如此受欢迎的主要原因有三点:
编程语言的灵活性和扩展性:LAMMPS所采用的C++语言特性让有不同编码背景的研究人员能够很容易地访问、理解和修改源代码。这种灵活性允许不同的开发者针对不同材料的模型丰富LAMMPS的势函数种类,从而完善软件生态;
跨平台兼容性:LAMMPS可以在不同平台上运行,不受特定环境的限制,这种跨平台能力为用户提供极大的便利;
开放的可定制性:LAMMPS的重构以简单易懂为目的,允许用户轻松地通过添加或修改代码来控制模拟细节,以及这种开放的可定制性允许有创造力的用户跳出传统的分子动力学模拟框架,实现个性化的模拟策略和算法。
现在的LAMMPS既可以对材料科学的高熵合金、聚合物网络等材料进行行为性质研究,又可以对生物医学领域的蛋白质和能源技术领域的锂电池进行仿真模拟。 但是LAMMPS模拟过程中仍有很多让人困扰的问题,例如软件更新频繁导致编译配置的复杂性以及大体量模型的计算效率不尽如人意。然而,这些问题也并不是全然无解。文本,我们浅析应对策略,为您的lammps之旅铺平道路。
LAMMPS因为简单易懂的代码结构以及极高的可扩展性使得版本迭代速度快,而每次迭代都要重新编译软件才能够正常使用,这就让很多研究人员为了避免在编译软件上浪费时间,而始终使用固定的几个版本进行研究。这样做可能存在几个问题:
关于功能受限,这是因为LAMMPS每4-8周的更新往往会添加一些新的模块和特性,如果只使用固定的版本便与这些新的功能无缘了。
在理论上,使用旧版本的LAMMPS并不会直接导致计算误差,因为LAMMPS的每个版本都是经过严格测试,已经确保了其计算的准确性。然而,新版本对已知问题的修复或者算法的更新,可能会间接影响到计算结果的精度。如果你发现你的计算结果与预期有较大的偏差,或者你的计算结果与最新文献的结果有较大的差异,那么更新到最新版本的LAMMPS可能会对你的研究有所帮助。同时算法的更新不仅提高了软件的精度,也会对计算效率有一定的影响。
目前,超算互联网提供LAMMPS各个主要版本和常用第三方库(如deepmd,nequip和vcsgc等)的预先适配编译软件,科研人员能够跳过繁琐的编译过程,将更多时间和精力投入到科学研究中,极大地提升科研效率和成果产出。
并行和异构加速总有一种适合你。
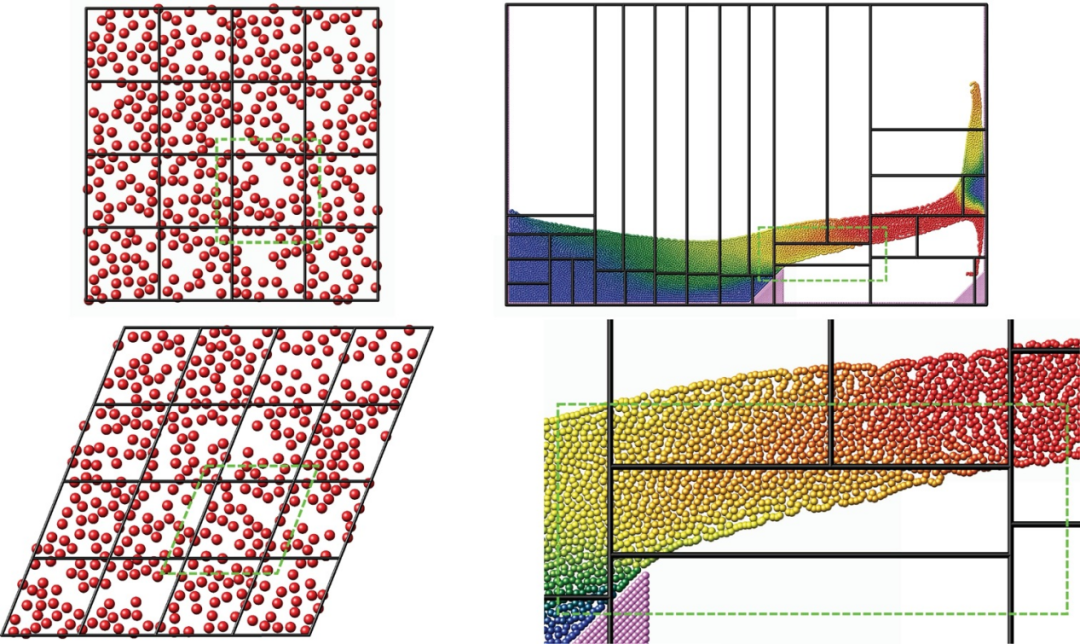
正如LAMMPS在开发之初的目的是在大型超级计算机上进行材料或生物分子模拟,在不断更新迭代过程中LAMMPS也始终贯彻初心。其采用的分布式内存并行策略为基本空间分解策略,简单来说就是仿真框在空间上被分割为填满仿真框的非重叠子系统,每个子域分配一个唯一的 MPI rank 或进程。针对密度不均匀的模型,LAMMPS引入了动态负载平衡算法(RCB),使得每个子域中负责的粒子数量相等。
但是这样仍然逃避不了一个问题,就是整体仿真速度受限于速度最慢的处理器,即计算负荷最大的处理器。理论上,增加处理器数量,减轻处理器负担便能有效解决大模型计算速度缓慢的问题。
无脑增加计算使用的核心数并不是一个明智的选择,因为MPI之间的通信也需要消耗时间,以4000原子LJ系统的时间分解示例,如下图的输出结果表所示。表中的最后一列说明了总循环时间中在该类别上花费的百分比,Pair 的部分(粒子间的力计算)占总时间的52.44%,而Comm 也就是MPI之间通信占了总时间的 36.20%,进程过多导致通信时间过长已经成为了程序计算的一大问题,这时就需要另寻他法来优化软件的计算方式了,比如最常用的方式就是异构加速。
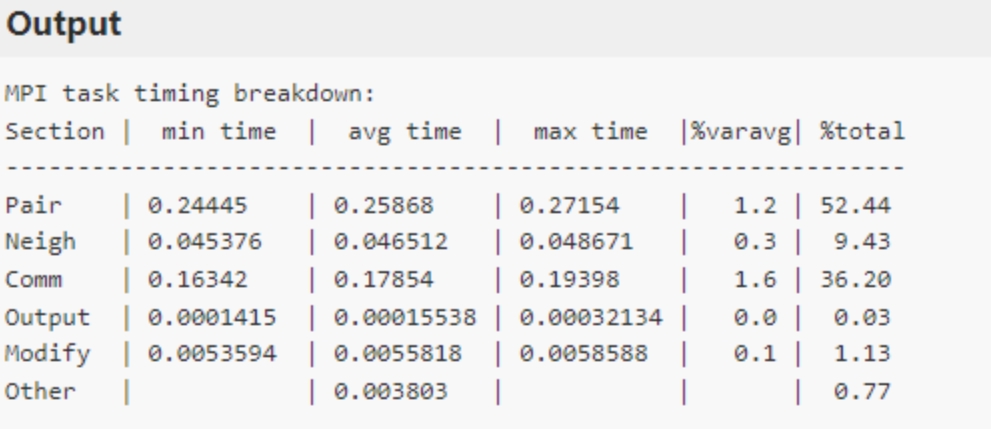
以上测试环境结果来自超算互联网lammps stable_2Aug2023_update3版本。
异构加速的核心理念在于重新分配计算任务,将原本都在CPU上进行的计算任务部分转移到GPU上进行。在这种架构下,CPU通常负责执行需要复杂逻辑和流程控制的任务,而GPU则并行处理大量数据计算。
异构加速的主要优点是可以提高性能和能效,通过将任务分配给最适合执行的处理器,更快地完成计算,同时使用更少的资源。这对于需要大量计算的应用(如深度学习、科学模拟等)来说具有非常重要的意义,可以说异构加速已经逐渐成为未来科学计算模拟必然的趋势。
在实际应用中,使用GPU加速会遇到以下两个问题:
没有足够的GPU卡来进行并行计算,单张GPU或2张GPU卡的加速效果并没有太大的提升,但只是为了1~2次的模拟计算花费资金去购入大量GPU也并不划算;
LAMMPS附带的GPU包计算的编译非常繁琐,经常会遇到CUDA 版本和 NVIDIA 驱动版本不一致等问题。当前,超算互联网依托于国产异构加速卡推出了dtk版本的LAMMPS,适配了官方支持的所有GPU包和KOKKOS包以及deepmd等第三方的加速,方便 用户不必再受异构加速资源不足等问题的困扰。 国产异构加速到了什么水平?让我们用事实说话,下图为异构加速卡计算与CPU计算性能对比图(算例为官方Lennard-Jones liquid benchmark)。
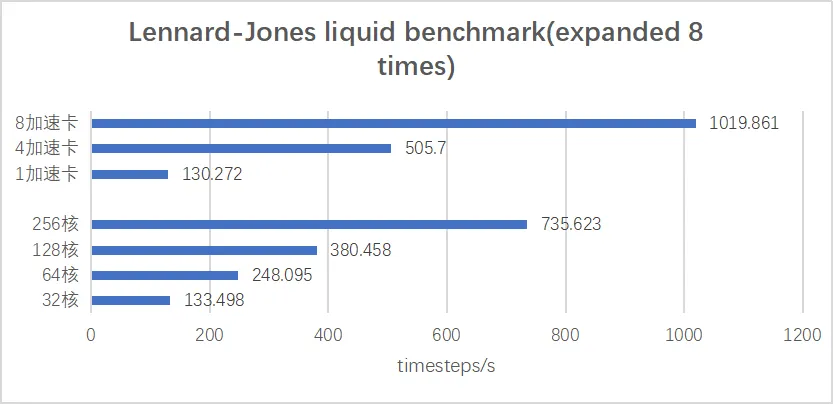
以上测试环境结果来自超算互联网lammps 23Jun2022加速版。 可以看到,通过算例比较,LAMMPS国产异构加速相比CPU有约2~4倍的加速比效果,并且在模型一定规模内卡数越多加速效果越好。相比CPU采用多核并行计算大模型,使用异构加速计算效果更好且整体而言更具性价比,从各方面而言,国产异构加速都是一个不错的选择。