高性能计算服务
>
最佳实践
>
Quantum ESPRESSO v7.0水分子算例的运行优化指南
在材料科学与物理化学领域,Quantum ESPRESSO(QE)作为一款基于密度泛函理论(DFT)的高性能计算软件,被广泛应用于电子结构分析与材料性质预测。
上篇我们介绍了QE 自洽计算(SCF)的实践指南,本篇将以QE官网water算例为例,带来如何在超算互联网使用Quantum ESPRESSO v7.0版本进行水分子自洽场计算的运行优化建议,包括基准测试与性能分析、QE并行策略分析及water算例运行优化等,帮助科研人员更高效地在超算互联网运行QE,推动材料科学领域的研究进展。(该算例可在超算互联网“quantum_espresso v7.0 示例版本“商品中的case目录中下载使用。)
water算例使用PBE0泛函计算64个水分子,从而获得电子结构和能量信息。在这个计算中,64个水分子被放置在一个简单的立方晶胞中,晶格常数为23.521230407,计算的目标是通过求解Kohn-Sham方程来获得水分子的电子结构和能量,计算中使用的平面波截断能为80,波函数将用一组平面波来展开。为了加速计算,采用了一些优化策略,例如,使用了混合模式和混合参数来加速自洽场过程的收敛,以及使用了对角化方法和高精度设置来提高对角化的准确性。
算例的主要参数见下图1。
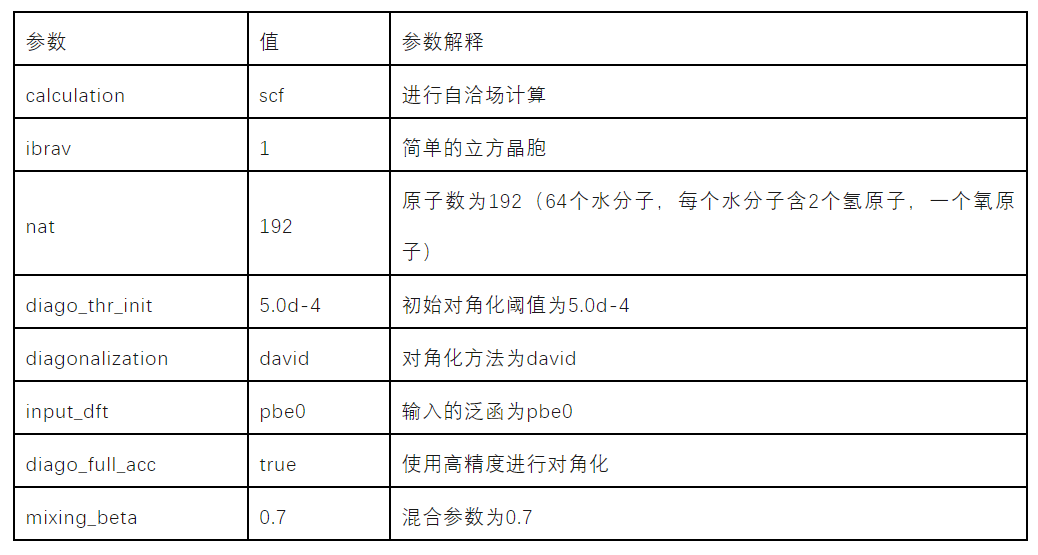
本次实践使用超算互联网quantum espresso 官方7.0版本的预编译可执行程序,程序编译采用intelmpi 2021,链接了intel的MKL(Math Kernel Library)数学库,没有开启openmp选项。主要测试的功能为pw.x,使用slurm调度器运行程序。
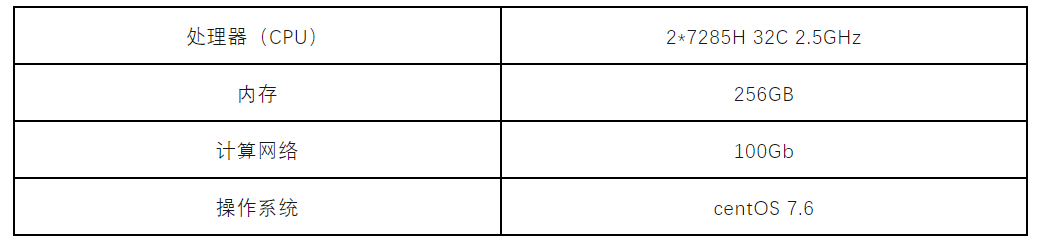
本实验运行在超算互联网,使用单节点64核心。节点的主要软硬件配置信息如下图2所示。
使用slurm调度器运行pw.x,测试water算例,测试脚本如下:
#!/bin/bash
#SBATCH -J water
#SBATCH -N 1
#SBATCH --ntasks-per-node=64
#SBATCH -p xahcexclu01
module purge
source ~/apprepo/qe/7.0-intel2021/scripts/env.sh
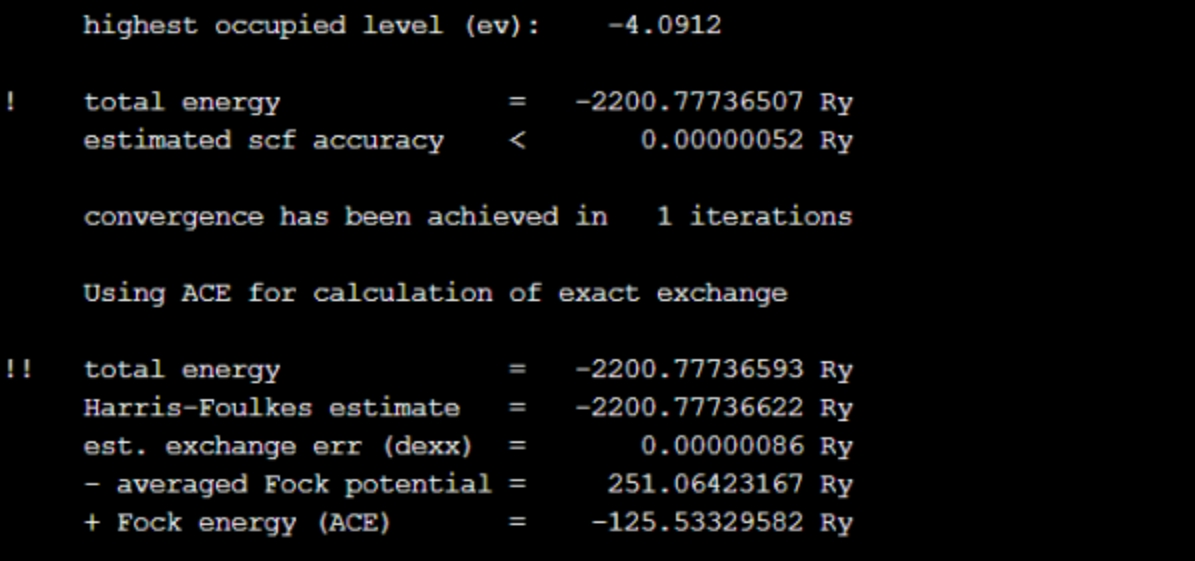
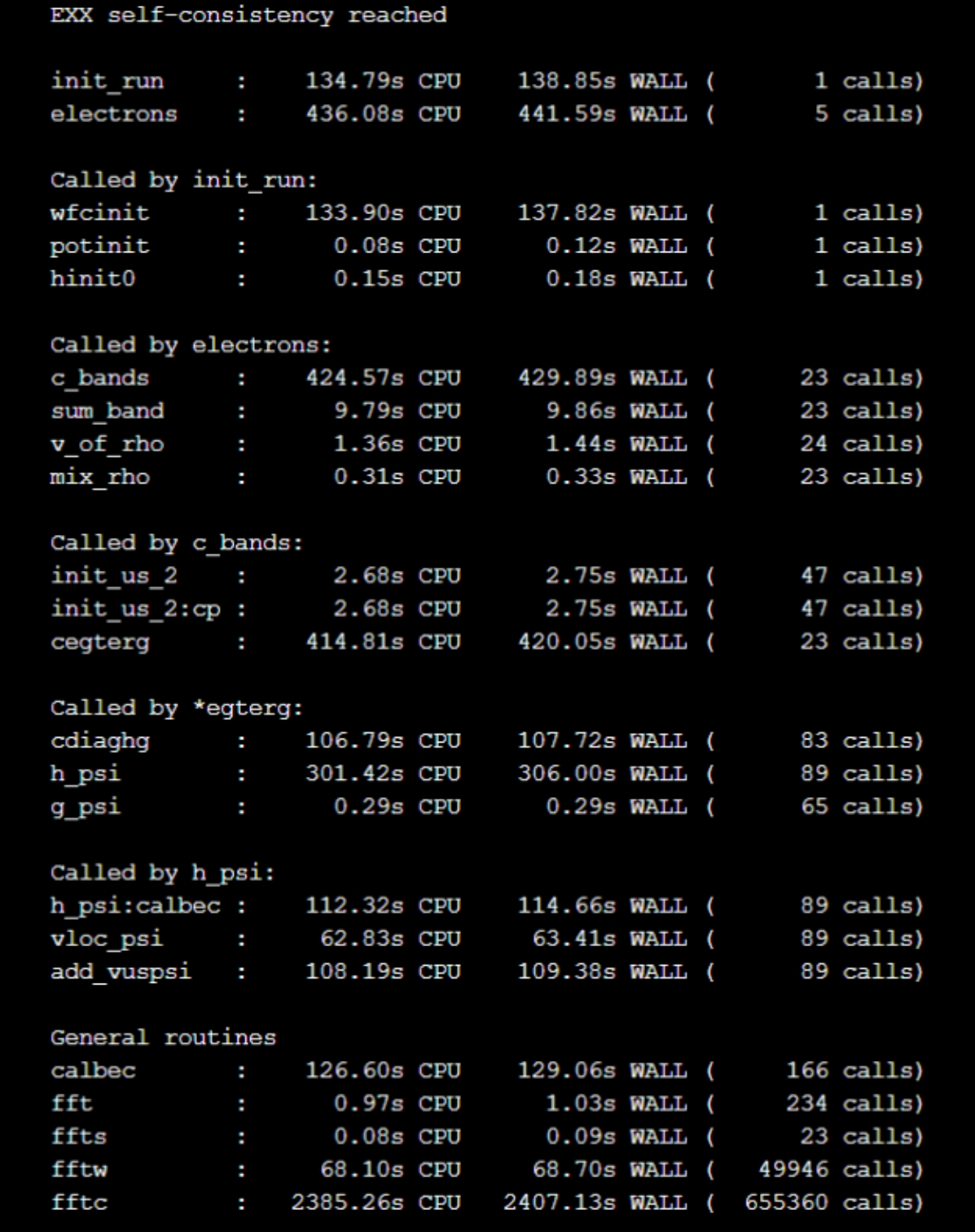
mpirun -np 64 pw.x -in pw.in提交作业后,软件运行结果如下图3和图4所示,图3为精度结果展示,图4为运行时间。

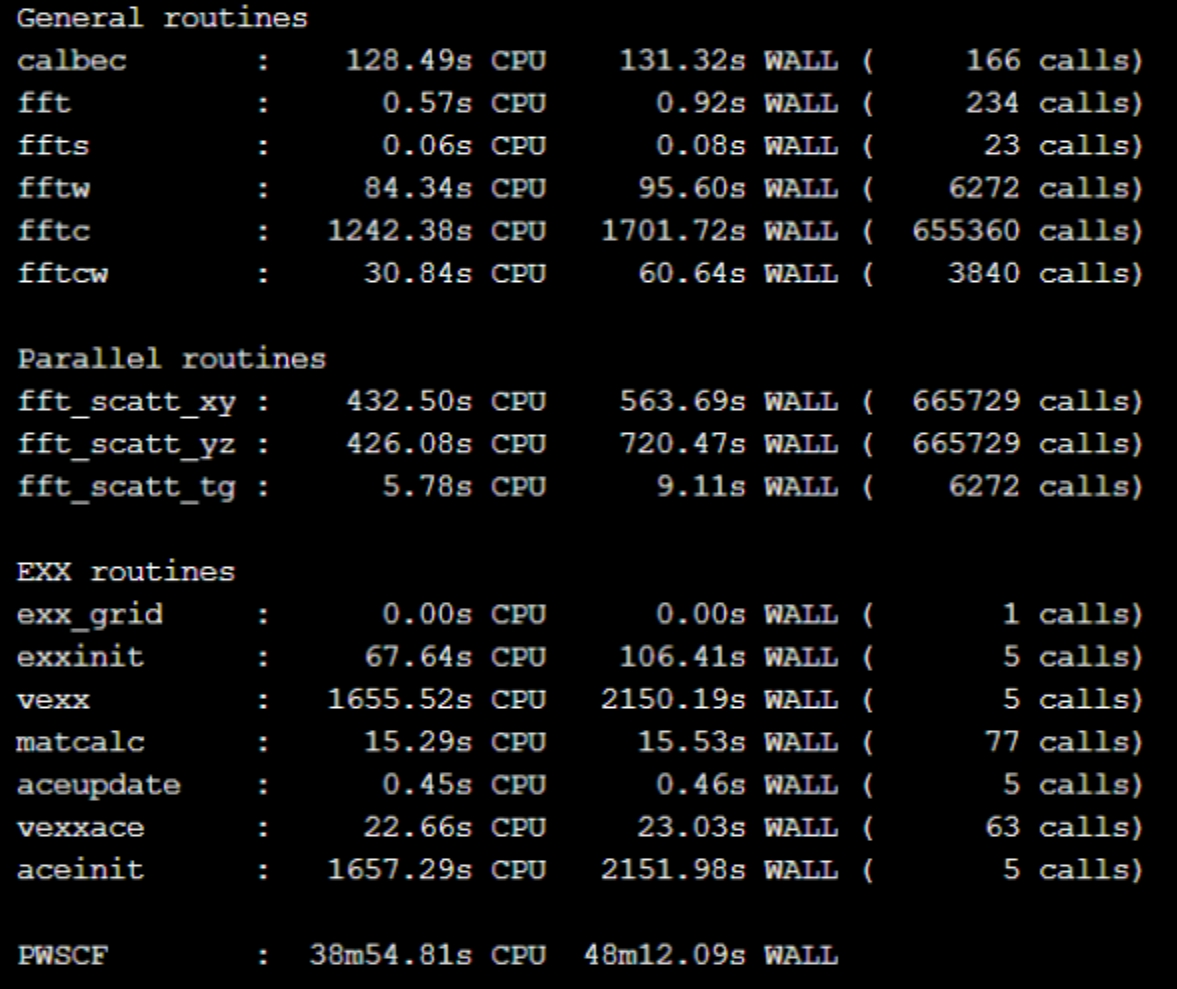
使用64核心运行water算例,在现有的编译条件下,需要近1个小时时间完成计算。图5展示了软件运行耗时统计,从统计来看,在整个计算过程中,最耗时的部分在fftc的计算上,耗时40分钟左右。
同时,为了更好地分析算例运行特征和热点,我们抓取了运行时的perf数据,perf热点抓取命令和打开perf数据的命令如下:
perf record –p pid #pid为运行时某个进程号
pref report –i perf.data #perf.data为抓取的perf文件下图为运行过程的TOP热点统计图。

从热点图中可以看出,通信、数学库计算、交换相关势计算、FFT计算和内存拷贝是整个运行过程的主要热点瓶颈。数学库的计算由于调用了MKL数学库,暂时不考虑优化。内存拷贝使用了intel的sse2指令,在机器支持AVX(avx、avx2、avx512)指令时,可以尝试在编译时使用avx指令,或者手动在代码中的memcpy函数,改为avx的intrinsics函数调用。通信和FFT计算可以结合QE并行策略做针对性的调优。
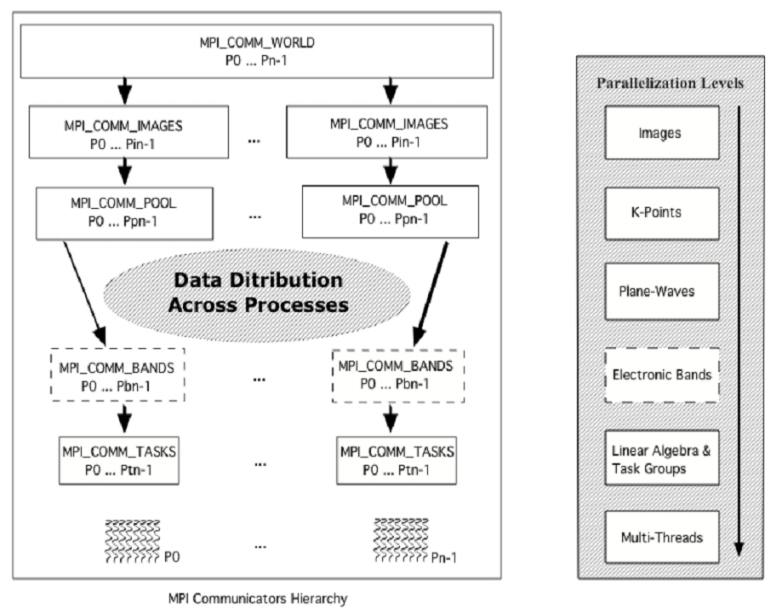
在Quantum ESPRESSO软件中,设置了多级别的并行策略,由于本文涉及的是平面波自洽场(PWscf)计算,因此从PWscf和优化FFT计算的角度简单分析其中一些并行级别,具体可参考QE官方的user guide。
1、k-point(Pool)并行:每个image可以分成“池”,每个池处理一组k点,该参数的设置必须是K点总数的除数。
2、linear-algebra并行化:为了在迭代对角化(PWscf)或正交化(CP)中分配和并行化矩阵对角化和矩阵乘法运算,引入了一个线性代数处理器组(ndiag)作为平面波处理器组的子集。ndiag等于m的平方,m是一个整数,使得m的平方不大于平面波处理器的数量(PW)。
3、task group并行化:每个平面波处理器组被分成Nfft和Ntask任务组,其中Nfft×Ntask=Npw。这用于扩展FFT并行化的可伸缩性。
图中描述了QE软件中的并行级别,可供参考。
基于上述并行级别,QE提供了一些列参数,支持用户自行选择和设置并行策略,从而分配不同的核心数给到不同的计算任务,部分参数和对应的并行级别如下图所示。
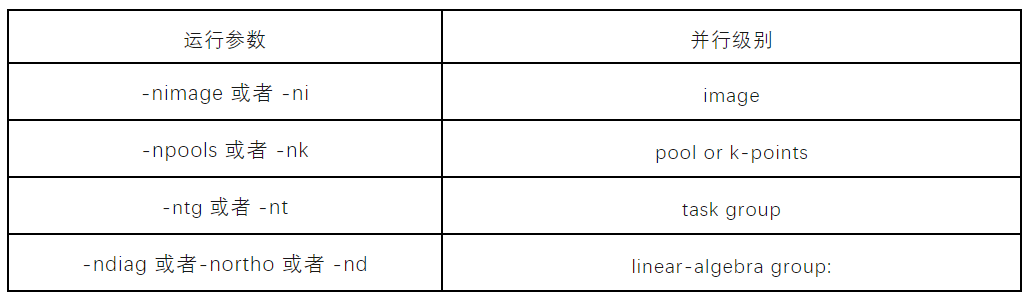
例如下述命令表示:使用4096个核心运行程序,被分配到8个image,2个pool,那么PW的处理核心数则为4096/8/2=256,设置ntg=8,那么Nfft=256/8=32,对角化计算使用144个核心。
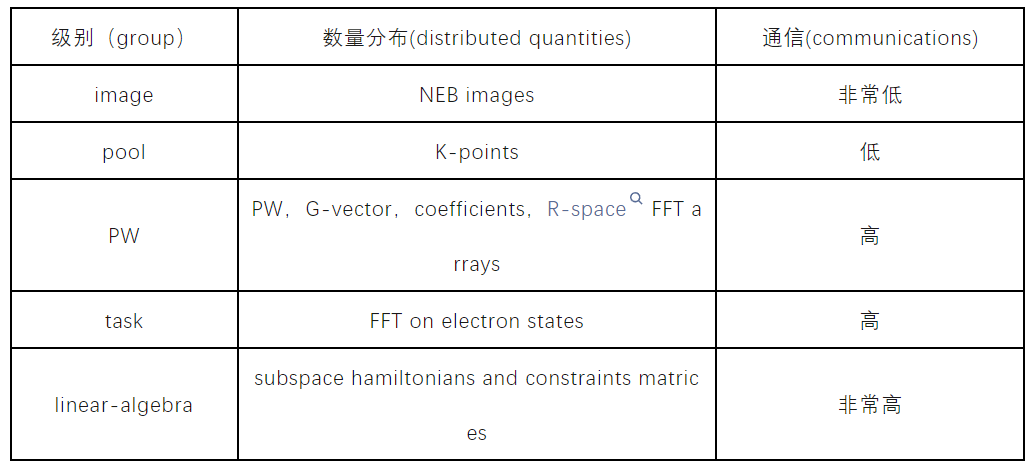
mpirun-np 4096 pw.x-nimage 8-npool 2-ntg 8-ndiag 144 ...从热点角度看,water算例在前述配置下的运行效率瓶颈在于通信和FFT计算上。从QE并行策略角度分析,image并行之间的通信非常小,而linear-algebra之间则需要非常频繁的通信,可以酌情参考下图的描述粗略判断。
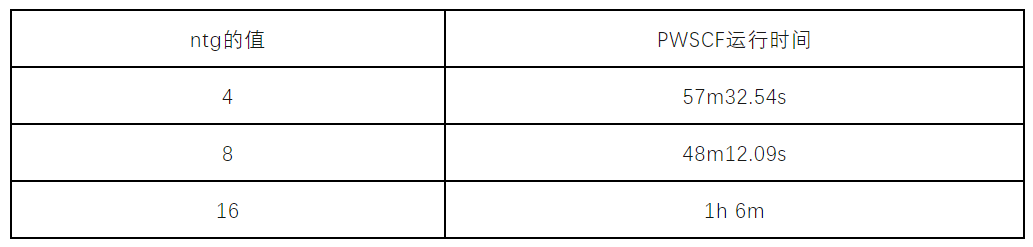
结合热点和并行策略的分析,在water算例本身image、k-points等支持的设置条件下,尝试对ntg(task group)参数做对比实验。因为ntg参数可以直接影响到用于处理FFT计算的核心数,考虑到其通信量高,所以兼顾计算和通信,测试ntg的参数设置为4、8、16这三种情况下的运行效率。软件运行命令如下所示:
mpirun pw.x -pd ture -nk 1 -ni 1 -ntg 4 -in pw.in测试结果下图所示。结果表明,ntg参数的设置对整体的运行效率有一定的影响,当ntg=8时,相较于基线性能有20%的性能提升,效果十分明显。而设置为16时,性能下降,查看耗时统计,发现fft的计算时间反而上升,说明此时的fft分配到的计算资源偏低,而过多的分配计算核心给fft也不一定能获得更优的性能,可能会导致FFT内部的通信代价太高,从而影响全局计算。
下图是ntg参数设置为8时的结果输出,表明精度与基线测试的结果一致,该参数的设置对QE的计算精度无影响。
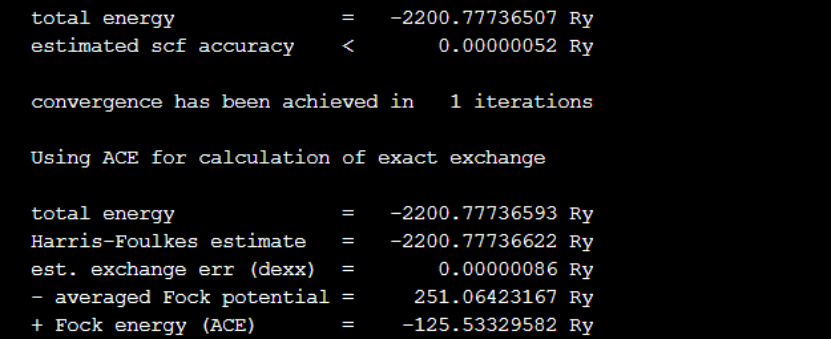
下图中展示了计算过程中各关键步骤的耗时以及计算的总用时,从统计结果看,FFT的计算速度得到了明显的提升,总时间也提升了20%。另外,由于软件包的编译并没有开启-fopenmp选项,所以本次实验并没有体现OpenMP的设置对性能的影响。
由于QE软件存在多级并行模式,需要结合具体的算例特征和运行特征,分析运行瓶颈,针对性地做出合理的参数设置,本篇实践为科研人员不仅提供了在超算互联网使用Quantum ESPRESSO v7.0 进行水分子PWScf计算的优化方案和建议,还为超算用户在超算互联网进行各类材料计算提供了有价值的案例参考。